이번 포스트에는 spark를 yarn을 이용하여 cluster mode로 pyspark job을 제출하고, cluster로 잘 돌았는지 확인해보겠습니다.
hadoop cluster가 구성 안되신 분들은 아래의 링크를 참조해주세요.
2021.08.08 - [BigData] - [BigData] 완전 분산 하둡 클러스터(hadoop cluster)구축하기(4개 노드) 1. 4개의 가상 노드 띄우기
[BigData] 완전 분산 하둡 클러스터(hadoop cluster)구축하기(4개 노드) 1. 4개의 가상 노드 띄우기
이번 포스트에는 하둡 fully-distributed mode 구축을 해보도록 하겠습니다. 하둡 구성 스펙 호스트OS - windows10 home 게스트OS들 - centOS7 Hadoop - 3.1.0 Zookeeper - 3.4.10 jdk - 1.8.0_191 호스트OS는 공..
spidyweb.tistory.com
구성한 hadoop cluster에 spark 를 설치하지 않으신 분들은 아래의 링크를 참조해주세요.
[BigData] 완전 분산 하둡 클러스터(hadoop cluster)(4개 노드) 에 "Spark"(Spark on Yarn cluster) 설치 및 실습
저번 포스트까지는 하둡 클러스터를 구성해보았습니다. 이번 포스트에는 구성된 하둡 클러스터에 Spark를 설치해보겠습니다. 본 포스팅은 standalone모드 4개를 구축하여 spark cluster를 만드는 것이
spidyweb.tistory.com
제출할 job은 단일 노드에서 제출 해본 spark job입니다. 아래의 링크를 참조해주세요.
2021.11.08 - [BigData] - [Spark] spark standalone 모드로 pyspark 실습(.py spark submit)+ui확인하기
[Spark] spark standalone 모드로 pyspark 실습(.py spark submit)+ui확인하기
이번 포스트에서는 spark standalone 모드 즉, yarn을 이용하지 않고 local(단일 노드로) pyspark을 제출하는 .py 파일을 생성해 스크립트 실행을 시켜 제출해보도록 하겠습니다. 하둡 및 스파크를 설치하
spidyweb.tistory.com
하둡 구성 스펙
호스트OS - windows10 home
게스트OS들 - centOS7
Hadoop - 3.1.2
Zookeeper - 3.4.10
jdk - 1.8.0_191
호스트OS는 공유기(WI-FI) 연결 환경
서버 4대를 활용한 하둡 HA 구성:
namenode1: 액티브 네임노드, 저널노드 역할
rmnode1: 스탠바이 네임노드, 리소스 매니저, 저널노드 역할, 데이터 노드 역할
datanode1: 저널노드 역할, 데이터 노드 역할
datanode2: 데이터 노드 역할
pyspark 스펙
spark3.1.2-bin-hadoop3.2
python 3.6.8
실습용 데이터
https://data.cityofnewyork.us/Public-Safety/Motor-Vehicle-Collisions-Crashes/h9gi-nx95
Motor Vehicle Collisions - Crashes | NYC Open Data
data.cityofnewyork.us
뉴욕시티에서 일어난 자동차,오토바이 등 탈 것에 의한 충돌횟수에 대한 데이터
실습 시나리오
1. local에 newyork city crash csv파일을 다운로드 한다.
2-1. hdfs에 source data가 들어갈 directory를 생성한다.
2-2. local에 있는 csv파일을 2-1번에서 생성한 directory에 put한다.
3. pytyon 파일을 작성한다.
- sparksession 생성
- csvfile read하여 df_crash에 저장
- df_crash로 부터 날짜와 시간이 yyyy/MM/dd 와 HH:mm 형식으로 바뀌고, 시간대가 00:00~06:00시에 일어난 사건 중에 지역이 'MANHATTAN'인 곳의 날짜별 시간별 다치거나 사망한 수를 집계하여 df_crash_losses에 저장
- df_crash_losses로 부터 날짜별 부상자 숫자 순위를 메기는 컬럼과 날짜별 사망자 숫자 순위를 메기는 컬럼을 생성해서 날짜별 부상자수가 1위거나 사망자수가 1위인 날짜,시간,부상자수,사망자수를 조회하는 컬럼을 날짜,시간순으로 오름차순 정렬함
- parquet파일로써 file을 write하고, write하는 형식은 overwrite을 사용해서 멱등성을 유지, 날짜별 partition나눠서 file write
4. python 파일을 실행 및 결과 확인
조건
file을 read하는 foramt은 csvforamt으로 읽는다.
file을 write되는 format은 parquet format의 테이블이다.
python 파일은 멱등성(여러번 실행해도 같은 결과가 나오게끔)이 가능하도록 구성한다.
