1. 숫자형(number)
| 항목 | 파이썬 사용 예 |
| 정수(integer) | 123,-345,0 |
| 실수(floating-number) | 123.45,-1234.5,3.4e10 |
| 8진수(octal) | 0o34,0o25 |
| 16진수(hexadecimal) | 0x2A,0xFF |
x의 y제곱을 나타내는 ** 연산자
ex)
x = 3
y = 4
x ** y = 81(3의 4제곱)나눗셈 후 나머지를 반환하는 % 연산자
ex)
7 % 3 == 1
3 % 7 == 3나눗셈 후 몫을 반환하는 // 연산자
ex)
7 / 4 == 1.75 (몫과 나머지)
7 // 4 == 1(몫)2. 문자열 자료형(string)
문자열(string)이란 문자,단어 등으로 구성된 문자들의 집합
ex)
"life is short, You need python"
"a"
"123"문자열 만드는 법
- 큰따옴표(")로 양쪽 둘러싸기
- 작은따옴표(')로 양쪽 둘러싸기
- 큰따옴표3개(""")로 양쪽 둘러싸기
- 작은따옴표3개(''')로 양쪽 둘러싸기
문자열 안에 작은따옴표나 큰따옴표를 포함시키고 싶을 때
- "example'example"
- 'example"example' 처럼 큰따옴표로 감쌀 때는 작은따옴표가 문자열에 포함 작은따옴표로 감쌀 때는 큰따옴표가 문자열에 포함.
- "\"python is very easy.\""처럼 백슬래쉬(\)를 쓰면 그 앞의 "가 포함된다.
개행 처리
- "life is too short\nYou need python" 처럼 개행문자를 사용
- 변수 = '''
string example
string example2
''' 처럼 작은따옴표 3개로 감싸도 된다.
문자열 연산
- 문자열 더해서 연결하기(concatenation)
head = "python"
tail = " has interprater"
head + tail == "python has interparter" - 문자열 곱하기
head * 2 == "pythonpython" - 문자열 길이 구하기
a = "life is too short"
len(a) == 17
문자열 인덱싱(indexing)과 슬라이싱(slicing)
a = "life is too short, you need python"이라는 문자열을 a변수에 저장 했을 때,
'l'문자가 인덱스의 시작인 a[0]의 값이다.
ex)
a[0] == 'l'
a[3] == 'e'
print(a[0])
print(a[3])
#l출력
#e출력"파이썬은 0부터 숫자를 센다" 라고 생각하시면 됩니다.
a[-1] == 'n'
#true
a[0] == a[-0] == 'l'
#true
a[-2] == 'o'
#true문자열 슬라이싱이란?
문자열에서 자리번호에 해당하는 값을 뽑아내는 것.
a = "life is too short, you need python"
print("1)", a[0:4])#0번쨰부터 4번째 미만까지의 인덱스에 해당하는 값을 뽑아 낸다.(0<= a <4)
print("2)", a[5:7])
print("3)", a[12:17])
print("4)", a[19:])
print("5)", a[:17])
print("6)", a[:])#a변수랑 같다
print("7)", a[19:-7])
문자열 포맷팅(formatting)
#1) 숫자 대입
print("1)", "i eat %d apples." % 3)
#2) 문자열 바로 대입
print("2)", "i eat %s apples." % "five")
#3) 숫자 값을 나타내는 변수로 대입
number = 3
print("3)", "i eat %d apples." % number)
#4) 2개 이상의 값 넣기
number = 10
day = "three"
print("4)", "i ate %d apples. so i was sick for %s days." %(number, day))
#5) 이름으로 넣기
print("5)", "i ate {number} apples. so i was sick for {day} days.".format(number = 10, day = 3))
#6) 인덱스랑 이름을 혼용해서 넣기
print("6)", "i ate {0} apples. so i was sick for {day} days.".format(10, day=3))
문자열 관련 함수
#1) 문자 개수 세기(count)
a = "hobby"
print(a.count('b'))
#2) 위치 알려주기 1(find)
a = "python is the best choice"
print(a.find('b'))
print(a.find('k'))#찾는 문자나 문자열이 존재하지않을 때 -1반환
#3) 위치 알려주기 2(index)
a = "life is too short"
print(a.index("t"))#가장 먼저 나온 위치를 반환
try:
print(a.index("k"))
except:
pass
#traceback 오류 발생, 패스시킨다.(찾는 문자가 없기 때문에)
#4) 문자열 삽입(join)
print(",".join('abcd'))
print(",".join(['a','b','c','d']))
#5) 소문자 -> 대문자(upper)
a = "hi"
print(a.upper())
#6) 대문자 -> 소문자(lower)
a = "HI"
print(a.lower())
#7) 왼쪽 공백 지우기(lstrip)
a = " hi "
print(a.lstrip())
#8) 오른쪽 공백 지우기(rstrip)
a = " hi "
print(a.rstrip())
#9) 양쪽 공백 지우기(strip)
a = " hi "
print(a.strip())
#10) 문자열 바꾸기(replace)
a = "life is too short"
print(a.replace("life", "your leg"))
#11) 문자열 나누기(split)
a = "life is too short"
print(a.split())#아무값 안넣을 시 공백(스페이스,탭,엔터 등)
b ="a:b:c:d"
print(b.split(":"))
3.리스트 자료형(list)-array in python(파이썬에서는 배열의 역할)
리스트 만드는 법
odd =[1,3,5,7,9]처럼 대괄호를 감싸 만든다.
