[Spark Tuning] (spark on YARN)yarn container, spark core, executor 개수 Memory 용량 계산법 및 최적화
이번 포스트에는 Spark의 core, executor, memory 계산법 대해서 알아보겠습니다.
Core ? vCore? 헷갈릴 개념
- 요즘은 하이퍼스레딩이라 하여 1코어에 2개의 스레드를 지원하는 instance들이 많습니다.
- core든 vCore든 가상화의 차이만 있을 뿐 같은 코어입니다.
- 여기서 중요한건 코어당 스레드가 1이냐 2이냐 차이인데,
- 아래의 instance는 8코어이지만 vCPU(vCore,가상 논리 프로세서=스레드)는 16입니다.
*spark에 있어서 불리는 코어는 하이퍼스레딩은 지원하지 않으면 코어수 그대로겠지만, 지원한다면 vCPU인 가상 논리 프로세서의 수를 의미합니다.

vCPU: 코어 x 코어당 스레드, 논리프로세서라고도 불리며, 하나의 스레드
코어: 물리적인 CPU당 들어 있는 코어 개수
코어당 스레드: 1 or 2, 하이퍼 스레딩을 지원하는지 안하는지 차이에 따라 지원하면 2
1.Spark Job 실행 흐름 (executor 관점)
- Executor는 실질적으로 연산을 하는 프로세스이며 이를 기준으로 메모리 계층을 구성하고 병렬성 크기를 결정함
- 1개의 Worker 노드는 1개 이상의 Executor 프로세를를 동작함(worker 수 만큼 executor를 할당 하지않을 경우 자원의 낭비)
- Spark Job의 실행을 위해 보통 1개 이상의 Executor 프로세스가 실행됨
- 1개의 Executor는 하나의 JVM(Java Virtual Machine)을 가짐
- 각각의 Executor는 똑같은 개수의 Core와 똑같은 크기의 Memory(Heap)를 가짐
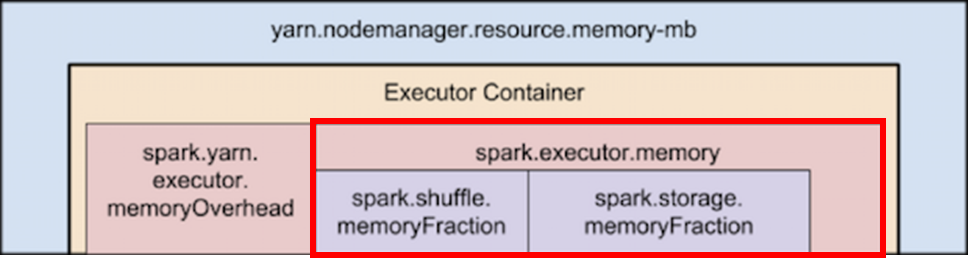
2. YARN과 Spark memory에 할당된 메모리(Executor Memory) 계층 구성
Spark 의 메모리 계층 구성과 각각 어디에 사용되는지를 알아야 이후에 YARN의 총 코어수와 메모리를 알 게 될 때 계산할 수 있다.

- yarn.nodemanager.resource.memory-mb:
1개의 노드에 있는 모든 Executor 컨테이너들이 사용하는 메모리 총합 - yarn.scheduler.maximum-allocation-mb(Executor Container):
1개의 컨테이너에 할당할 수 있는 최고치 메모리 양 - yarn.scheduler.minimum-allocation-mb(Executor Container):
1개의 컨테이너에 할당할 수 있는 최저치 메모리 양 - spark.yarn.executor.MemoryOverhead:
오버헤드를 위한 여유분 메모리 크기- Spark 2.2까지:
spark.yarn.executor.memoryOverhead - Spark 2.3부터:
spark.executor.memoryOverhead
(리소스 관리자로써 yarn만 사용되지 않기 때문에 2.3ver 부터는 yarn을 뺌)
- Spark 2.2까지:
- spark.executor.memory:
1개의 Executor가 사용하는 메모리 크기 - spark.memoryFraction:
Task 실행, 셔플, 조인, 정렬, 집계를 위한 데이터 저장 비율 - spark.storage.memoryFraction:
Cache, Broadcast, Accumulator를 위한 데이터 저장 비율
*Upper Limit 조건
yarn.nodemanager.resource.memory-mb > spark.executor.MemoryOverhead + spark.executor.memory
해당 식이 만족하지 않을 시 OOM에러가 발생
*YARN memory 및 코어 설정
YARN 의 메모리 및 코어를 설정할 때 실제 하나의 노드에서 사용 가능한 메모리와 코어수 보다는 낮게 설정을 해야하는데, 각 노드에 OS와 하둡 데몬을 돌릴 리소스가 필요하기 때문이다.
