이번 포스트에는 hadoop 설치, 배포, 환경설정, 실행하기를 해보겠습니다.
아직 zookeeper 설치,환경설정,실행을 완료해보지 못했다면 아래의 링크를 참고해주세요.
https://spidyweb.tistory.com/271
[BigData] Centos-7 fully distributed hadoop cluster 구성하기(하둡 클러스터) 6. Zookeeper 설치, 환경설정, 실행
이번 포스트에는 zookeeper 를 설치하고, 환경설정하여 실행 해보겠습니다. 아직 zookeeper 및 hadoop 계정 생성과 권한 설정을 완료하지 못했다면 아래의 링크를 참고해주세요. https://spidyweb.tistory.com/27
spidyweb.tistory.com
하둡 구성 스펙
호스트OS - windows10 home
게스트OS들 - centOS7
Hadoop - 3.1.2
Zookeeper - 3.4.10
jdk - 1.8.0_191
호스트OS는 공유기(WI-FI) 연결 환경
서버 4대를 활용한 하둡 HA 구성:
namenode1: 액티브 네임노드, 저널노드 역할
rmnode1: 스탠바이 네임노드, 리소스 매니저, 저널노드 역할, 데이터 노드 역할
datanode1: 저널노드 역할, 데이터 노드 역할
datanode2: 데이터 노드 역할
총 4개의 노드를 이용하여 HA(고가용성)구성을 한 하둡 클러스터를 구성 해보겠습니다.
1. hadoop 설치하기(namenode1만)
-namenode1에만 설치하여 나머지 노드들에 배포하는 방식으로 하겠습니다.
1) hadoop 계정으로 접속
su hadoop
cd ~
2) hadoop 다운로드
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.1.0/hadoop-3.1.0.tar.gz


3) hadoop폴더 압축 해제
tar xvzf hadoop-3.1.0.tar.gz

4) 하둡 파일 설정 하기
cd /hadoop-3.1.0/etc/hadoop
1. workers
-slave로써 사용할 호스트명을 입력
nano workers
기존에 있던 localhost는 주석처리,
rmnode1
datanode1
datanode2 추가

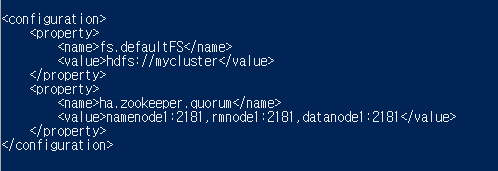
2. core-site.xml
-hdfs와 맵리듀스에서 사용할 공통적인 환경을 설정
nano core-site.xml
아래와 같이 설정 후 저장
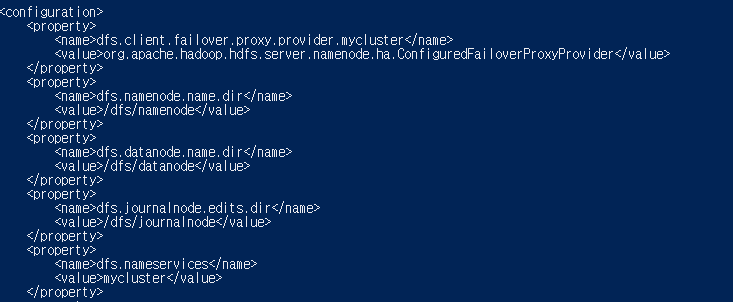
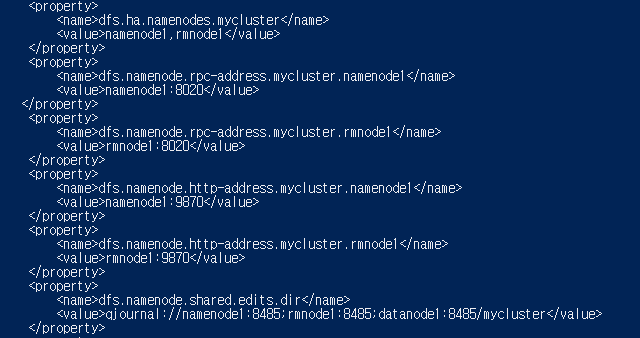
3. hdfs-site.xml
-hdfs에서 사용할 환경을 설정
nano hdfs-site.xml

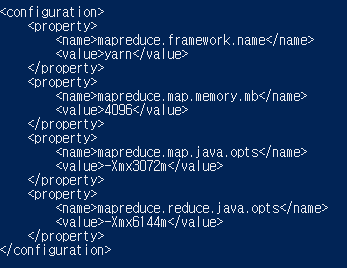
4. mapred-site.xml
-맵리듀스에서 사용할 환경을 설정
nano mapred-site.xml
5. yarn-site.xml
-yarn에서 사용할 환경을 설정
nano yarn-site.xml


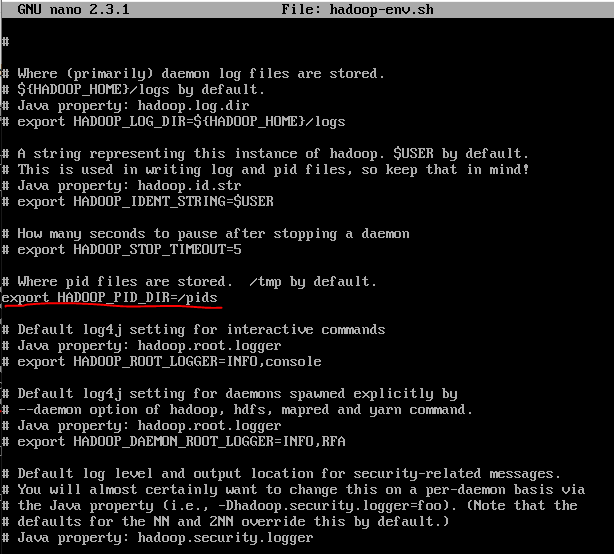
6. hadoop-env.sh
-jdk와 pids 경로를 설정
ctrl +w 로 export JAVA_HOME 치고 찾아가서 주석 제거후 jdk 경로 입력