만들고자 하는 것
00:00 시에서 06:00시까지 맨해튼에서 날짜별 시간별 사망자 수가 제일 많거나, 부상자 수가 제일 많은
부상자 수, 사망자 수
(조건: 날짜별,시간별로 오름차순 정렬이 되게끔 하기)
확인 해봐야 될 점(UI관점)
- yarn(Application Master)에 spark job이 제출되었는지
- yarn의 각 노드가 분산 처리 하고있는지(container확인)
- spark config에서 설정한 4개의 executor가 실행되고 있는 지(driver 포함)
- job 이 다 돌면 hdfs에 의도한 데로 쓰여졌는지
- spark job history server에 job이 제출된 이력이 남는지
더 해봐야 할 것
yarn(Application Master)에서 Application master 및 history, log ui에 접속 할 수 있도록 config 재구성하기
1. local에 csv파일 다운로드
위의 사진에서 csv를 우클릭 후 링크 주소 복사를 통해 URL을 복사합니다.
1) 하둡 계정의 root디렉토리에서 wget url
wget이 없다면 wget을 다운 받아야합니다.
wget https://data.cityofnewyork.us/api/views/h9gi-nx95/rows.csv?accessType=DOWNLOAD

2) 생성된 파일 확인 및 이름변경
mv 'rows.csv?accessType=DOWNLOAD' NY_CRASH.csv

2-1. HDFS 디렉토리 생성
1) 하둡을 실행
start-all.sh
2)hdfs에 /user/hadoop/spark 디렉토리 생성
(제 유저 이름은 Hadoop입니다. root 디렉토리가 /User/Hadoop)
hdfs dfs -mkdir /user/spark
hdfs dfs -mkdir /user/spark/NY_CRASH
3) hdfs에 생성된 디렉토리 확인
hdfs dfs -ls /user/spark/

2-2. HDFS 디렉토리에 csv파일 PUT
1) PUT
hdfs dfs -put /home/hadoop/NY_CRASH.csv /user/spark/NY_CRASH/
2) 확인하기
hdfs dfs -ls /user/spark/NY_CRASH/

3. python 파일 작성하기
pyspark를 yarn위에서 돌리는 경우, findspark는 필요하지 않습니다.
(spark-submit 시 find-spark-home 이 실행)
1) hadoop계정의 root디렉토리에서 파일생성 및 편집
touch pyspark_ETL_parqeut.py

nano pyspark_ETL_parqeut.py
(nano가 안되시면 다운받아야합니다.)
2) 원하는 결과물
00:00~06:00 시간내에 맨해튼에서 날짜별, 시간별 부상자가 가장 많거나, 사망자가 가장 많은 데이터 구하기