리스트의 인덱싱(indexing)과 슬라이싱(slicing)
# 1) 리스트의 인덱싱
a =[1,2,3]
print(a[0])
print(a[2])
print(a[-1])
print(a[0] + a[2])
b= [1,2,3,['a','b','c']]
print(b[0])
print(b[3])
print(b[3][0])#'a'와 같고, b[-1][0]와도 같다
# 2) 리스트의 슬라이싱
a = [1,2,3,4,5]
print(a[0:2])#[1,2]0<= a <2라는 뜻
print(a[:2])#처음부터 1까지 == [1,2]
print(a[2:]) #2부터 마지막 까지 == [3,4,5]
리스트 연산하기
#1) 리스트 더하기 (+) //요소가 같은 자료형 일 때만 가능
a = [1,2,3]
b = [4,5,6]
print("1)", a+b)
#2) 리스트 반복하기 (*)
a = [1,2,3]
print("2)", a * 3)
#3) 리스트 길이 구하기
a = [1,2,3]
print("3)", len(a))
리스트의 수정과 삭제
#1) 리스트 수정
a = [1,2,3]
print("1)", a[2])
print("1)", a)
#2) del 함수 사용해 리스트 요소 삭제
a = [1,2,3]
del a[1]
print("2)", a)
print("2)", a[1])
b= [1,2,3,4,5]
del b[2:]
print("3)", b)
리스트 관련 함수
#1) 리스트에 요소 추가(append)
a = [1,2,3]
a.append(4)
print("1)", a)
a.append([5,6])
print("1)", a) #리스트 안에는 어떠한 자료형도 추가 할 수 있다.
#2) 리스트 정렬(sort)
a = [1,4,3,2]
a.sort()
print("2)", a)
b = ['a','x','d']
b.sort()
print("2)", b)
#3) 리스트 뒤집기(reverse)
a = ['a','b','c']
a.reverse()
print("3)", a)
#4) 위치 반환(index)
a = [1,2,3]
print("4)", a.index(3)) #3은 리스트 a의 3번 째(a[2])요소 == 3
try:
print(a.index(0))
except:
pass#0은 리스트 a에 존재 하지않으므로 오류
#5) 리스트에 요소 삽입(insert)
#insert(a,b)는 리스트의 a번째 위치에 b를 삽입하는 함수이다. 파이썬에서는 숫자를 0부터 센다.
a =[1,2,3]
a.insert(0,4)
print("5)",a)
a.insert(3,5)
print("5)",a)
#6) 리스트 요소 제거(remove)
a = [1,2,3,1,2,3]
a.remove(3)
print("6)",a)
#7) 리스트 요소 끄집어내기(pop)
#pop()은 리스트의 맨 마지막 요소를 돌려주고 그 요소는 삭제한다.(스택(stack)의 맨 위에 거를 끄내는 것과 같다.)
a = [1,2,3]
a.pop()
print("7)", a)
#pop(x)는 리스트의 x번째 요소를 돌려주고 그 요소는 삭제한다.
a=[1,2,3]
a.pop(1)
print("8)", a)
#8) 리스트에 포함된 요소 x의 개수 세기(count)
#count(x)는 리스트 안에 x가 몇 개 있는지 조사하여 그 개수를 돌려주는 함수이다.
a = [1,2,3,1]
a.count(1) == 2
#9) 리스트 확장(extend)
#extend(x)에서 x에는 리스트만 올 수 있으며 원래의 a 리스트에 x리스트를 더하게 된다.
a = [1,2,3]
a.extend([4,5])
print("9)", a)
b = [6,7]
a.extend(b)
print("9)", a)
#a.extend([4,5])는 a+=[4,5]와 결과물은 동일하지만 a 에다가 [4,5]를 더하면 주소값이 달라진다.
