이번 포스트에는 Hive의 가장 큰 특징인 Hive MetaStore, 그리고 bigdata를 다루는데 있어서 중요한 Partition에 관해서 정리 해보겠습니다. 중요한 내용이니 만큼 내용이깁니다.
*Hive의 개념을 모르신다면 아래를 참조해주세요
2021.07.12 - [BigData] - [Hive] Hive란?(1) 개념, 구성요소, 등장배경, 버전
[Hive] Hive란?(1) 개념, 구성요소, 등장배경, 버전
1. Hive란? -하이브는 하둡 에코시스템 중에서 데이터를 모델링하고 프로세싱하는 경우 가장 많이 사용하는 데이터 웨어하우징용 솔루션입니다. -RDB의 데이터베이스, 테이블과 같은 형태로 HDFS에
spidyweb.tistory.com
1. Hive Metastore란?
- 데이터 파일의 물리적인 위치, Hive의 테이블, 파티션과 관련된 메타정보를 모두 저장하는 곳 이다.
- Hive의 metastore는 빅데이터의 ‘우선 데이터가 있고, 나중에 스키마를 입힌다’ 의 개념에 딱 맞는 개념
- Hive는 기존의 RDBMS와 달리 데이터를 insert후 스키마를 입히게 되는데, 그때 Schema 정보를 metastore에서 참조한다.
- HDFS에 있는 데이터에 스키마를 참조 할 수 있는 데이터베이스이며, 기존의 RDBMS로 metastore를 지정한다. (derby, mysql, oracle, postgresql 등등)
2. Metastore Type
1) 임베디드 메타스토어(embedded metastore)
- Hive를 설치하면 기본적으로 embedded metastore를 사용한다.(실제 환경에서 사용X)
- 보통 DerbyDB가 embedded metastore default DB로 설정한다.
2) 로컬 메타스토어(local metastore)
- 로컬 메타스토어의 경우 메타데이터가 모두 원격(또는 로컬)의 데이터베이스에 저장한다.
- hive와 동일한jvm에서 동작, 메타 데이터는 외부의 RDBMS에 저장
- ex) mysql, postgresql 등
3) 원격 메타스토어(remote metastore)
- 로컬 메타스토어와는 달리 메타스토어가 별도의 jvm에서 동작되며, 클라이언트는 데이터베이스에 직접 쿼리문을 날리는 대신 메타스토어 서버의 중개를 받는다(thrift protocol을 통해 접속)

