[Spark] Spark 실행 과정 by Catalyst Optimizer, Query plan 보는 법, Spark UI 보는 법
Query Plan을 보기에 앞서 Catalyst Optimzer에 대해 알아보고 Spark 코드의 실행 과정을 알아 보겠습니다.
Catalyst Optimzer란?
- Spark SQL에서 쿼리 성능을 최적화하는 핵심 컴포넌트
- 트리 기반의 강력한 쿼리 최적화 프레임워크로, 분석 및 실행 계획을 자동으로 최적화하여 Spark SQL, DataFrame, Dataset API의 성능을 극대화
- 카탈리스트를 구성하는 주요 데이터 타입은 node object로 구성된 tree
- Node 타입의 속성
- TreeNode 클래스를 상속 받음
- 0개 이상의 자식을 가질 수 있음
- immutable
- tansformation 함수를 통해 만들어짐
Rules
- 새로운 Tree는 Tree를 다른 Tree로 변경(transformation)하는 Rule을 생성할 수 있
- Rule을 통해 입력으로 들어온 Tree 전체를 변환할 수도 있지만, 특정 구조를 가진 Sub Tree를 찾아 변경하는 Pattern Matching Set을 적용하는 방식이 일반적
- Catalyst에서 Tree는 하위 모든 노드에 재귀적으로 Pattern Matching 함수를 수행하는 transform 함수를 제공
- Catalyst의 Rule은 Optimization이 필요한 Tree에 대해서만 적용되고 그렇지 않는 Tree에 대해서는 적용되지 않음
- Rule은 동일한 Transform 호출 내에서 여러 개의 패턴과 일치할 수 있기 때문에, 여러 Transform을 호출하지 않고 한번에 처리할 수 있도록 패턴을 정확히 구현하는 것이 중요
Catalyst의 주요 단계
- Catalyst에서는 4개 부분으로 나누어 Tree에 Transformation을 수행
- Analysis(Parsing)
- SQL 쿼리를 추상 구문 트리(AST, Abstract Syntax Tree)로 변환
- 쿼리 구문 분석 후 초기 논리 계획(Logical Plan)을 생성
- Logical Plan Optimization
- 논리 계획에 여러 규칙을 적용해 트랜스포메이션(Transformation) 작업을 수행
- 이 단계에서 중복 제거, 필터 푸시다운, 컬럼 프루닝 등 다양한 최적화가 이루어짐
- 예:
- Predicate Pushdown: 필터 조건을 최대한 데이터 소스 가까이로 이동시켜 읽는 데이터를 최소화
- Constant Folding: 상수 값을 미리 계산해 쿼리를 간소화
- Projection Pruning: 필요하지 않은 컬럼을 제외
- Physical Planning
- 논리 계획을 실제 실행 가능한 물리적 계획으로 변환
- 이 단계에서는 실행 방식(예: Sort Merge Join, Broadcast Join 등)을 결정
- 다양한 물리적 계획 중 비용 기반(Cost-based Optimization, CBO)으로 가장 효율적인 계획을 선택
- Code Generation
- JVM에서 효율적으로 실행될 수 있도록 최적화된 바이트코드를 생성합
- 이 과정에서 Java 코드로 변환해 네이티브 수준의 성능을 확보
- 연산자를 파이프라인 방식으로 연결해 함수 호출 오버헤드를 줄임
- Analysis(Parsing)
Catalyst의 주요 최적화 기법
- 필터 푸시다운 (Filter Pushdown)
- 데이터 소스에서 필요한 데이터만 필터링하여 전송하도록 유도
- I/O와 네트워크 비용을 절감
- 프로젝션 푸시다운 (Projection Pushdown)
- 필요한 컬럼만 읽도록 쿼리를 최적화
- BroadCast Join
- 작은 테이블을 모든 워커 노드에 브로드캐스트하여 대규모 조인 시 네트워크 셔플을 줄임
- Reorder Join (조인 순서 재조정)
- 조인 순서를 데이터 크기와 카디널리티(Cardinality)에 따라 재조정해 성능을 개선
- Whole Stage Code Generation (WSCG)
- 전체 파이프라인을 하나의 Java 함수로 컴파일해 런타임 오버헤드를 최소화
1. Spark 실행 계획

