인덱스(index)
-인덱스는 데이터의 저장(INSERT,UPDATE,DELETE)의 성능을 희생하는 대신에, 데이터의 읽기(SELECT)속도를 높이는 기능이다.
-MySQL에서는 B-TREE 알고리즘 HASH 알고리즘, FRACTAL-TREE알고리즘 및 R-TREE알고리즘이있다.
1)B-Tree 알고리즘:
가장 일반적으로 사용되는 알고리즘으로 컬럼을 변형하지 않고, 원래의 값을 이용해 인덱싱하는 알고리즘
2)Hash 알고리즘:
컬럼의 값으로 해시 값을 인덱싱하는 알고리즘으로 매우 빠른 검색을 지원.
값을 변형해서 인덱싱하므로 전방일치와 같이 값의 일부만 검색하고자 할 때는 인덱스를 사용할 수 없다.
B-Tree Index
-B-Tree 인덱스는 가장 범용적인 목적으로 사용되는 인덱스
-최상위에 하나의 루트노드가 존재, 그 하 위에 자식 노드가 붙어있는 형태이다.
-트리 구조의 가장 하위에는 리프 노드라고 하고,
트리구조에서 루트노드도 아니고 리프노드도 아닌 중간의 노드를 브랜치 노드라고 한다.
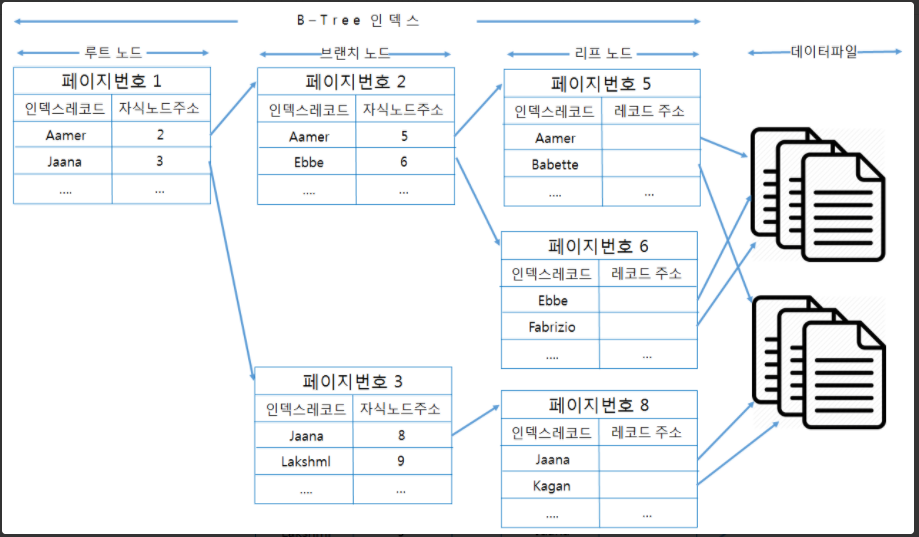
-인덱스는 테이블의 키 컬럼만 가지고 있으므로, 나머지 컬럼을 읽으려면 데이터 파일에서 해당 레코드를 찾아야 한다.
-B-Tree 인덱스의 리프노드는 항상 실제 데이터의 레코드를 찾아가기 위한 주소값을 가지고있고,
InnoDB 스토리지 엔진을 사용하는 테이블에서는 PK에 의해 클러스터링 되기 때문에 PK값 자체가 레코드를 찾아가기 위한 주소 역할을 한다.
B-Tree 인덱스를 통한 데이터 읽기
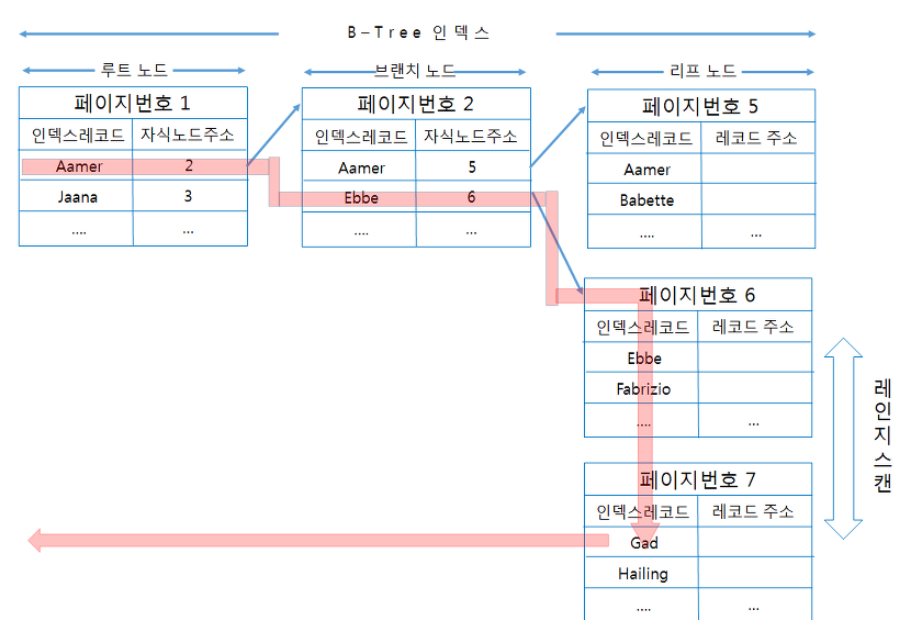
1)index range scan
-검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식
-인덱스의 범위를 결정하려면 시작지점을 알아야하는데, 시작지점을 알려면 루트노드에서부터 비교를 시작해 브랜치 노드를 거치고 리프노드까지 찾아 들어가야만 알 수 있다.
-만약 스캔하다가 리프노드의 끝까지 읽으면 리프노드간의 링크를 이용해 다음 리프노드를 찾아서 다시 스캔한다.
-최종적으로 스캔을 멈춰야할 위치에 다다르면 지금까지 읽은 레코드를 사용자에게 반환하고 쿼리를 끝낸다.