CRASH_DATE
CRASH_TIME
NUMBER_OF_PERSONS_INJURED
NUMBER_OF_PERSONS_KILLED
컬럼을 사용
처리방법
CRASH_DATE 는 MM/dd/yyyy형태, CRASH_TIME은 H:mm 혹은 HH:mm형태
따라서,
1) 오름차순 정렬을 위한, CRASH_DATE를 yyyy/MM/dd형태로 바꾸기위해 unix_timestamp, from_unixtime을 사용
2) 조건으로 00:00과 06:00사이에 있는 데이터를 대상으로 하기때문에, CRASH_TIME을 HH:mm형태로 만들기 위해 LPAD를 사용
3) BOROUGH의 값이 "MANHATTAN"인 것만 추출
4)날짜별, 시간별 부상자수와 사망 수를 구하기
5)날짜별 부상자수를 row_number를 통해 내림차순 등수 구하기, 사망자수를 row_number를 통해 내림차순 등수 구하기
6)날짜별 부상자수가 1위이거나, 사망자수가 1위인 조건을 걸어 날짜,시간,부상자 수, 사망자 수를 구하기
7)날짜, 시간순으로 오름차순 정렬
8) 날짜별 파티션으로 overwrite mode로 parquet형식으로 저장
3) pyspark_ETL_parquet.py 내용
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql import Window
#sparksession 드라이버 프로세스 얻기
spark = SparkSession.builder.master("yarn").appName("pyspark").getOrCreate()
df_crash = spark.read.format("csv").option("header","true").option("inferschema","true")\
.load("hdfs://mycluster/user/spark/NY_CRASH/NY_CRASH.csv")
#날짜와 시간이 yyyy/MM/dd 와 HH:mm 형식으로 바뀌고, 시간대가 00:00~06:00시에 일어난 사건 중에 지역이 'MANHATTAN'인 곳의 날짜별 시간별
df_crash_losses=df_crash\
.withColumn("CRASH_DATE_FORMATTED",F.from_unixtime(F.unix_timestamp(F.col("CRASH DATE"),"MM/dd/yyyy"),"yyyy/MM/dd"))\
.withColumn("CRASH_TIME_HH",F.lpad(F.col("CRASH TIME"),5,"0"))\
.where(F.col("CRASH_TIME_HH").between("00:00","06:00") & F.col("BOROUGH").isin("MANHATTAN"))\
