BigData/Spark & Spark Tuning
[Spark Tuning] Spark 3.x 버전 특징 정리
스파이디웹
2023. 8. 10. 21:52
728x90
이번 포스트에는 spark 2.x 와 spark3.x의 특징을 비교해보고 spark 3.x 버전의 주요 특징과 성능에 대해서 포스트해보겠습니다.
spark 3.x버전의 특징을 통해 눈에 띄게 성능의 향상을 본 workload가 아직은 없기 때문에, 관련한 포스트는 추후에 올리도록 하겠습니다.
Spark 2.x vs Spark 3.x
| spark 2.x | spark 3.x | |
| Language support | python 2.x,3.x, scala 2.12까지, java8+ | python 3.6+, scala 2.12+, Java 8 prior to version 8u92 support is deprecated |
| Catalyst Optimizer | Rule + Cost based optimizer • Table statics 기반 → missing, outdated | Rule + Cost + Runtime ⇒ Adaptive Planning • Task 수행을 마친 Stage의 결과의 statics를 바탕으로 아직 수행되지 않은 Stage들에 대해 Logical Plan부터 다시 Optimize • spark.sql.adaptive.enabled → default false이고 true로 변경 시 enable • Dynamically coalescing shuffle partitions • Dynamically switching join strategies • Dynamically optimizing skew joins |
| Partition Pruning | Static | Static + Dynamic |
| functions | spark2.x functions | spark 2.x + Spark 3.0 — New Functions in a Nutshell -list- sinh,cosh,tanh,asinh,acosh,atanh,any,bit_and,bit_or,bit_count,bit_xor, bool_and,bool_or,count_if,date_part,extract,forall,from_csv, make_date,make_interval,make_timestamp,map_entries map_filter,map_zip_with,max_by,min_by,schema_of_csv,to_csv transform_keys,transform_values,typeof,version xxhash64 |
Spark 3.x 추가 특징
Adaptive Execution Query
- AQE(Adaptive Query Execution)는 런타임 통계를 사용하여 가장 효율적인 쿼리 실행 계획을 선택하는 스파크 SQL의 최적화 기술
- 관련 config
- spark.sql.adaptive.enabled
Dynamically coalescing shuffle partitions

- Shuffle 시 Partitioning에 대한 Runtime optimization
- 기존에는 Suffle partition 갯수가 spark.sql.shuffle.partitions config에 따라 결정되었음(default 200)
- 너무 작을 때는 GC pressure 및 Spilling overhead발생
- 너무 클 때는 비효율적인 I/O 및 Scheduler pressure발생
- 처음에는 Shuffle Partition갯수를 크게 잡은 후 Shuffling Stage수행 후 Data Size가 작은 Partition을 하나의 파티션으로 묶어서 Reduction Stage의 Partition수를 줄임(1) 5개 partition으로 column j를 key로 shuffling을 수행
- (2) Runtime Data size가 작은 파티션을 통합해 하나의 Partition으로 묶은 후 Reduction
- (ex) SELECT max(i)FROM tbl GROUP BY j
- 관련 config
- spark.sql.adaptive.coalescePartitions.enabled
- spark.sql.adaptive.coalescePartitions.minPartitionSize
- spark.sql.adaptive.coalescePartitions.initialPartitionNum
Dynamically switching join strategies

- runtime에 join 기법을 바꿀 방법은 없었지만, 런타임 이후에 해당 통계를 바탕으로 남은 쿼리에 대해서 조인기법이 dynamic하게 바뀔 수 있게 적용
- 기존에는 Query planning 단계에서 ANALYZE Command로 table의 statics 정보를 얻을 수 있을 때만 Broadcast-hash join실행하고 statics 정보가 없을 때는 Sort-merge join을 실행했음
- (Broadcast-hash join은 Local에서 join이 이루어지므로 shuffling이 발생하지 않아 Sort-merge join 보다 속도가 빠름)
- Table에 대한 Scan Stage가 끝난 후 남은 쿼리에 대해서, Table 데이터 사이즈가 broadcast할 수 있을 만큼 작다면 Sort-merge join에서 Broadcast-hash join으로 Plan을 변경함
- 관련 config
- spark.sql.adaptive.localShuffleReader.enabled
- spark.sql.adaptive.autoBroadcastJoinThreshold
Dynamically optimizing skew joins
- runtime 통계에 의해 skew를 찾아내고, skew된 partition을 더 작은 파티션으로 분리
- Sort-merge Join 시 Skew된 Partition을 Runtime에 SubPartition으로 나눠서 Join
- 관련 config
- spark.sql.adaptive.skewJoin.skewedPartitionFactor ******(default=5)
- spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes ******(default = 256MB)
- spark.sql.adaptive.optimizeSkewsInRebalancePartitions.enabled
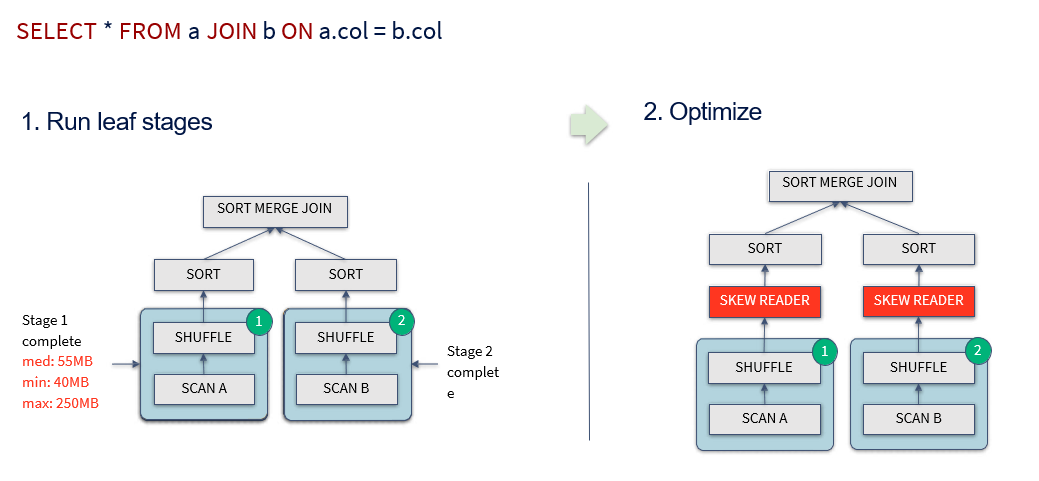

spark 3.x 버전을 사용하게 될 때 복잡한 조인이 들어간 로직이나, 빅데이터 일 때 해당 property값들이 성능을 발휘할 수 있찌만 여태 눈에 띄게 개선된 사례를 찾기 힘들어서, 추후에 성능 개선 포스팅과 함께 돌아오도록 하겠습니다.
728x90