3. Managed table(Internal table) vs External table
- 메타스토어에 저장되는 정보중에 테이블의 종류를 지정하는 정보가 있습니다.
- Create Table시에 테이블의 종류를 지정합니다.
1) Managed Table(Internal table)
- 생성 시 location이 hive.metastore.warehouse.dir 속성이 가르키는 directory에 저장되는 테이블
- 기본적으로 /user/hive/warehouse/databasename.db/tablename/ 위치에 저장된다.
- location 속성을 통해 테이블의 위치를 변경해 줄 수 있다
- DROP table 혹은 DROP PARTITION 시, 메타스토어의 정보와 데이터가 함께 삭제되는 테이블
- 수명주기를 관리해야 하거나, 임시테이블을 생성할 때 사용
2) External table
- 외부테이블은 외부 파일의 메타 데이터/스키마를 설명하는 테이블
- 테이블 생성 시 location을 지정 해야되는 테이블
- 파일이 이미 있거나, 원격 위치(S3,원격 HDFS)에 있을 때 사용
- DROP table 혹은 DROP PARTITION 시, 메타스토어의 정보만 삭제되고, 데이터와 디렉토리는 남아있는 테이블
4. Partitioned table Vs Non Partitioned table
- 파티션: 메타스토어에 저장되는 정보중의 하나로, 데이터를 디렉토리로 분리하여 저장하는 기법
- 파티션이 필요한 이유 → 하이브 같은 파일 기반 테이블은 기본적으로 테이블의 모든 row 정보를 읽기 때문에 데이터가 많아지면 속도가 느려집니다. 파티션 칼럼은 where 조건에서 칼럼 처럼 이용할 수 있기 때문에 처음에 읽어 들이는 데이터를 줄여서 처리 속도를 향상
1) Partitioned table
- 테이블을 하나 이상의 키로 파티셔닝(partitioning) 즉, 물리적으로 분할된 테이블
- 테이블 생성 시 partitioned by (columnname datatype) 으로 생성된 테이블
- 파티션 사용 유무를 정할 수 있지만, row가 많은 *fact table 같은 경우는 선택이 아닌 필수
- 파티션 키의 순서에 따라 HDFS 상의 directory 구조가 결정됨으로 워크로드에 따라 그 순서도 적절히 결정해야 한다
2) Non Partitioned table
- 테이블이 물리적으로 분할 되어 있지 않은 테이블
- 테이블 생성 시 partitioned by (columnname datatype)으로 파티션을 지정하지 않은 테이블
- 일반 테이블이 곧 non partitioned table
*fact table,dimension table이란?
2021.08.06 - [BigData] - [BigData] 마스터 데이터 vs 트랜잭션 데이터, fact테이블 vs dimension 테이블, 시계열 데이터란?
[BigData] 마스터 데이터 vs 트랜잭션 데이터, fact테이블 vs dimension 테이블, 시계열 데이터란?
마스터 데이터란? 트랜잭션 데이터란? 트랜잭션 데이터(transaction data): -시간과 함께 생성되는 데이터를 기록한 것 -한 번 기록하면 시간과 함께 생성되기에 변화하지 않는다. ex) 판매 이력 마스
spidyweb.tistory.com
5. Partitioned table이 필요한 이유
1) 성능적인 측면
- 빅데이터의 세계는 데이터의 단위자체가 TB, PB 이상의 단위 이기 때문에 I/O에 민감 → 테이블을 파티션 단위로 물리적 분리를 하여 쿼리를 할 때, 테이블 full scan을 피하고 원하는 값의 파티션만 탐색하면 되므로, 성능을 높인다.(불필요한 I/O를 최소화 시킵니다)
- 테이블의 크기가 커질 수록 성능차이는 커진다.
2) 관리적인 측면
- 파티션 단위 백업, 추가, 삭제, 변경으로 관리하기에 용이함
Ex)
1. 보관주기가 지난 데이터를 별도 장치에 백업하고 지우는 일에 있어서 효율적
2. 대용량 테이블에 인덱스를 새로 생성하거나 재생성 할 때도 효율적
6. Partition 종류, 정적 파티션(static partition) vs 동적 파티션(dynamic partition)
1) 정적 파티션(static partition)
- 테이블에 데이터를 입력하는 시점에 파티션 정보를 전달
ex)
|
1
2
3
4
5
|
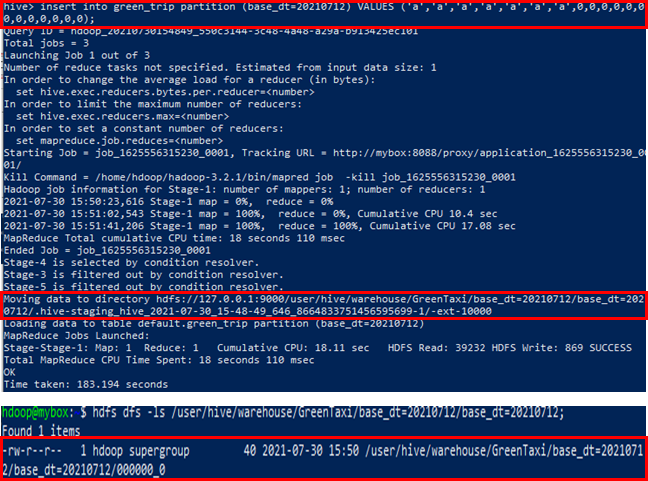
INSERT INTO TABLE tgttbl Partition (base_dt='20210713')
SELECT values
FROM srctable;
|
cs |
- 위와 같이 정적으로 파티션을 생성할 경우 HDFS://[tbl 테이블 로케이션]/base_dt=20210713/과 같은 폴더 구조로 데이터를 생성