(cloudera와 같은 경우에는 OS를 위한 reserved된 자원은 20%정도라고 한다.)
https://docs.cloudera.com/documentation/enterprise/latest/topics/cdh_ig_yarn_tuning.html
(위의 링크에 따르면 os나 hadoop daemon에 사용되는 평균 리소스는 4GB~8GB정도)
- yarn.nodemanager.resource.cpu-vcores:
1개의 노드에 있는 모든 Executor 컨테이너들이 사용하는 코어 수 총합
ex) core node 메모리, 코어 설정
yarn.nodemanager.resource.memory-mb = (64-4) x 1024 = 61440
yarn.nodemanager.resource.cpu-vcores = (16-1) = 15
*AWS EMR의 경우 메모리는 줄여서 설정하지만 코어수 빼지 않고 그대로 설정
*memoryOverHead란
- java를 실행할 때는 -Xmx 설정으로 heap size를 지정한다. 즉, -Xmx2g라고 지정하는 경우 jvm에는 2GB의 heap이 할당된다. 하지만 top으로 해당 jvm의 메모리 사용량 (정확히는 resident memory, 또는 RSS)을 보면 2GB보다 더 많은 메모리를 사용하는 걸 볼 수 있다.
- 2GB 이외의 메모리는 off-heap이며 jvm에서 다양한 용도로 사용되는 영역
- Spark의 memoryOverhead 설정을 off-heap용 메모리 공간을 임의로 지정(그 양은 6~10%)
2-1. Spark의 executor memory 설정
spark submit 시 --executor-memory=메모리양 or spark.executor.memory를 통해 설정된다.
2-2.spark executor가 YARN으로부터 Memory를 할당받는 과정
1) --executor-memory=1g를 지정했다고 가정
2) Spark Driver는 yarn에게 executor용 memory를 요청하게 되는데 이때 요청되는 메모리는 (--executor-memory에 지정된 메몰 + overhead를 감안한 메모리)가 된다.
3) ‘overhead를 감안한 메모리’는 MIN(executorMemory * 0.1, 384MB)
4) --executor-memory=1g로 지정한 경우 executor가 yarn으로부터 할당받는 메모리는 1GB + 384MB
5) --executor-memory=5g가 된다면 이때는 5GB + 500MB를 할당
* --executor-memory=2g --conf + spark.executor.memoryOverhead=1g VS --executor-memory=3g
두 가지 방법 모두 3GB를 사용하는 것처럼 보여지나 off-heap 사용량 관점에서는 다름
1) --executor-memory=2g + --conf spark.executor.memoryOverhead=1g
- on-heap: 2GB
- off-heap: 1GB
- yarn의 memory 할당량: 3GB
2) --executor-memory=3g
- on-heap: 3GB
- off-heap: 384MB
- yarn의 memory 할당량: 3GB + 384MB
*executor 실행시 jvm 옵션
- executor가 실행될 때 java의 옵션으로 -Xmx가 지정되는데 이때는 --executor-memory에 설정된 값만 지정
- --executor-memory=2g --conf spark.executor.memoryOverhead=1g를 지정한다고 하더라도 executor가 실행될 때는 -Xmx2g만 사용되고 다른 1g은 executor 프로세스 유지를 위한 메모리를 할당한 개념
*메모리가 부족한 경우에 늘려야 하는 메모리 --executor-memory vs memoryOverhead
1) --executor-memory를 늘려야하는 경우
- GC가 자주 발생하는 경우
- 이때는 on-heap이 부족하다는 이야기이다
2) memoryOverhead를 늘려야하는 경우
- GC는 적지만, yarn에 의해 executor가 죽는 경우
3. spark executor memory내 영역 구분
Spark의 기존 메모리 관리는 정적인 메모리 분할(Memory fraction)을 통해 구조화 됨
메모리 공간은 3개의 영역으로 분리되어 있고, 각 영역의 크기는 JVM Heap 크기를 Spark Configuration에 설정된 고정 비율로 나누어 정해짐

- spark.executor.memory:
실행기에 사용할 수 있는 총 메모리 크기를 정의
- Execution(Shuffle):
1) 이 영역은 Shuffle, Join, Sort, Aggregation 등을 수행할 때의 중간 데이터를 버퍼링하는데에 사용, 이 영역의 크기는 spark.shuffle.memoryFraction(기본값: 0.2)를 통해 설정
2) spark.shuffle.memoryFraction(기본 ~20%)은 무작위 재생용으로 예약된 메모리 양을 정의 - Storage:
1) 이 영역은 주로 추후에 다시 사용하기 위한 데이터 블록들을 Caching하기 위한 용도로 사용되며, Torrent Broadcast나 큰 사이즈의 Task 결과를 전송하기 위해서도 사용, 이 영역의 크기는 spark.storage.memoryFraction(기본값: 0.6)을 통해 설정
2) spark.storage.memoryFraction(기본 ~60%)은 지속된 RDD를 저장하는 데 사용할 수 있는 메모리 양을 정의 - Other:
1) 나머지 메모리 공간은 주로 사용자 코드에서 할당되는 데이터나 Spark에서 내부적으로 사용하는 메타데이터를 저장하기 위해 사용, 이 영역은 관리되지 않는 공간(기본값은 0.2)
2) spark.storage.unrollFraction 및 spark.storage.safetyFraction(총 메모리의 ~30%) - 이러한 값은 Spark에서 내부적으로 사용되므로 변경하지 않아야 합니다
*메모리 영역이 가득 찬다면?
