일반적인 데이터의 특징
| 구분 | 정성적 데이터 | 정량적 데이터 |
| 형태 | 비정형 데이터 | 정형ㆍ반정형 데이터 |
| 특징 | 객체 하나에 함의된 정보를 갖고 있다. | 속성이 모여 객체를 이룬다. |
| 구성 | 언어, 문자 등으로 이루어짐 | 수치, 도형, 기호 등으로 이루어짐 |
| 저장 형태 | 파일, 웹 | 데이터베이스, 스프레드시트 |
| 소스 위치 | 외부 시스템(주로 소셜 데이터) | 내부 시스템(주로 DBMS) |
수집활동에서 데이터의 특징
구분가역적 데이터불가역적 데이터환원 가능성의존성원본 데이터와의 관계처리 과정활용 분야
| 구분 | 가역적 데이터 | 불가역적 데이터 |
| 환원 가능성 | 가능하다 | 불가능하다 |
| 의존성 | 원본 데이터에 의존적 | 원본 데이터에 독립적 |
| 원본 데이터와의 관계 | 1:1 관계 | 1:N 혹은 N:1 |
| 처리 과정 | 탐색 | 병합 |
| 활용 분야 | 데이터 웨어하우징, 로그 수집 | 소셜 분석, 텍스트 마이닝 |
데이터 수집을 위해 가장 먼저 고려해야 할 사항은 수집 대상 데이터의 종류일 것이다. 데이터 종류는 데이터가 저장ㆍ관리되는 형태와 데이터의 저장 위치, 그리고 데이터의 생산 주체에 따라 구분할 수 있다.
수집 데이터의 형태에 따른 분류
데이터를 형태에 따라 분류해 보면 정형 데이터, 반정형 데이터, 비정형 데이터로 나눌 수 있다.
정형 데이터
-특징
정형 데이터(Structured Data)는 관계형 데이터베이스 시스템의 테이블과 같이 고정된 컬럼에 저장되는 데이터와 파일, 그리고 지정된 행과 열에 의해 데이터의 속성이 구별되는 스프레드시트 형태의 데이터도 있을 수 있다. 관계형 데이터베이스 시스템의 정형 데이터를 비정형 데이터(Unstructured Data)와 비교할 때 가장 큰 차이점은 데이터의 스키마를 지원하는 것이다.
-데이터 탐색
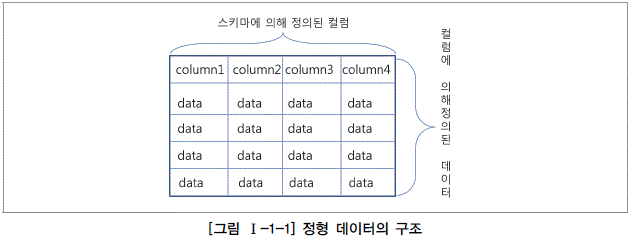
정형 데이터의 경우, 스키마 구조를 가지고 있기 때문에 데이터를 탐색하는 과정이 테이블 탐색, 컬럼 구조 탐색, 로우 탐색 순으로 정형화되어 있다.
예) SELECT COLUMN1, COLUMN2… FROM TABLE WHERE CONDITION
-형태
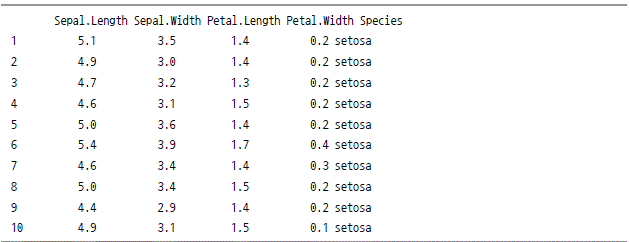
-정형 데이터의 예
RDBMS의 테이블들(단일 테이블 혹은 조인한 테이블 포함)
스프레드시트
반정형 데이터(Semi-Structred Data)
-특징
정형 데이터는 데이터의 스키마 정보를 관리하는 DBMS와 데이터 내용이 저장되는 데이터 저장소로 구분되지만, 반정형 데이터는 데이터 내부에 정형데이터의 스키마에 해당되는 메타데이터를 갖고 있으며. 일반적으로 파일 형태로 저장된다.
