BigData/Spark & Spark Tuning
[Spark] 스파크의 분산형 공유 변수 Accumulator, Broadcast Variable정리
스파이디웹
2025. 1. 7. 23:20
728x90
spark의 저수준 API에는 RDD 인터페이스 외에 두 번째 유형인 '분산형 공유 변수'가 있음
- Accumulator
- Broadcast Variable
1. Accumulator
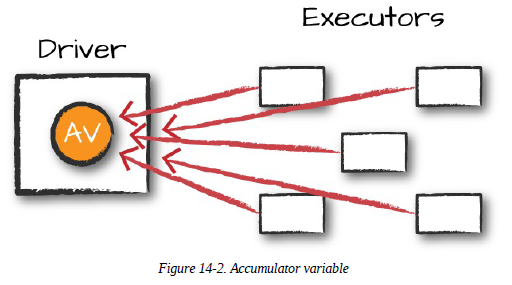
- 스파크의 2번째 공유 변수 타입
- 트랜스포메이션 내부의 다양한 값을 갱신하는 데 사용, 내고장성을 보장하면서 효율적인 방식으로 드라이버에 값을 전달
- ex) 모든 태스크의 데이터를 굥유 결과에 추가할 수 있음
- ex) job의 입력 레코드를 파싱하면서 얼마나 많은 오류가 발생했는지 확인하는 카운터를 구현할 수 있음(디버깅용이나 저수준 집계 생성용)
- ex) 파티션별로 특정 변수의 값을 추적하는 용도로 사용할 수 있으며 시간이 흐를수록 더 유용하게 사용 됨
- 결합성과 가환성을 가진 연산을 통해서만 더할 수 있는 변수이므로 병렬 처리 과정에서 효율적으로 사용할 수 있음
- 어큐뮬레이터의 값은 액션을 처리하는 과정에서만 갱신, 각 태스크에서 어큐뮬레이터를 한 번만 갱신하도록 제어 → 재시작한 태스크는 어큐뮬레이터값을 갱신할 수 없음, 트렌스포메이션에서 태스크나 잡 스테이지를 재처리하는 경우 각 태스크의 갱신 작업이 2번 이상 적용될 수 있음
가환성이란?
연산의 순서를 바꾸어도 그 결과가 변하지 않는 일(덧셈 혹은 곱셈)
내고장성이란?
내고장성 (Fault-Tolerant)이란 결함이나 고장이 발생해도 정상적으로 동작하는 시스템 을 의미
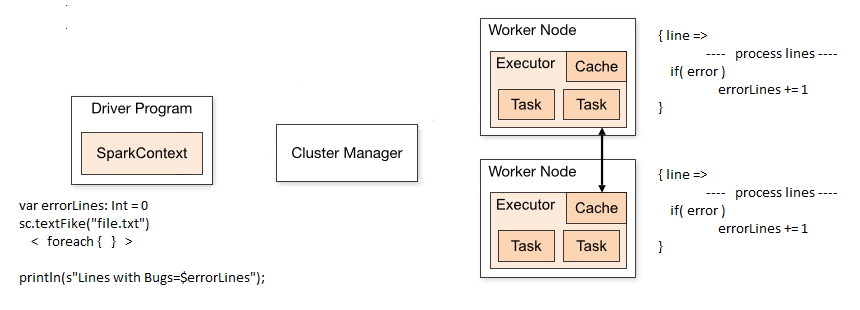
var errorLines: Int = 0
sc.textFike("file.txt").foreach { line =>
---- process lines ----
if( error )
errorLines += 1
}
println(s"Lines with Bugs=$errorLines");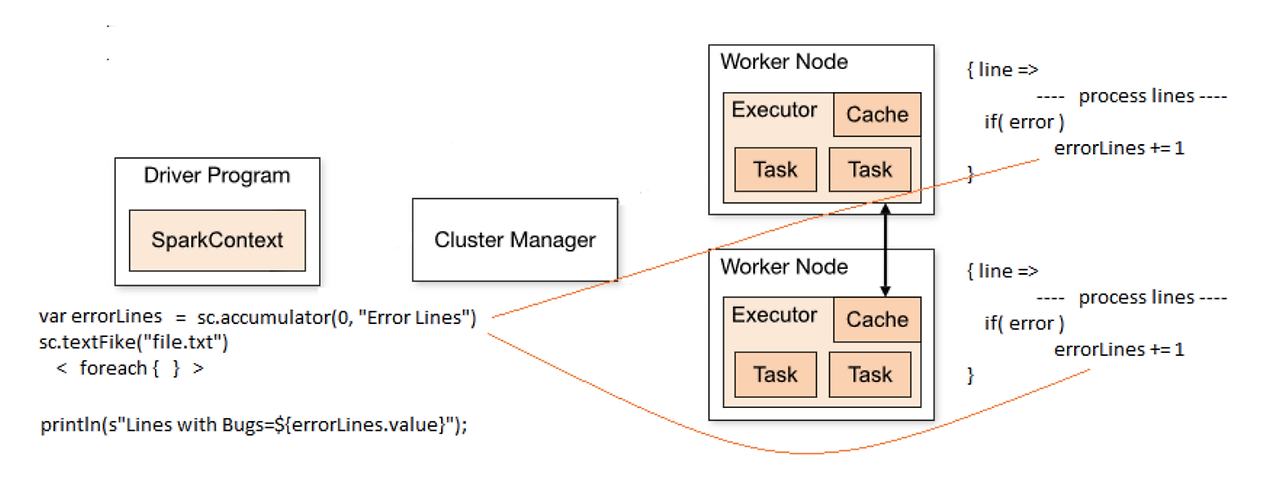
val spark: SparkSession = ...