각 영역 메모리에 상주된 데이터들은 자신이 위치한 메모리 영역이 가득 찬다면 Disk로 Spill됨.
Storage 영역의 경우 Cache된 데이터는 전부 Drop되게 됨.
모든 경우에서 데이터 Drop이 발생하면 I/O 증가 혹은 Recomputation으로 인한 성능 저하
4. Memory, Core, Executor 수 예제 2개와 비교
EMR을 띄웠다고 가정
| 노드 수 | 코어 | 메모리 | |
| core 노드 | 2 | 16 vCore | 64 GIB |
| task 노드 | 6 | 32 vCore | 128 GIB |
노드의 총 vCore, Memory 양
32vCore x 6개 tasknode + 16vCore x 2개 corenode= 224vCore
128GiB x 6개 tasknode + 64Gib x 2개 corenode = 896GiB
4-1. yarn executor container
각 노드에 OS와 하둡 데몬을 돌릴 리소스가 필요하기 때문에,
사용가능한 yarn의 총 메모리 양 = 896- 시스템에서 사용되는 기본적인 메모리(노드당 4GB x 7nodes)
= 약 868GiB
사용가능한 yarn의 모든 core 수 또한 Hadoop과 Application master가 사용할 core등도 제외
= 31 x 6 + 15 x 2 = 216vCore
4-2. spark executor.memory + memoryOverhead
spark의
1.총executor수와
2.executor당 memory양
3.executor당 core수
위의 3개를 구하는 방법은 executor당 core수를 우선적으로 정하고 계산한다.
(executor당 코어수 정할 때 고려할 점)
1) executor당 core 수 4개로 지정
2) 216vcores / 4 = 54개 executor
3) 868GiB / 54 = 16g memory per executor
(memoryOverhead + spark.executor.memory가 16g로 할당되어야 하므로
spark.executor.memory = 14g,memoryOverhead는 spark.executor.memory의 10%격인 약 1.4g가 할당)
job을 돌릴때 해당 설정값을 spark-submit시 지정하여 적용
--executor-cores 4 --num-executors 54 --executor-memory 14GB
4-3. executor당 core수 15개의 경우와 비교
1) executor당 core 수 15개로 지정
2) 216vcores / 15 = 14개 executor
3) 868GiB / 14 = 62g memory per executor
(memoryOverhead + spark.executor.memory가 62g로 할당되어야 하므로
spark.executor.memory = 56g,memoryOverhead는 spark.executor.memory의 10%격인 약 5.6g가 할당)
파라미터 값의 증가와 감소에 따른 특징
- 하나의 Executor에서 15개로 최대 개수의 코어를 부여하면 하나의 JVM에서 너무 많은 일을 하기 때문에 HDFS의 I/O 성능이 떨어진다. Executor 당 5개의 코어를 넘지 않는 것이 좋음
- 하나의 Executor에 매우 적은 코어 개수를 부여하면 하나의 JVM 자원을 여러 개의 Task를 돌리는 이점을 가지지 못함
- 하나의 Executor에 많은 메모리 사이즈를 부여하면 Garbage Collection 딜레이가 발생
- 큰 크기의 메모리를 할당할 때 YARN의 Upper Limit 조건을 유의
- Executor 개수만큼 브로드캐스트 데이터 복제가 일어남
- Executor 개수가 많을수록 많은 양의 HDFS I/O 연산을 할 수 있다. 반대로 줄일수록 병렬성 크기는 줄어듦
적은 core 수 vs 많은 core 수
- 일반적인 case에는 변환 함수 위주로 Spark Job이 구성되기 때문에 54개 executors, 4cores per executor, 14GB per executor 파라미터 조합이 좋음
- 데이터 셔플이 많이 요구되는 함수 위주로 구성된다면 6개 executors,15cores per executor,63GB per executor 조합이 좋을 때도 있음
Spark Partition 수 조정에 관해 보시려면 아래의 링크를 참조해주세요.
https://spidyweb.tistory.com/335
참조:
https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/admin_spark_tuning.html
http://jason-heo.github.io/bigdata/2020/10/24/understanding-spark-memoryoverhead-conf.html