-리프 노드에 저장된 레코드 주소로 데이터파일의 레코드를 읽어오는데 레코드 1건 단위로 랜덤I/O가 한번씩 실행된다.
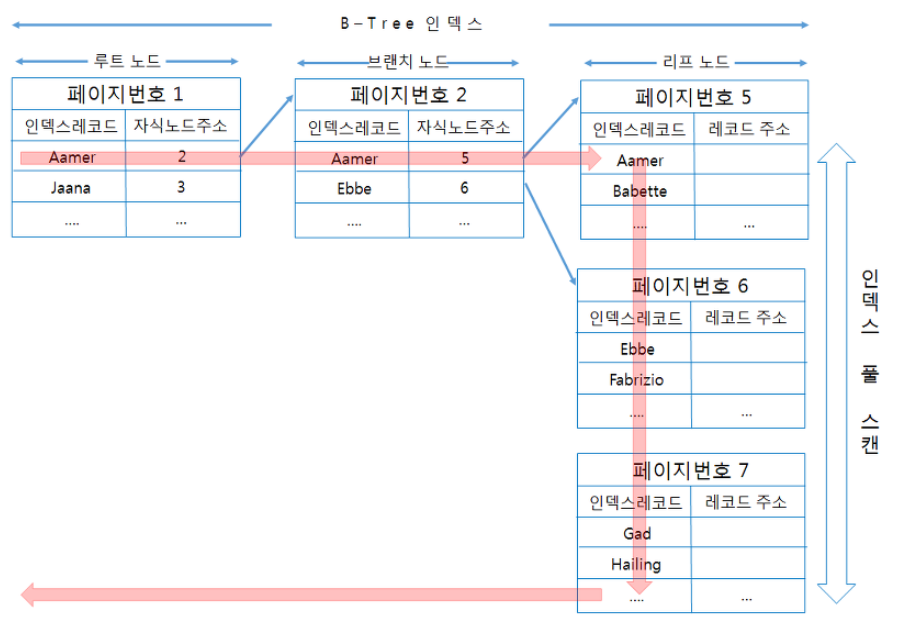
2)index full scan
-인덱스 풀 스캔은 인덱스의 처음부터 끝까지 모두 읽는 방식을 의미한다.
-쿼리의 조건절에 사용된 컬럼이 인덱스의 첫번째 컬럼이 아닌 경우 인덱스 풀 스캔 방식을 사용한다.
-인덱스는(A,B,C) 컬럼의 순서대로 만들어져 있지만 쿼리의 조건절은 B컬럼이나 C컬럼으로 검색하는 경우이다.
-쿼리가 인덱스에 명시된 컬럼만으로 조건을 처리 할 수 있는 경우에도 이 방식을 사용
-인덱스뿐만아니라 데이터 레코드까지 읽을때는 이 방식으로 절대 처리하지 않는다.
-index range scan 보다는 빠르지 않지만 table full scan 보다는 효율적이다.
3)loose index scan
-index range scan과 비슷하게 작동하지만 중간마다 필요치 않은 인덱스 키값은 무시하고 다음으로 넘어가는 형태로 처리
-일반적으로 GROUP BY 또는 집합 함수 가운데 MAX,MIN 함수에 대해 최적화를 하는 경우에 사용됨.



4)multi column index
-다중 컬럼 인덱스에서 중요한것은 인덱스의 두번째 컬럼은 첫번째 컬럼에 의존해서 정렬돼 있다는 것.
-두번째 컬럼의 정렬은 첫번째 컬럼이 똑같은 레코드에서만 의미가 있다.(인덱스 내에서 각 컬럼의 위치가 상당히 중요)

출처:
'DataBase' 카테고리의 다른 글
| [Database] Upsert란? DBMS 별 Upsert 예제 (0) | 2022.06.27 |
|---|---|
| [DataBase] (Oracle vs MySQL) CTAS(Create Table As Select), INSERT INTO SELECT, TEMP Table, View + with절,Inline view (0) | 2022.06.15 |
| [DataBase] MySQL 아키텍처(구조) (0) | 2021.01.18 |
| [DataBase] DBMS별 function 비교(ms-sql(sql-server),oracle,mysql) (0) | 2021.01.18 |
| [DataBase] MySQL,Oracle의 데이터베이스 계층 구조 비교 (0) | 2021.01.18 |



댓글