2) 동적 파티션(dynamic partition)
- 칼럼의 정보를 이용하여 동적으로 파티션이 생성
ex)
|
1
2
3
4
|
INSERT INTO TABLE tgttbl Partition (base_dt)
SELECT values
,base_dt 값
FROM srctable;
|
cs |
- 위와 같이 동적으로 파티션을 생성할 경우 base_dt의 값에 따라 파티션이 생성되고, HDFS의 폴더 구조도 그에 맞게 디렉토리 생성, 데이터를 생성
- Ex) base_dt의 값이 20210714일 경우 Hdfs://[tbl 테이블 로케이션]/base_dt=20210714/ 의 구조가 된다.

7. Partition 조작, 정석 vs MSCK
1) 정석적인 방법
- ADD PARTITION (추가)
|
1
|
ALTER TABLE tablename ADD PARTITION (base_dt=20210712) location ‘/user/hive/warehouse/GreenTaxi/base_dt=20210712’;
|
cs |
- DROP PARTITION (제거)
|
1
|
ALTER TABLE tablename DROP PARTITION (base_dt=20210712);
|
cs |
- Partitioned by (columnname datatype) (파티션 테이블생성)
|
1
2
3
4
5
6
7
8
|
Create table test1(
col1 int,
col2 string
) partitioned by (base_dt string);
|
cs |
2) MSCK(MetaStore ChecK)
- Hive metastore에 Hive partition이 저장되어 있지 않을 때, 말 그대로 테이블을 수리하는(Hive table의 partition을 metastore에 저장하는)작업
- HDFS의 구조에 맞게 메타 정보 전체를 업데이트(추가)
|
1
2
|
MSCK REPAIR TABLE tablename;
|
cs |
8. location 속성
- 메타스토어에 저장되는 정보 중 하나
- Location 속성은 실제 데이터(파일)가 위치한 곳을 정의하는 속성
- External table, Managed table 모두 location을 지정 할 수 있고, 하지 않을 수도 있다.
- location을 지정 하지 않을 시 hive.metastore.warehouse.dir 속성이 가르키는 directory가 default로 location이 저장된다.
- Table의 location 뿐 만 아니라, Partition의 location도 생성, 변경 해 줄 수 있다.
9. Location 속성 조작해보기
1) table의 location 지정
- table을 생성할 때 location을 지정
|
1
2
3
4
5
|
partitioned by (base_dt String)
row format delimited
fields terminated by ','
location '/user/hive/warehouse/GreenTaxi/‘;
|
cs |
*위의 location부분이 location 속성 부분

2) table의 location 변경
|
1
2
|
ALTER TABLE green_trip set location '/user/hive/warehouse';
|
cs |
- 위와 같이 테이블의 location을 재지정


3) Partition의 location 지정 및 변경
- ALTER TABLE ADD PARTITION 구문으로 파티션을 메타스토어에 추가할 경우 location을 지정해 주어야 한다.
|
1
|
ALTER TABLE green_trip PARTITION (base_dt=20210712) SET LOCATION '/user/hive/warehouse/';
|