논리적 실행 단계(logical plan)
사용자의 코드를 논리적 실행 계획으로 변환
논리적 실행 계획 단계에서는 추상적 transformation만 표현하고, driver나 executor의 정보를 고려하지 않음
이 논리적 실행 계획으로 변환 시키는 데에는 여러 단계가 있는데,
1) unresolved logical plan(검증 전 논리적 실행 계획)
- 코드의 유효성과 테이블이나 컬럼의 존재 여부만을 판단하는 과정, 실행 계획은 검증되지 않은 상태
- spark analyzer는 컬럼과 테이블을 검증하기 위해 Catalog, 모든 테이블의 저장소 그리고 Dataframe 정보를 활용
- 필요한 테이블이나 컬럼이 Catalog에 없다면 검증 전 논리적 실행 계획이 만들어지지 않음
2) logical plan(검증된 논리적 실행 계획)
- 코드의 유효성과 구문상의 검증이 완료되어 논리적 실행 계획 생성
- 테이블과 컬럼에 대한 결과는 Catalyst Optimizer로 전달
3) optimized logical plan(최적화된 논리적 실행 계획)
- 검증된 논리적 실행계획을 Catalyst Optimizer로 전달하여 조건절 푸쉬 다운이나 선택절 구문을 이용해 논리적 실행 계획을 최적화함
물리적 실행 단계(physical plan)
Spark 실행 계획이라고도 불리는 물리적 실행 단계는 앞으로 알아 볼 Query plan보기, Spark UI보기에 표시 될 실행 계획
논리적 실행 계획을 클러스터 환경에서 실행하는 방법을 정의
1) physical plans(물리적 실행계획들)
- 최적화된 논리적 실행 계획을 가지고 하나 이상의 물리적 실행 계획을 생성
- 다양한 물리적 실행 전략을 생성(각 operator별 어떤 알고리즘을 적용할 지)하고 비용 모델을 이용해서 비교한 후 최적의 전략을 선택
2) Cost Model(비용 모델)
- 가장 좋은 plan은 비용기반 모델(모델의 비용을 비교)
- 테이블의 크기나 파티션 수 등 물리적 속성을 고려해 지정된 조인 연산 수행에 필요한 비용을 계산하고 비교함
3) Selected Physical Plan(최적의 물리적 실행 계획)
- 위의 비용 모델에 따라 최적의 물리적 실행 계획을 도출
4) 물리적 실행 계획은 일련의 RDD와 transformation으로 변환(컴파일)
- 각 머신에서 실행 될 Java Bytecode를 생성함(compile)
2. Query Plan + Spark UI
Query Plan은 위에서 언급 한 것과 같이 Physical plan을 의미하고, dataframe에 explain()을 함으로써 확인 할 수 있다.

Spark UI는 SparkSession이 생성되면 IP주소:port를 통해 접속할 수 있는데, 보통은 4040포트를 사용한다.
Spark UI의 SQL를 눌러보면 위의 explain()으로 확인한 Physical Plan을 UI로 확인할 수 있다.
단, Dataframe에 action이 실행되어야 물리적인 실행계획이 생성되기 때문에, UI의 SQL에서도 action이 실행되어야 확인할 수 있다.

Query Plan과 SparkUI에서의 각 실행 단계들은 대부분 아래의 단계들로 추려질 수 있습니다.
CollapseCodegenStages
UI에서 여러 연산자들이 큰 파란색 직사각형안에 그룹핑되어 있는데, codegen stages로 구별된다.
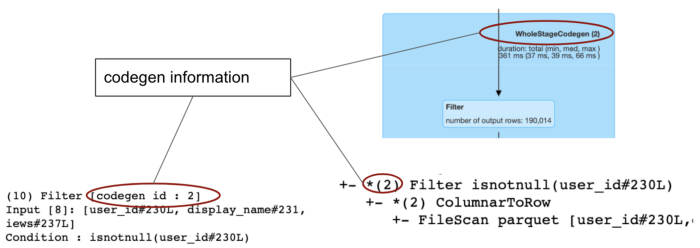
- CollapseCodegenStages라는 규칙이 Catalyst Optimizer에 있는데, 이것은 코드 생성을 지원하는 연산자를 가져와 함께 축소하여 가상 함수 호출을 제거하여 실행 속도를 높이는 것
Scan [file format]
- source 파일 포멧에 따라서 scan csv, scan json, scan parquet등 이름이 정해짐
Project
- (컬럼/추가/필터링)
- select
- withColumn
- when().otherwise()와 같은 select내에서의 필터링 및 조작
Exchange
- 쉽게 말해서 Exchange는 shuffle, cluster내에서의 물리적인 데이터의 이동을 뜻함
- 물리적인 데이터의 이동은 비용이 많이 들음
- joins: Hash join이 일어날 때 Hash Partitiong Exchange가 일어남
- Repartitions: n개의 파티션에 데이터를 랜덤으로 재분배할 경우, RoundRobinPartitioning Exchange가 일어남
- Coalesce: 단일 executor로 데이터를 전부 이전시켜야 할 때 SinglePartition Exchange가 일어남
- Sort: 결과 데이터를 정렬시킬 때(order by) RangePartitioning Exchange가 일어남
- groupBy(), union()과 같은 연산자도 data shuffling(Exchange)을 함
Filter
- 필터 조건이 쿼리에서 작성된 것대로 전부 계획에 반영되지 않고, Catalyst Optimizer가 중복된 필터는 제외시키고, 직관적인 새로운 필터를 적용시켜줌
- where(), filter()에 해당
HashAggregate
- count,sum,min,max등 data aggregation에 쓰임
join: BroadcastHashJoin & BroadcastExchange
- 조인 단계에서 3가지 조인 알고리즘으로 분류되어 나타남
- 이 알고리즘들은 equijoin(동등조인)에서만 사용되어야 하고 그렇지 않을 때는 성능이 현저히 떨어짐
- BroadcastHashJoin:
조인하는 dataframe중 한 쪽이 작은 크기일 때(몇 MB정도) 작은 DF는 모든 executor에 broadcast됨 (Exchange)
그리고 큰 테이블과 Hash join을 함 - ShuffledHashJoin:
다른 한쪽의 Dataframe이 나머지 한 쪽 보다 최소 3배 이상 작고, 평균 파티션 크기가 broadcast하기에 충분히 작을 때 사용. partition들이 broadcast되고(exchange) Hash Join을 함 - SortMergeJoin:
가장 일반적인 조인. 위의 두가지 조인기법을 사용할 수 없을 때 사용. 양쪽에서 정렬되고, MergeSort join을 함 - 이외에도 Cartesian Product Join이나 BroadcastNestedLoopJoin이 있지만 이 들은 좋은 성능을 내지 못함