마찬가지로 export HADOOP_PID_DIR 찾아가서 pid 경로 입력
2. hadoop 재 압축하고 배포하기(namenode1에서만)
1) hadoop 재 압축
cd ~
tar cvfz hadoop.tar.gz hadoop-3.1.0

2)hadoop 배포
scp hadoop.tar.gz hadoop@rmnode1:/home/hadoop
scp hadoop.tar.gz hadoop@datanode1:/home/hadoop
scp hadoop.tar.gz hadoop@datanode2:/home/hadoop

3) hadoop 폴더 압축 풀기(rmnode1,datanode1,datanode2에서만)
tar xvfz hadoop.tar.gz

3. hadoop 환경 변수 설정(4개 노드 전부)
1) root 계정으로 접속
su root
2) /etc/profile 파일 수정
nano /etc/profile

3) /etc/profile 파일 적용
source /etc/profile
4. zookeeper 실행 및 hadoop 실행
1) zookeeper 실행(namenode1,rmnode1,datanode1만.실행 중이라면 건들지 않습니다.)
su zookeeper
cd ~
cd zookeeper-3.4.10
./bin/zkServer.sh start

2) zookeeper 장애 컨트롤러 초기화(namenode1만 최초 한번만 실행)
su hadoop
cd ~
cd hadoop-3.1.0
./bin/hdfs zkfc -formatZK

3) journal node를 실행하기(namenode1, rmnode1, datanode1에서만)
./bin/hdfs --daemon start journalnode

4)namenode 초기화(namenode1만 최초 한번만 실행)
./bin/hdfs namenode -format mycluster

5)active namenode 실행(namenode1만)
./bin/hdfs --daemon start namenode

6)액티브 네임노드(active namenode)용 주키퍼 장애 컨트롤러(zkfc)를 실행(namenode1만)
./bin/hdfs --daemon start zkfc

7)데이터 노드 실행(namenode1만)
hdfs --workers --daemon start datanode



8)standby namenode 포맷(rmnode1만 최초 한번만 실행)
./bin/hdfs namenode -bootstrapStandby

9) standby namenode 실행(rmnode1만)
./bin/hdfs --daemon start namenode

10) standby namenode용 주키퍼 장애 컨트롤러(zkfc)실행(rmnode1만)
./bin/hdfs --daemon start zkfc

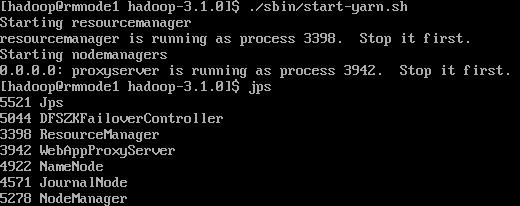
11)yarn cluster 실행(rmnode1만)
./sbin/start-yarn.sh
12)active stanby namenode 확인(namenode1만)
./bin/hdfs haadmin -getServiceState namenode1
./bin/hdfs haadmin -getServiceState rmnode1

13) 각 노드 jps로 확인
jps
14) 이후 작업 start-all.sh 와 stop-all.sh로 전부 실행시키고 끄기
stop-all.sh

start-all.sh

(namenode1)

(rmnode1)

(datanode1)

(datanode2)

이것으로 HA(고가용성)구성으로 하둡 클러스터 구축하기를 완성했습니다.
현재 데이터노드가 start-all.sh로 뜨지않는 점, hdfs --workers --daemon start로 뜨지않는 점, hdfs dfs 명령어가 먹히지않는 에러가 있어서 수정예정입니다.(2021-10-15)→ 수정완료
(완벽하게 이해하고 수정한 내용은 아니라 더 알게되는 내용이 있으면 덧붙여 수정하겠습니다.)
org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: Incompatible clusterIDs 와 같은 에러로 datanode도 뜨지않고 rmnode1과도 format시킬때 연결이 안된다고 log error가 떴었는데, 대부분 하둡이 비정상적으로 종료되었을때 생기는 에러라고 한다.
# 하둡에서 클러스터를 세팅한 후, 네임노드를 reformat할 경우 데이터노드는 예전 네임노드이 reference를 참조하기 때문에 그냥 단순하게 네임노드를 삭제하면 된다.
이를 위해 모든걸 초기화 해주겠습니다.
1) stop-all.sh 로 하둡 종료
2) tmp/hadoop-(자기가설정한것)/dfs 내 data 디렉토리 삭제

위와 같은 에러 로그도 있었는데, /dfs/journalnode/mycluter가 비어있어야 하는 것 같아, 디렉토리를 삭제해주었습니다.
3) 위의 hadoop 키는 순서들을 다시 실행(namenode format을 다시 하는 개념)
*2021-12-06 spark on yarn을 위한 hadoop config cluster 수정




댓글