- partition은 msck repair table로 메타스토어에 자동 추가를 할 경우 partition의 location은 자동으로 해당 partition 디렉토리로 지정됨
ex)
|
1
2
|
--base_dt=20210712 라는 디렉토리가 있다고 가정
msck repair table green_trip ;
|
→ base_dt=20210712 partition은 location이 /user/hive/warehouse/GreenTaxi/base_dt=20210712 로 지정
10. Location 속성 주의사항
1) Table location과 Partition location을 혼동하면 안 되는 이유 사례 1
- table의 location을 partition의 location에 주게 된다면?
→ table location: /user/hive/warehouse/GreenTaxi/base_dt=20210712으로 지정
→ select * from green_trip; 쿼리를 실행시켜도 테이블 전체의 데이터가 조회되는 것이 아닌, 20210712 파티션에 해당하는 데이터만 조회될 것
2) Table location과 Partition location을 혼동하면 안 되는 이유 사례 2
|
1
2
|
ALTER TABLE green_trip DROP IF EXISTS PARTITION (base_dt=20210712);
ALTER TABLE green_trip ADD IF NOT EXISTS PARTITION (base_dt=20210712);
|
위의 두 개의 DDL문이 ETL script에 들어 있고 이게 실행된다면?
→현재 table의 base_dt=20210712 partition이 메타스토어에 등록되어 있다면,
ALTER TABLE DROP IF EXISTS PARTITION(base_dt=20210712)가 실행되어 메타스토어의 partition정보가 삭제
→테이블의 location을 혼동하여 파티션 location으로 지정 하게 되면,
table location: /user/hive/warehouse/GreenTaxi/base_dt=20210712 이므로
partition location: /user/hive/warehouse/GreenTaxi/base_dt=20210712/base_dt=20210712의 location으로 partition(base_dt=20210712)이 추가

→이후 insert into green_trip partition(base_dt=20210712)라는 쿼리가 ETL script에 있다면, 새로 생겨난 파티션인
/user/hive/warehouse/GreenTaxi/base_dt=20210712/base_dt=20210712 디렉토리에 데이터가 생성
결론:
1.table과 partition의 location을 혼동하게 되면, 원하는 데이터를 조회하지 못한다.11. Hive Partition 예제 및 주의사항
1) 파티션이 key=value 형태
- 현재 /user/hive/warehouse/GreenTaxi/base_dt=20210712의 디렉토리가 존재

- 하지만 green_trip 테이블의 파티션을 조회해보면 나오지 않는다.(메타스토어에 파티션이 등록되어 있지 않다.)

- 파티션을 등록해준다.(ALTER TABLE ADD PARTITION)(정석적인 방법)
|
1
|
ALTER TABLE Green_Trip ADD PARTITION (base_dt=20210712) location ‘/user/hive/warehouse/GreenTaxi/base_dt=20210712’;
|
cs |

- 파티션을 등록해준다.(msck)(차선책,대안)
|
1
2
|
MSCK REPAIR TABLE Green_Trip;
|

- 데이터를 조회해본다.
|
1
2
3
4
|
SELECT *
FROM green_trip
LIMIT 5;
|

- 현재 base_dt=20210712 파티션 안에 데이터가 들어있으므로 select를 해도 정상적으로 나와야 한다.)
- 파티션이 메타스토어에 등록되지 않은 경우라면, 데이터의 조회가 되지 않는다.
2) 파티션이 value 형태
- 현재 /user/hive/warehouse/GreenTaxi/20210712/의 디렉토리에 greentaxi.csv 파일이 들어가 있다.

- Value만 있는 partition directory인 ‘/user/hive/warehouse/GreenTaxi/20210712/’ 디렉토리에base_dt=20210712와 같은 key=value형태의 파티션을 메타스토어에 추가하고 location은 /user/hive/warehouse/GreenTaxi/20210712/로 추가하게 된다면,
|
1
2
|
ALTER TABLE green_trip ADD PARTITION (base_dt=20210712) location ‘/user/hive/warehouse/GreenTaxi/20210712/’;
|
cs |

- 메타스토어에 파티션이 base_dt=20210712로 등록 될 뿐 아니라 해당 디렉토리에 있는 데이터를 참고하게 된다.(즉 metastore에는 key=value와 같은 형태의 파티션으로 등록이 되어야 한다.)
- Hive 의 green_trip 테이블의 현재 등록된 파티션은 없다고 가정하고, msck repair table로 메타스토어에 파티션을 등록 하려고 하면 HDFS의 key=value 디렉토리 구조가 아니라 오류가 발생