#(a.extend([4,5])는 주소값이 그대로이다. // id(a)를 통해 확인.)
4. 튜플 자료형(tuple)
튜플(tuple)은 몇 가지 점을 제외하곤 리스트와 거의 비슷,
리스트와 튜플의 다른점
1) 리스트는 []으로 둘러싸지만 튜플은 ()으로 둘러싼다.
2) 리스트는 그 값의 생성.삭제.수정이 가능하지만 튜플은 그 값을 바꿀 수 없다.
#값을 변화시킬 수 있는지의 여부가 리스트와 튜플의 큰 차이
튜플 만드는법
t1 = ()
t2 = (1,) #한개만 요소를 가질 때에는 반드시 뒤에 콤마를 붙여야 한다.
t3 = (1,2,3,)
t4 = 1,2,3 #괄호가 없어도 된다.
t5 = ('a','b',('ab','cd'))
튜플 연산하기(다루기)
#1) 인덱싱하기(indexing)
t1 = (1,2,'a','b')
print("1)", t1[0])
print("1)", t1[3])
#2) 슬라이싱하기(slicing)
t1 = (1,2,'a','b')
print("2)", t1[1:])
#3) 튜플 더하기
t2 = (3,4)
print("3)", t1 + t2)
#4) 튜플 곱하기
print("4)", t2 * 3)
#5)튜플 길이 구하기
t1 = (1,2,'a','b')
print("5)", len(t1))
5. 딕셔너리(dictionary)자료형
- 연관 배열(Associative array),해시(Hash) 라고도 불린다.
- key value를 한 쌍으로 갖는 자료형이다.
- 리스트나 튜플처럼 순차적으로 해당 요솟값을 구하지 않고 Key를 통해 Value를 얻는다.
- 순서가 없는 자료형이기 때문에 인덱싱을 지원하지 않는다.
딕셔너리 만드는 법
변수 = {key1:value1, key2:value2, key3:value3, ...}
ex)
a = {1: 'hi'}
a = {'a' : [1,2,3]}딕셔너리 쌍 추가,삭제하기
#1) 딕셔너리 쌍 추가하기
a = {1: 'a'}
a[2] = 'b'#여기서 2는 key, b는 값
print("1)", a)
print("1)", a[1])#변수[키] == 값
print("1)", a[2])#변수[키] == 값
#2) 딕셔너리 요소 삭제하기
del a[1] #del 변수[key] 처럼 사용하여 요소 삭제
print("2)", a)
#딕셔너리는 리스트나 튜플에 있는 인덱싱 방법을 적용할 수 없다.
딕셔너리 만들 때 주의할 사항
1) key는 고유한 값이므로 중복되는 Key값을 설정해 놓으면 하나를 제외한 나머지 것들이 모두 무시된다.
a = {1:2,1:3,1:4}
print(a)
2)key에 리스트는 쓸 수 없다. 하지만 튜플은 Key로 쓸 수 있다.
딕셔너리 관련 함수
#1) key 리스트 만들기(keys)
#변수.keys()는 딕셔너리 변수의 key만을 모아서 dict_keys객체를 돌려준다.
a = {'name': 'pey','phone':'01012345678','birth':'1111'}
print("1)", a.keys())
#dict_keys객체를 list로 변환 하려면
#list(변수.keys())로 변환하면 된다.
#2) value 리스트 만들기(values)
#변수.values()는 딕셔너리 변수의 value만을 모아서 dict_values객체를 돌려준다.
print("2)", a)
#3) key,value 쌍 얻기(items)
#items 함수는 key와 value의 쌍을 튜플로 묶은 값을 dict_times 객체로 돌려준다.
print("3)", a.items())
#4) key:value 쌍 모두 지우기(clear)
#clear 함수는 딕셔너리 안의 모든 요소를 삭제한다.
a.clear()
print("4)", a)
#5) key로 value 얻기(get)
#get(key) 함수는 key에 대응되는 value를 돌려준다. 변수['key']와 값은 값을 나타낸다.
a = {'name': 'pey','phone':'01012345678','birth':'1111'}
print("5)", a.get('name'))
print("5)", a.get('phone'))
#변수.get('없는 키','디폴트 값')을 사용하면
#없는 키를 get하려고 했을 때 디폴트 값으로 출력된다.