-데이터 탐색

반정형 데이터의 경우 데이터 내부에 데이터 구조에 대한 메터정보를 갖고 있기 때문에 어떤 형태를 가진 데이터인지를 파악하는 것이 필요하다. 데이터 내부에 있는 규칙성을 파악해 데이터를 파싱할 수 있는 파싱 규칙을 적용한다.
-형태

-반정형 데이터의 예
URL 형태로 존재 - HTML
오픈 API 형태로 제공 - XML, JSON
로그형태 - 웹로그, IOT에서 제공하는 센서 데이터
비정형 데이터
-특징
비정형 데이터(Unstructured-Data)는 데이터 세트가 아닌 하나의 데이터가 수집 데이터로 객체화돼 있다. 언어 분석이 가능한 텍스트 데이터나 이미지, 동영상 같은 멀티미디어 데이터가 대표적인 비정형 데이터다. 웹에 존재하는 데이터의 경우 html 형태로 존재하여 반정형 데이터로 구분할 수도 있지만, 특정한 경우 텍스트 마이닝을 통해 데이터를 수집하는 경우도 존재하므로 명확한 구분은 어렵다.
-데이터 탐색
이진 파일 형태: 동영상, 이미지(BLOB)
스크립트 파일 형태: 소셜 데이터의 텍스트(CLOB)
이진 파일 형태의 데이터일 때, 데이터를 탐색하는 방법은 데이터의 종류별로 응용소프트웨어를 이용하여 탐색한다.
예) 동영상: 동영상 플레이어 (스크립트 파일 형태일 경우 데이터를 파싱해 처리)
수집데이터의 형태와 데이터 수집과의 관계
어떤 데이터의 수집이 가능하다고 가정할 때 수집 데이터의 형태가 데이터 수집에서 어떠한 사항들과 관계가 있는지 살펴보자. 수집의 난이도, 데이터 처리 아키텍처 구성, 데이터의 잠재적 가치 측면에서 알아보자.
-수집 난이도
| 형태 | 특징 | 난이도 |
| 정형 데이터 | 내부 시스템인 경우가 대부분이라 수집이 쉽다. 파일 형태의 스프레드시트라도 내부에 형식을 가지고 있어 처리가 쉬운 편이다. | 하 |
| 반정형 데이터 | 보통 API 형태로 제공되기 때문에 데이터 처리 기술이 요구 된다. | 중 |
| 비정형 데이터 | 텍스트 마이닝 혹은 파일일 경우 파일을 데이터 형태로 파싱해야 하기 때문에 수집 데이터 처리가 어렵다. | 상 |
-데이터 처리 아키텍처
| 형태 | 특징 | 난이도 |
| 정형 데이터 | CRUD가 일어나는 일반적인 아키텍처 구조로 이루어져 있다. | 하 |
| 반정형 데이터 | 데이터의 메타구조를 해석해 정형 데이터 형태로 바꿀 수 있는 아키텍처 구조를 수정해야 한다. | 중 |
| 비정형 데이터 | 텍스트나 파일을 파싱해 메타구조를 갖는 데이터의 셋형태로 바꾸고 정형 데이터 형태의 구조로 만들 수 있도록 아키텍처 구조를 수정해야 한다. | 상 |
-데이터의 잠재적 가치
| 형태 | 특징 | 잠재가치 |
| 정형 데이터 | 내부 데이터의 특성상 현실적 가치의 한계상 활용측면에서 잠재적 가치는 상대적으로 낮다. | 보통 |
| 반정형 데이터 | 데이터의 제공자가 선별해 제공하는 데이터로 잠재적 가치는 정형 데이터 보다 높다. | 높음 |
| 비정형 데이터 | 수집주체에 의해 데이터에 대한 분석이 선행되었기 때문에 목적론적 데이터 특징이 가장 잘 나타나는 데이터이다. 그렇기 때문에 일단 수집이 가능하면 수집주체에게는 가장 높은 잠재적 가치를 제공한다. | 매우높음 |
수집데이터의 위치에 따른 분류
수집하려는 데이터를 저장된 위치에 따라 분류하면 동일한 시스템계에 저장되는 내부 데이터와 외부시스템에 저장된 외부 데이터로 나눌 수 있다. 이는 배치 처리에서 해당되고 실시간 처리에서는 저장되는 위치가 아니라 발생하는 위치에 따라 내부 데이터와 외부 데이터로 나눌 수 있다. 수집시 내부와 외부로 데이터를 분류하는 가장 큰 이유는 원천 시스템과 연계를 위한 인터페이스의 기술적 방법 및 정책적 차이점 때문일 것이다. 내부 데이터와 외부 데이터의 특징과 데이터의 위치에 따른 데이터 수집의 인터페이스 방법에 대해 알아보자
내부데이터
-특징
수집하는 원천 데이터의 데이터 저장소가 내부시스템에 있는 데이터를 의미한다. 단순히 물리적 데이터 저장소 외에도 내부데이터와 외부 데이터의 가장 큰 구별점은 데이터 제공자와 상호 협약에 의한 의사소통이 가능하다는 점이다. 또한 원천데이터와 수집한 데이터가 동일 시스템계에 저장돼 있으므로 원천데이터가 외부에 있는 경우와 비교했을 때 상대적으로 기술적 제약도 적은 편이다.
