[DataBase] MySQL 아키텍처(구조)
MySQL의 전체구조
MySQL 서버는 MySQL엔진과 스토리지 엔진으로 구분된다.
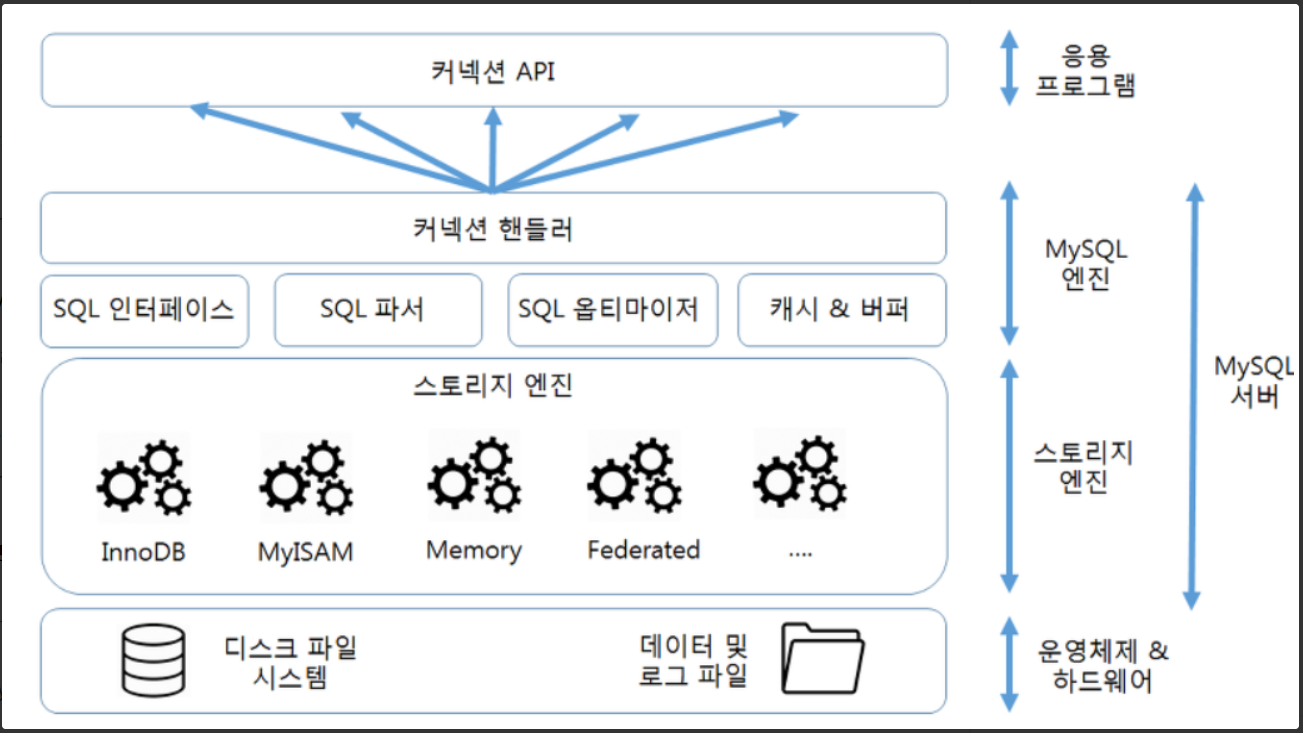
MySQL 엔진
-클라이언트로부터 접속 및 쿼리 요청을 처리하는 커넥션 핸들러,
SQL 파서 및 전처리기, 그리고 쿼리의 최적화를 위한 옵티마이저,
DBMS의 두뇌에 해당하는 처리를 수행한다.
스토리지 엔진(Storage engine)
-스토리지 엔진은 실제 데이터를 디스크 스토리지에 저장하거나 읽어오는 부분을 전담한다.
-MySQL 서버에서의 MySQL엔진은 1개, 스토리지 엔진은 여러개를 동시에 사용 가능하다.
ex)
CREATE TABLE test_table(컬럼명1 데이터타입, 컬럼명2 데이터타입) ENGINE=InnoDB;
처럼 스토리지 엔진을 지정하면, 테이블의 모든 작업은 해당 스토리지 엔진이 처리
-SHOW ENGINES; 명령어로 스토리지 엔진 확인 가능
핸들러API
-MySQL 엔진이 스토리지 엔진에게 쓰기 또는 읽기를 요청할 때 핸들러 API를 사용
-핸들러 API를 통해 얼마나 많은 데이터 작업이 있었는지를 명령어로 확인 가능
ex)
SHOW GLOBAL STATUS LIKE 'Handler%';
MySQL threading 구조
-MySQL 서버는 프로세스 기반이 아닌 스레드 기반 작동
-포그라운드(foreground) 스레드와 백그라운드(Background) 스레드로 구분
-포그라운드(foreground) 스레드:
1)최소 MySQL 서버에 접속된 클라리언트의 수만큼 존재하며, 클라이언트 사용자가 요청하는 쿼리 문장을 처리하는 한다.
2)사용자가 커넥션을 종료하면 해당 커넥션은 스레드 풀로 되돌아 간다.
3)스레드 풀에 일정 개수이상의 대기중인 스레드가 있으면 스레드 풀에 넣지 않고 스레드를 종료시켜서 일정 개수의 스레드 풀에 존재.