val errorLine = spark.sparkContext.longAccumulator("errorLine")
spark.sparkContext.parallelize(data).foreach { item =>
if (isError(item)) {
errorLine+=1
}
}
println(s"Error count: ${errorLine}")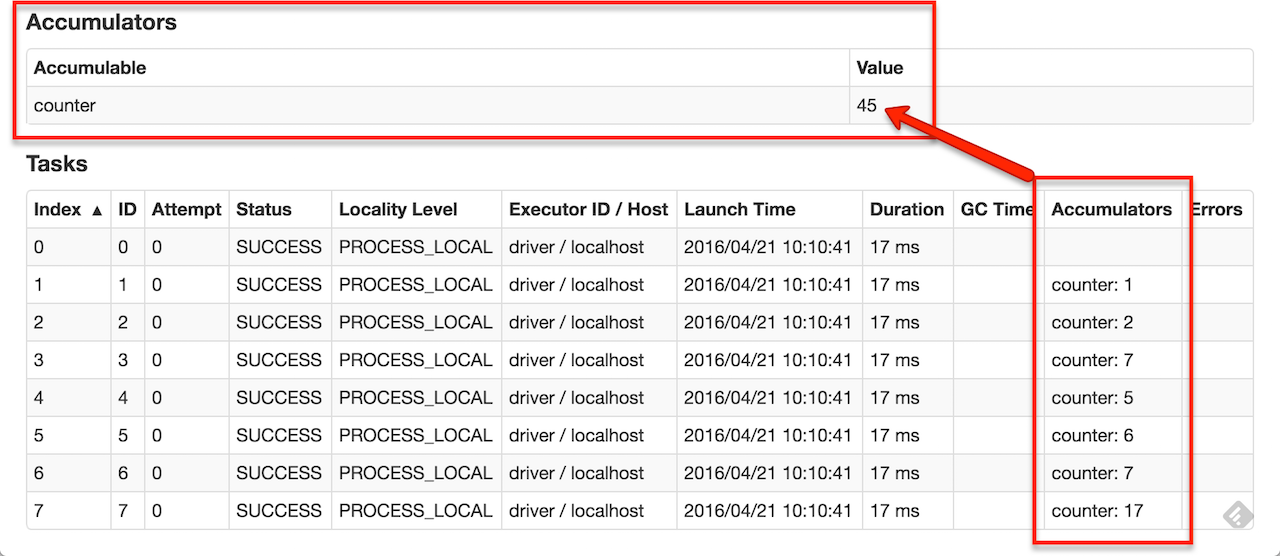
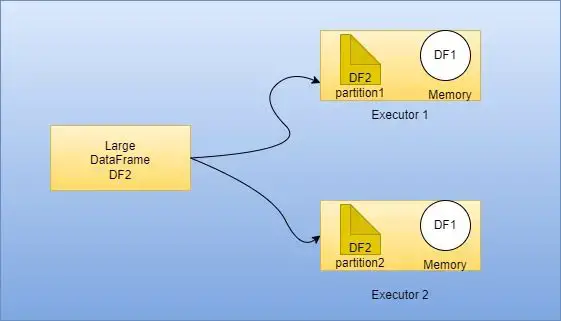
2. Broadcast Variable
- 모든 워커 노드에 큰 값을 저장하므로 재전송 없이 많은 스파크 액션에서 재사용할 수 있음(모든 태스크마다 직렬화하지 않고 클러스터의 모든 머신의 메모리에 캐시하는 불변성 공유 변수)
- 변하지 않는 값(불변성 값)을 클로저 함수의 변수로 캡슐화하지 않고 클러스터에서 효율적으로 공유하는 방법을 제공
- 클러스터의 모든 노드에 큰 읽기 전용 값을 효율적으로 분산하기 위한 Spark의 메커니즘
- 일반적으로 전체 작업에서 공통적으로 사용되는 대규모 데이터 세트(예: 참조 데이터, lookup 테이블)에 사용
// 브로드캐스트에 저장 될 변수
val supplementalData = Map("Spark" -> 1000, "Definitive" -> 200, "Big" -> -300, "Simple" -> 100)
// 캐싱
val suppBroadcase = spark.sparkContext.broadcast(supplementalData)
// 브로드캐스트 변수 확인
suppBroadcast.value
words.map(word => (word, suppBroadcast.value.getOrElse(word, 0)))
.sortBy(wordPair => wordPair._2)
.collect()
참조:
728x90