-인터페이스 방법
인터페이스할 데이터의 수집주기 및 방법은 데이터 제공자(또는 기관)와의 협약을 통해 제공 받는다. 또한 수집성공 여부에 대한 별도의 인터페이스를 설정해 수집 실패한 데이터에 대해 재수집이 가능하도록 구현할 수 있다.
외부데이터
-특징
수집하는 원천 데이터의 데이터 저장소가 외부 시스템에 있는 데이터를 의미한다. 일반적으로 내부 데이터와 가장 큰 구별점은 데이터 제공자와 협약된 관계가 아니면 상호 의사소통이 불가능하다는 점이다. 따라서 데이터 수집을 위해 수집주기 및 방법에 관한 분석이 필요하다.
-인터페이스 방법
외부 데이터의 인터페이스 방법은 수집할 항목을 분석해 수집 시스템을 설계하는 것이다. 협약이 되지 않은 시스템의 경우 수집 실패 시의 대안을 마련해야 한다. 가능한 데이터의 전처리 과정 없이 원본 데이터를 수집 후, 수집 시스템에서 처리를 할 수 있도록 인터페이스를 설계하는 것이 바람직하다.
수집 데이터의 위치와 데이터 수집과의 관계
수집 데이터의 위치가 데이터 수집에서 어떠한 사항들과 관계가 있는지 수집의 난이도, 데이터 처리 아키텍처 구성, 데이터의 잠재적 가치 측면에서 알아보도록 하자.
-수집난이도
| 위치 | 특징 | 난이도 |
| 내부 | 데이터의 저장소가 내부에 있으므로 해당 소스 데이터 담당자와 의사소통이 원활하기 때문에 수집난이도가 외부데이터와 비교해 낮다. | 하 |
| 외부 | 외부 소스의 경우 해당 소스 데이터 담당자와 의사소통이 어려워 상대적으로 수집 난이도가 높다 | 상 |
-데이터처리 아키텍쳐
| 위치 | 특징 | 난이도 |
| 내부 | 대부분 정형 데이터이므로 일반적인 CRUD처리 아키텍처와 같은 구성이 가능하다. | 하 |
| 외부 | 대부분 비정형, 반정형 데이터 형태로 일반적인 아키텍처 구성에 반정형, 비정형 데이터를 처리할 수 있는 아키텍처를 추가해야 한다. | 상 |
-데이터의 잠재적가치
| 위치 | 특징 | 난이도 |
| 내부 | 내부 데이터의 특성과 현실적 가치의 한계상 활용 측면에서 잠재적 가치는 상대적으로 낮다. | 보통 |
| 외부 | 데이터의 제공자가 선별해 제공하는 데이터나 수집주체에 대한 분석이 이루어진 후 수집을 하는 데이터이기 때문에 데이터의 목적론적 특징이 가장 잘 나타나는 데이터이다. 그렇기 때문에 내부 데이터와 비교할 경우 상대적으로 잠재적 가치가 높다. | 높음 |
'DataBase > Data & SQL' 카테고리의 다른 글
| [Data&SQL] Ad-Hoc , Ad-Hoc 쿼리란? (0) | 2021.01.19 |
|---|---|
| [Data]로그 데이터 수집 (0) | 2021.01.07 |
| [Data]데이터 수집 방법 및 기술(Data Extraction) (0) | 2021.01.05 |
| [Data]데이터 수집 절차 (0) | 2021.01.05 |
| oracle, ms-sql DDL ,DML ,DCL ,TCL정리 (0) | 2020.12.09 |
댓글