- 물론 메타스토어에 파티션이 등록되지 않았으니, 데이터의 조회도 불가능

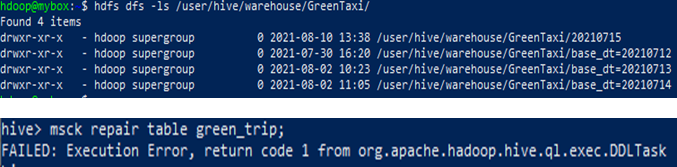
3) 메타스토어에 빠져있는 파티션
- 메타스토어에는 Partition이 한 개만 등록되어 있지만 Partition directory는 3개가 있는 상황

- 위와 같이 메타스토어에 한 개의 파티션만 등록된 경우에는 ALTER TABLE tablename ADD PARTITION (base_dt=20210714 ) location 'partition directory위치‘ 와 같은 방법으로 낱개 별로 추가해 줄 수도 있다.

- MSCK repair table 로 메타스토어에 등록되어 있지 않은 나머지 2개의 partition을 추가 시킬 수 있다.

- MSCK repair table은 이전에 봤듯이 key=value로 이루어져 있지 않은 디렉토리가 존재 한다면 오류를 내게 된다.
4) Partition 예제 주의사항 정리 표
| ALTER TABLE ADD PARTITION | MSCK REPAIR TABLE | |
| Key=value | ALTER TABLE tablename ADD PARTITION 구문으로 직접 location지정하여 추가 | Key=value형태에 어긋난 directory name이 있을 경우 오류 |
| Value | •Key=value partition으로 등록 가능 •value partition으로는 등록 불가능 |
Key=value형태에 어긋난 directory name이기에 오류 |
| 메타스토어에 없는 Partition | ALTER TABLE tablename ADD PARTITION 구문으로 직접 location지정하여 추가 | Key=value형태로만 director가 이루어져 있다면 등록되지 않은 partition들이 등록된다 |
결론:
ALTER TABLE tablename ADD PARTITION 방법(정석)을 우선적으로 사용하고,
MSCK REPAIR TABLE은 불가피 할 때만 사용
*데이터 조회 issue 시 고려해볼 점
1) Source table의 select(데이터 조회)가 안될 때(count도 0건으로 조회)
- 실제 데이터가 HDFS에 저장 안되어 있을 가능성
→ metastore로 부터 스키마가 입혀져 있어서 partition이 metastore에 등록된 상태이지만 데이터 조회가 안 된다면 데이터가 해당 파티션에 없을 가능성이 있습니다.(실제로 데이터가 들어있는지 체크)
- MetaStore에 partition 등록이 안되어 있을 가능성
→ HDFS에는 데이터가 들어 있지만 metastore로부터 스키마가 입혀지지 않아서 조회가 안될 수도 있습니다.
- table, partition의 location이 엉뚱한 곳으로 지정
→ 실제로 스크립트 속에 잘못 지정 되어있는 ALTER TABLE tablename PARTITION (base_dt=20210712) SET LOCATION '로케이션' 과 같은 DDL문이 있을 경우가 있는데, 그렇게 되면 PARTITION의 로케이션에 있는 데이터를 조회하는 것이기 때문에 엉뚱한 데이터가 조회 된다거나, 데이터가 없는 빈 디렉토리 일 경우에는 조회가 안 된다.
2) target table의 data가 select가 안될 때(count도 0건)
- 실제로 source table로 부터 쓰여진 데이터가 없다
→ input data가 있는지,ETL script를 잘못 쓰진 않았는지, partition, table의 location이 잘 설정되어 있는지 확인
- 데이터는 있지만 조회가 안 될때
→ source table과 마찬가지로 target table의 partition과 location check
*2021-10-14 최종수정




댓글