BigData/Data Engineering
[Data Engineering] Real-time processing, Streaming data과 Message의 차이는?
스파이디웹
2025. 2. 1. 02:29
728x90
흔히들 실시간(real-time) streaming, Message 용어에 대한 개념에 대해 혼동하는 경우가 많으므로, 이번 포스트에는 해당 용어들을 정리해보겠습니다.
1. Real-time processing vs Streaming data
1) Real-time processing
실시간 처리에 대한 위키피디아 글 인용
"실시간 프로그램은 지정된 시간 제약 내에서 응답을 보장해야 하며, 이는 종종 '데드라인'이라고 불린다. […] 실시간 처리는 특정 이벤트에 대해 지정된 데드라인 내에 완료되지 않으면 실패한 것으로 간주된다. 시스템 부하와 관계없이 데드라인은 항상 준수되어야 한다."
대개 우리가 real-time에 대해서 말할 때 2가지의 기준에 따라 분류 됨
- Real-time: 일반적으로 수 밀리초에서 몇 초 단위의 시간 범위를 의미함
- Near real-time: 수 초에서 몇 시간까지의 시간 범위를 의미하며, 완전한 실시간은 아니지만 비교적 빠른 처리를 목표로 함

2) streaming data
- 스트리밍은 시작과 끝이 없는 연속적이고 끊임없는 데이터 흐름을 설명하는 데 사용
- 간단히 말해, 스트리밍 데이터란 다양한 소스에서 지속적으로 생성되는 데이터의 흐름을 의미
위키피디아 글 인용
스트리밍 데이터는 서로 다른 소스에서 지속적으로 생성되는 데이터를 의미한다. 이러한 데이터는
전체 데이터에 접근하지 않고 스트리밍 처리 기법을 사용하여 점진적으로 처리되어야 한다. […] 이는 일반적으로
다양한 소스에서 고속으로 생성되는 빅데이터 환경에서 사용된다.
- 즉, 스트리밍 데이터는 데이터가 지속적으로 생성되는 방식과 이를 수집하는 방법(예: Kafka, Kinesis, Pub/Sub 등의 도구 사용)을 의미
- 스트리밍 데이터의 반대 개념은 배치 데이터(batch data)로, 데이터가 연속적인 스트림이 아니라 개별적인 덩어리(chunks)로 주기적으로 수집(예: 매시간, 매일, 매주)
- 또한, "마이크로 배치(micro-batches)"라는 용어는 더 작은 크기의 배치를 더 자주 처리하는 시스템을 설명하는 데 사용된다. 예를 들어, BigQuery, Redshift, Snowflake는 5분마다 배치를 수집하는 기능을 제공, spark streaming이 마이크로 배치의 대표적 tool

| real-time | streaming data |
| 응답 시간의 최대 허용 범위에 맞춰 정의 | 연속적인 데이터 수집을 설명하면서 응답 시간이 줄어들 가능성을 시사 |
3) real-time과 streaming의 관계
reat-time 요구사항과 ingestion 빈도

real-time 요구사항과 ingestion 빈도에 따른 use case

2. Streaming Data vs Message
1) 개념 차이
- Message (메시지): 하나의 독립적인 데이터 단위로, 송신자가 수신자에게 특정 정보를 전달하는 역할
- Stream (스트림): 연속적인 데이터 흐름으로, 일정한 순서로 데이터를 전송하고 처리하는 방식
연속적이냐 아니냐에 큰 차이가 있음
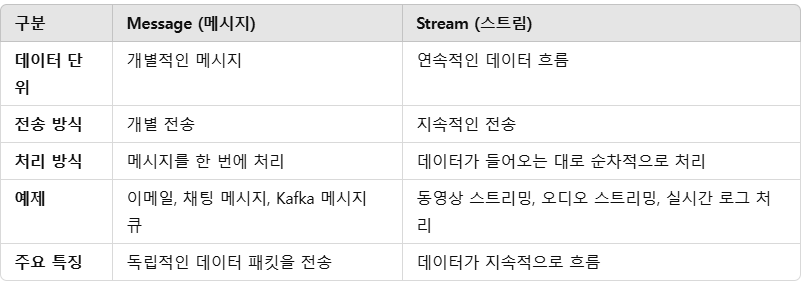
2) Message와 Streaming data의 Use case
Message 기반 시스템
- Kafka: 메시지 큐(Message Queue) 시스템에서 개별적인 메시지를 전송하고, 소비자는 메시지를 하나씩 읽어서 처리
- RabbitMQ: 메시지를 개별 단위로 처리하는 메시지 브로커
- Amazon Simple Queue Service (SQS): 아마존 메세지 큐 서비
Stream 기반 시스템
- Spark Streaming: 실시간으로 들어오는 데이터 스트림을 처리하는 프레임워크
- Flask Streaming Response: 서버에서 데이터를 지속적으로 생성하며 클라이언트에 실시간 전송
- Kafka Streams: Kafka 메시지를 실시간으로 스트리밍 처리하는 방식

728x90