#6) 해당 key가 딕셔너리 안에 있는지 조사하기(in)
#key를 검색하여 있으면 true, 없으면 false를 돌려준다.
print("6)", 'name' in a)
print("6)", 'email' in a)
6. 집합(set) 자료형
집합 자료형을 만드는 법
s1 = set([1,2,3])
print(s1)
s2 = set("Hello")
print(s2)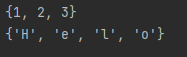
집합 자료형의 특징
- 중복을 허용하지 않는다.
- 순서가 없다(unordered),표기는 오름차순 정렬되어 나옴.
- 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없다.
교집합,합집합,차집합 구하기
s1 = set([1,2,3,4,5,6,])
s2 = set([4,5,6,7,8,9])
#1)교집합
print("1)", s1 & s2)
print("1)", s1.intersection(s2))
#2)합집합
print("2)", s1 | s2)
print("2)", s1.union(s2))
#3)차집합
print("3)", s1 - s2)
print("2)",s1.difference(s2))
집합 자료형 관련 함수
#1)값 1개 추가하기(add)
s1 = set([1,2,3])
s1.add(4)
print("1) ", s1)
#2)값 여러 개 추가하기(update)
s1 = set([1,2,3])
s1.update([4,5,6])
print("2) ", s1)
#3)특정 값 제거하기(remove)
s1 = set([1,2,3])
s1.remove(2)
print("3) ", s1)
7. 불(boolean) 자료형
불 자료형이란
불(bool) 자료형이란 참과 거짓을 나타내는 자료형
print(1 == 1)
print(2 > 1)
print(2 < 1)
자료형의 참과 거짓

불 연산
print("1)", bool('python'))
print("2)", bool(''))
print("3)", bool([1,2,3]))
print("4)", bool([]))
print("5)", bool(0))
print("6)", bool(3))
8. 자료형의 값을 저장하는 공간, 변수
변수란?
파이썬에서 사용하는 변수는 객체를 가리키는 것.
a = [1,2,3][1,2,3]값을 가지는 리스트 자료형(객체)이 자동으로 메모리에 생성되고 변수 a는 [1,2,3]리스트가 저장된 메모리의 주소를 가리키게 된다.
id(a) == 주소값 #id함수는 변수가 가리키고 있는 객체의 주소 값을 돌려주는 파이썬 내장 함수이다.
리스트를 복사할 때
#1) 동일한 주소로 복사할 경우
a = [1,2,3]
b = a#값, 주소 완전 동일하다
print("1)", id(a) == id(b))
print("1)", a is b)
#2) 다른 주소로 복사할 경우
#[:]사용
a = [1,2,3]
b = a[:]
print("2)", a[1])
print("2)", a)
print("2)", b)
#copy모듈 사용
from copy import copy
a = [1,2,3]
b = copy(a)
print("3)", a)
print("3)", b)
print("3)", b is a)#값은 같지만 주소가 다르다.
변수를 만드는 여러 가지 방법
#1)
a,b = ('python','life')
print("1)", a, b)
(a,b) = 'python','life' #위의 만드는 방법과 완전히 동일하다.(튜플은 괄호를 생략해도 되기때문에.)
print("1)", a, b)
[a,b] = ['python','life'] #리스트로 만든 변수
print("1)", a, b)
#2)
a = b ='python'
print("2)", a, b)
#3)
a,b =b,a #(swap)
print("3)", a)
print("3)", b)
'language > Python' 카테고리의 다른 글
| python 2 vs python 3 주요 차이점 (0) | 2021.08.19 |
|---|---|
| [Python] 조건문(if)-제어문,분기문과 차이, 반복문(while문,for문), 예외처리(try, except, else, finally) 개념과 예제 (0) | 2021.01.13 |
| [Python] (Web Scraping, 데이터 크롤링) Selenium vs Scrapy vs Beautiful Soup (0) | 2021.01.12 |
| [Python] lxml이란? (0) | 2021.01.12 |
| [python]파이썬이란? 파이썬으로 할 수 있는 것들과 할 수 없는 것들 (0) | 2021.01.03 |



댓글