4)스레드의 개수를 일정하게 유지하게 만들어주는 parameter가 thread_cache_size이다
ex)
SHOW VARIABLES LIKE 'thread_cache_size';
-백그라운드(background) 스레드:
1)인서트 버퍼를 병합하는 스레드
2)로그를 디스크로 기록하는 스레드★(쓰기 스레드)
3)버퍼 풀의 데이터를 디스크에 기록하는 스레드★(쓰기 스레드)
4)데이터를 버퍼로 읽어들이는 스레드
5)잠금이나 데드락을 모니터링 하는 스레드
6)모든 스레드를 총괄하는 메인 스레드
ex)
SHOW VARIABLES LIKE 'innodb_%_io_threads';
-읽기/쓰기 스레드의 개수를 지정하는 파라미터는 innodb_read_io_threads/innodb_write_io_threads
innoDB 에서는 데이터를 읽는 작업은 주로 클라이언트 스레드에서 처리되기 때문에 읽기 스레드는 많이 설정할 필요가 없지만, 쓰기 스레드는 아주 많은 작업을 백그라운드로 처리하기 때문에 일반적인 내장 디스크를 사용할때는 2~4개 정도로 설정하고, DAS나 SAN과 같은 스토리지를 사용할때는 4개 이상으로 충분하게 설정해야한다.
InnoDB Storage Engine architecture
-InnoDB 스토리지 엔진은 MySQL에서 사용할 수 있는 스토리지 엔진 중에서 거의 유일하게 레코드 기반의 잠금을 제공,높은 동시성 처리가 가능하고 안정적이다.
-InnoDB Storage Engine의 특성
1)Primary key에 의한 clustering:
InnoDB의 모든 테이블은 기본적으로 PK 기준으로 클러스터링 되어 저장된다. 즉, PK 값의 순서대로 디스크에 저장되고 이로 인해 PK에 의한 range scan은 상당히 빨리 처리 된다.
2)잠금이 필요없는 일관된 읽기:
InnoDB storage engine은 MVCC라는 기술을 이용해 락을 걸지 않고 읽기 작업을 수행한다.
3)외래키 지원
4)자동 데드락 감지
5)자동화된 장애 복구
6)오라클의 아키텍처 적용:
InnoDB Storage Engine은 MVCC(multi version concurrency control) 기능이 제공된다는 것과 undo 데이터가 시스템 테이블 스페이스에 관리된다는 것 등에서 오라클 아키텍처와 유사한 부분이 많다.
InnoDB 버퍼 풀
-백그라운드 작업의 기반이 되는 메모리 공간이며 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간
-InnoDB 버퍼 풀은 아직 디스크에 기록되지 않은 변경된 데이터를 가지고 있는데 이를 더티페이지라고 함.
-더티페이지는 InnoDB에서 주기적으로 또는 어떤 조건이 되면 체크포인트 이벤트가 발생하는데, 이 때 write 스레드가 필요한 만큼의 더티페이지만 디스크로 기록.
-체크포인트가 발생한다고 해서 버퍼 풀의 모든 더티페이지를 디스크로 기록하지는 않는다.
-InnoDB의 버퍼 풀 크기는 innodb_buffer_pool_size로 설정, 일반적으로 장착된 물리 메모리의 50~80% 수준에서 설정
-undo log:
언두 영역은 UPDATE 문장이나 DELETE와 같은 문장으로 데이터를 변경했을 때 변경되기 전의 데이터를 보관하는 곳
ex)
UPDATE member SET name="이름" WHERE member_ID='1';
1)위의 문장이 실행되면 트랜잭션을 commit하지 않아도 실제 데이터 파일 내용은 "이름"으로 변경됨.
2)그리고 변경 전의 값이 "다른 이름" 이였다면 undo 영역에는 "다른이름" 이라는 값이 백업되는 것.
3)이 상태에서 사용자가 commit하게 될 경우 현재 상태가 그대로 유지되고, 롤백하게 되면 언두 영역의 백업된 데이터를 다시 데이터 파일로 복구한다.
Insert 버퍼
-Insert 되거나 UPDATE 될 때는 데이터 파일을 변경하는 작업뿐 아니라 해당 테이블에 포함된 인덱스를 업데이트 하는 작업도 필요.
-인덱스를 업데이트 하는 작업은 랜덤하게 디스크를 읽는 작업이 필요하므로 테이블에 인덱스가 많을 경우, 상당히 많은 자원을 소모하게 된다.
-InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행,
그렇지 않고 디스크로부터 읽어와서 업데이트 해야한다면 이를 즉시 실행하지 않고 임시공간에 저장하고
사용자에게 결과를 반환하는 형태로 성능을 향상,이 때 사용하는 임시 메모리 공간(=insert 버퍼)
#Redo 로그 및 로그 버퍼
-쿼리 문장으로 데이터를 변경하고 커밋하면 DBMS는 변경된 데이터의 내용을 데이터 파일로 기록한다.
-이러한 데이터 변경을 순차적으로 디스크에 기록하기 위한 로그파일을 가지고 있으며 이를 리두 로그라고한다.
-리두로그의 버퍼링에 사용되는 공간이 로그버퍼이다.
#MVCC(Multi Version Concurrency Control)
-InnoDB는 잠금을 사용하지 않는 일관된 읽기를 제공하기 위해 MVCC를 사용하고 MVCC는 언두 로그를 이용해 이 기능을 구현
출처:
idea-sketch.tistory.com/42?category=547413