이번 포스트는 windows 10에 jupyter notebook에 pyspark 개발환경을 구축해보겠습니다.
1. java 설치 확인 or java 설치
spark는 scala로 구현되어 jvm 기반으로 동작하기 때문에 java를 설치해야 합니다.
Java 8 version이 설치되어 있는 지 확인합니다.
1-1 java 설치 확인 or java 설치
Java가 설치되어 있고, 환경변수가 올바르게 설정되어 있다면,
명령 프롬프트(CMD)를 켜고 java –version
- 새로운 session 즉, 환경변수 적용된 이후의 새로운 CMD(명령프롬프트)창부터 환경변수는 적용

만약, java가 설치되어 있지 않다면, https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html URL에서 다운로드

1-2 java 환경변수 설정
제어판-시스템-고급 시스템 설정-환경 변수

시스템 변수-새로 만들기-JAVA_HOME 추가해서 JDK가 설치된 경로와 jdk파일 입력
(대부분 C:\Program Files\Java\의 경로에 설치되어 있습니다.)

시스템 변수-path-편집-새로 만들기- %JAVA_HOME%\bin 입력

cmd창을 열어 java -version으로 java설치와 환경변수 설정이 올바르게 됐는지 확인합니다.
2. spark 설치
spark version에 따라 호환되는 프로그래밍 언어의 version이 있기 때문에 spark 2.3 version은 python 2.7+/ python 3.4+ 이여야 합니다.
(spark 3.0 version은 python 3.6+이여야 합니다.)
*현재의 version은 3.0 이상으로 올라가있으며, vesion은 워낙 빠르게 업그레이드 되므로 해당 버전에 맞는 버전으로 적용하여 다운하시면됩니다.
2-1 spark 다운로드
http://spark.apache.org/downloads.html 에서 spark 2.4.7 version 다운로드


2-2 다운로드 받은 spark-2.4.7-bin-hadoop2.7tgz 파일 압축해제(현재,2021-07-24 spark-3.1.2-bin-hadoop2.7 version이고 계속 바뀔것이므로 맞는 버전으로 실행 해주세요)
(저 같은 경우에는 c 드라이브에 spark 디렉토리를 생성해서 그 안에 다운받은 spark-2.4.7-bin-hadoop2.7.tgz 파일을 넣어 놨습니다.)
1) 명령 프롬프트(CMD)창을 연다.
2) cd spark-2.4.7-bin-hadoop2.7.tgz 파일이 있는 위치 (저 같은 경우엔 cd C:\spark)
tar xzf spark-2.4.7-bin-hadoop2.7.tgz 로 압축해제

(알집으로 압축 푸셔도됩니다!)
2-3 spark 환경변수 설정
위에 java 환경변수 설정한 것처럼 시스템 환경변수 창에서,
시스템 변수에 아래의 항목 추가
SPARK_HOME = C:\spark\spark-2.4.7-bin-hadoop2.7
HADOOP_HOME = C:\spark\spark-2.4.7-bin-hadoop2.7
(스파크를 다운받고 압축해제후에 폴더가 하나 더 있을 수 있는데, 상위 디렉토리로 합쳐서 위와 같이 디렉토리 구조가 될 수 있도록 해주세요)
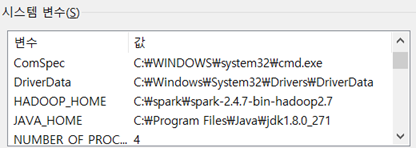

시스템 변수의 path 편집 - %SPARK_HOME%\bin 추가

3.winutils.exe 다운로드
https://github.com/steveloughran/winutils
압축 폴더를 다운받습니다.

이후 압축해제 -> hadoop-2.7.1 폴더 -> bin -> winutils 파일을 C:\spark\spark-2.4.7-bin-hadoop2.7\bin(설치경로)에 옮깁니다.

4. jupyter notebook(lab)설치
4-1 anaconda 다운로드
https://repo.anaconda.com/archive/ 해당 URL에서 Anaconda3-5.2.0-Windows-x86_64.exe 다운로드

4-2 jupyter notebook 설치 확인
시작-anaconda3 파일에서 확인 OR 검색으로 jupyter notebook을 쳐도 나옵니다.



4-3 jupyter lab 확인
URL을 Localhost:8888/tree -> localhost:8888/lab 으로 바꿔서 들어간다. jupyter lab 확인

4-4 python 경로 설정하기
Anaconda3를 설치하면서 python3.6.5 버전이 설치 되었으므로 환경변수에 anaconda 경로를 설정해줍니다.
(대부분 C드라이브의 자신의 계정에 anaconda3폴더가 있습니다.)
(MY는 자신의 계정)

5.Spark 확인
- 재부팅하여 환경 변수 적용시킵니다.
- CMD 프롬프트창에서 spark-shell 명령어로 scala spark 확인
- CMD 프롬프트창에서 pyspark 을 쳐서 pyspark 설치 확인
- 새로운 session 즉, 환경변수 적용된 이후의 새로운 CMD(명령프롬프트)창부터 환경변수는 적용


6. findspark 패키지 설치
6-1 findspark 패키지란?
- Pyspark는 sys.path에 default로 등록되어 있지 않기 때문에, 보통의 라이브러리처럼 import하려면 findspark 패키지를 통해 runtime동안에만 sys.path에 등록할 수 있게 해준다
- 즉, findspark 패키지의 findspark.init()을 함으로써 pyspark 라이브러리를 보통의 라이브러리처럼 import할 수 있게 해주는 패키지
- pyspark shell로 개발을 하거나, hadoop cluster의 yarn을 이용해 pyspark job을 제출할 때에는 필요하지 않다
6-2 findspark 패키지 설치하기
우리는 sys.path에 pyspark를 등록하는 작업을 하지 않았기 때문에, findspark 패키지를 다운로드하여 jupyter lab환경에서 개발해야 합니다.
- jupyter notebook - jupyter lab - new launcher - terminal

|
1
|
pip install findspark
|
cs |

- findspark 설치된 것 확인

6-3 findspark 설치 확인 및 import pyspark, sparksession 드라이버 프로세스 얻기
- 노트북을 생성

|
1
2
3
4
5
6
7
8
9
10
11
|
import findspark
findspark.init()
from pyspark.sql import SparkSession
#sparksession 드라이버 프로세스 얻기
spark = SparkSession.builder.appName("sample").master("local[*]").getOrCreate()
#클러스터모드의 경우 master에 local[*] 대신 yarn이 들어간다.
spark.conf.set("spark.sql.repl.eagerEval.enabled",True)
#jupyter환경에서만 가능한 config, .show()메소드를 사용할 필요없이 dataframe만 실행해도,정렬된 프린팅을 해준다.
|
cs |

6-4 pyspark 간단한 사용 예제(6-3을 수행해야 실행가능)
|
1
2
3
4
5
6
7
8
|
#간단한 예제 1
df= spark.range(500).toDF("number")
df.select(df["number"]+10)
#간단한 예제 2
from pyspark.sql.functions import expr
expr("(((someCol + 5) * 200) - 6) < otherCol")
|
cs |


*2021-06-07 수정
*2021-11-23 수정( scala version spark-shell 확인 추가)
*2021-12-01 수정( findspark 다운로드 방법 변경, 예제 사진 변경,code scripter 사용)



댓글