.groupBy(F.col("CRASH_DATE_FORMATTED"),F.col("CRASH_TIME_HH"))\
.agg(F.max(F.col("NUMBER OF PERSONS INJURED")).alias("TOTAL_INJURED")
,F.max(F.col("NUMBER OF PERSONS KILLED")).alias("TOTAL_KILLED"))
#날짜별 부상자 숫자 순위를 메기는 컬럼과 날짜별 사망자 숫자 순위를 메기는 컬럼을 생성해서 날짜별 부상자수가 1위거나 사망자수가 1위인 시간,날짜,컬럼조회
df_crash_or=df_crash_losses\
.withColumn("MAX_INJURED_DESC_RN",F.row_number().over(Window.partitionBy(F.col("CRASH_DATE_FORMATTED")).orderBy((F.col("TOTAL_INJURED")))))\
.withColumn("MAX_KILLED_DESC_RN",F.row_number().over(Window.partitionBy(F.col("CRASH_DATE_FORMATTED")).orderBy((F.col("TOTAL_KILLED")))))\
.where((F.col("MAX_INJURED_DESC_RN") <= 1) | (F.col("MAX_KILLED_DESC_RN") <= 1))\
.select(F.col("CRASH_DATE_FORMATTED")
,F.col("CRASH_TIME_HH")
,F.col("TOTAL_INJURED")
,F.col("TOTAL_KILLED"))\
.orderBy(F.col("CRASH_DATE_FORMATTED")
,F.col("CRASH_TIME_HH"))
df_crash_or.write.format("parquet").mode("overwrite")\
.partitionBy("CRASH_DATE_FORMATTED").save("hdfs://mycluster/user/spark/NY_CRASH/total_injured_killed_datetime")
#spark session
spark.stop()
|
cs |
4 .py 파일 spark submit을 통한 실행 및 결과 확인
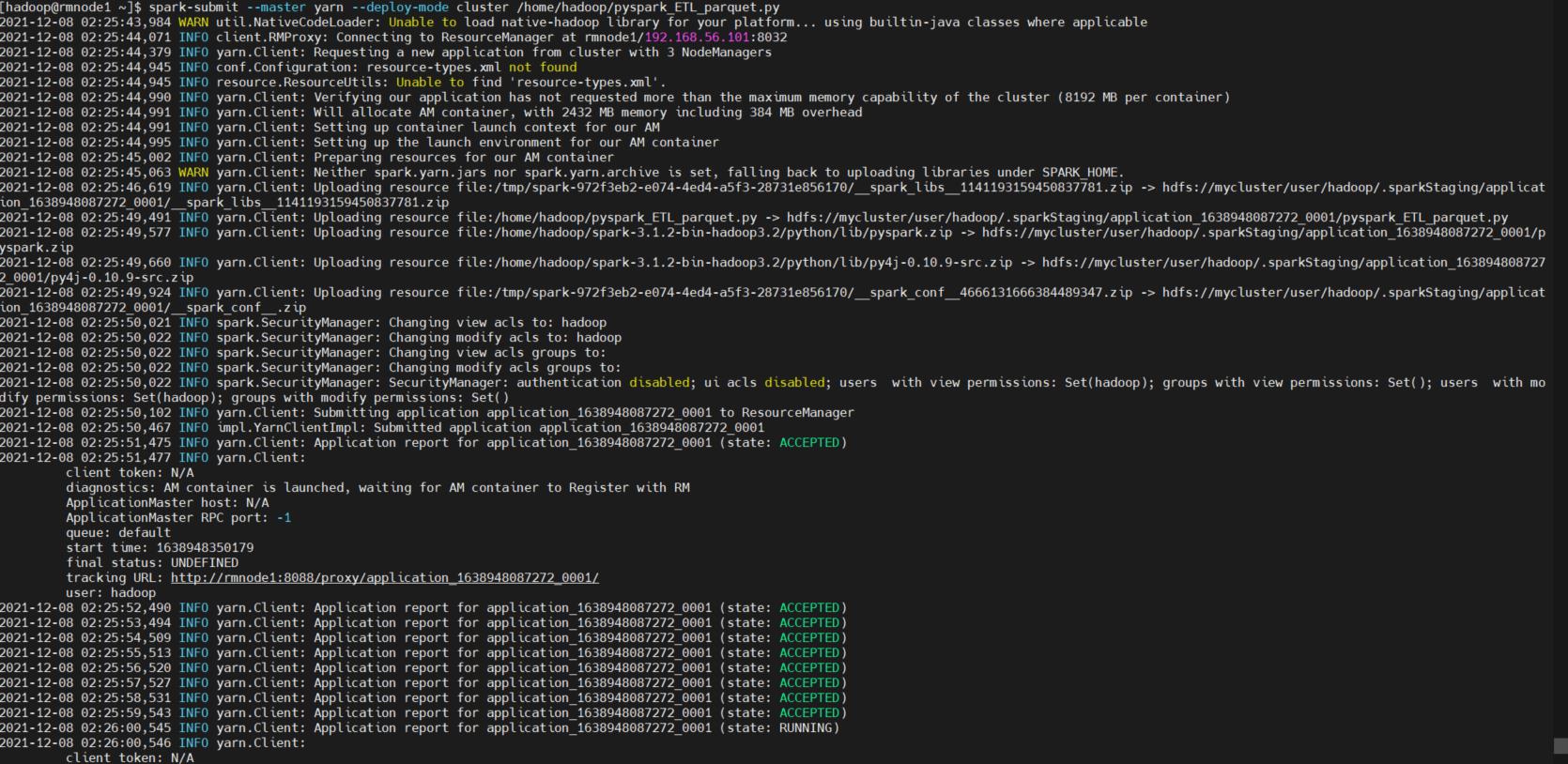
1) .py 파일 spark-submit 을 통해 실행
spark-submit --master yarn --deploy-mode cluster /home/hadoop/pyspark_ETL_parquet.py
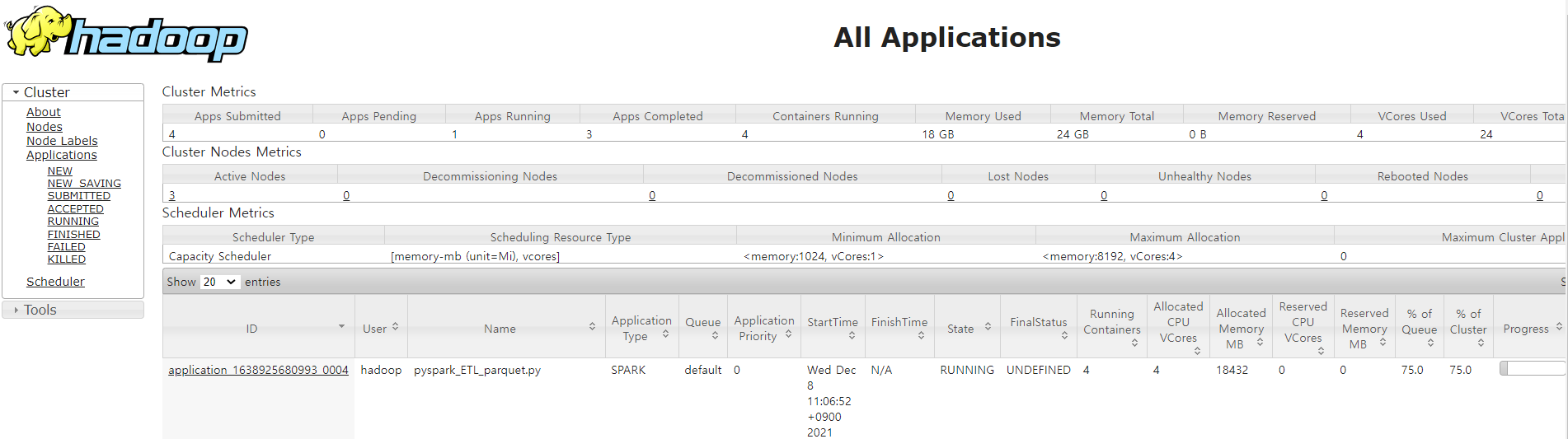
2) UI확인 및 결과 파일 확인하기
- yarn(Application Master)에 spark job이 제출되었는지
- yarn의 각 노드가 분산 처리 하고있는지(container확인)
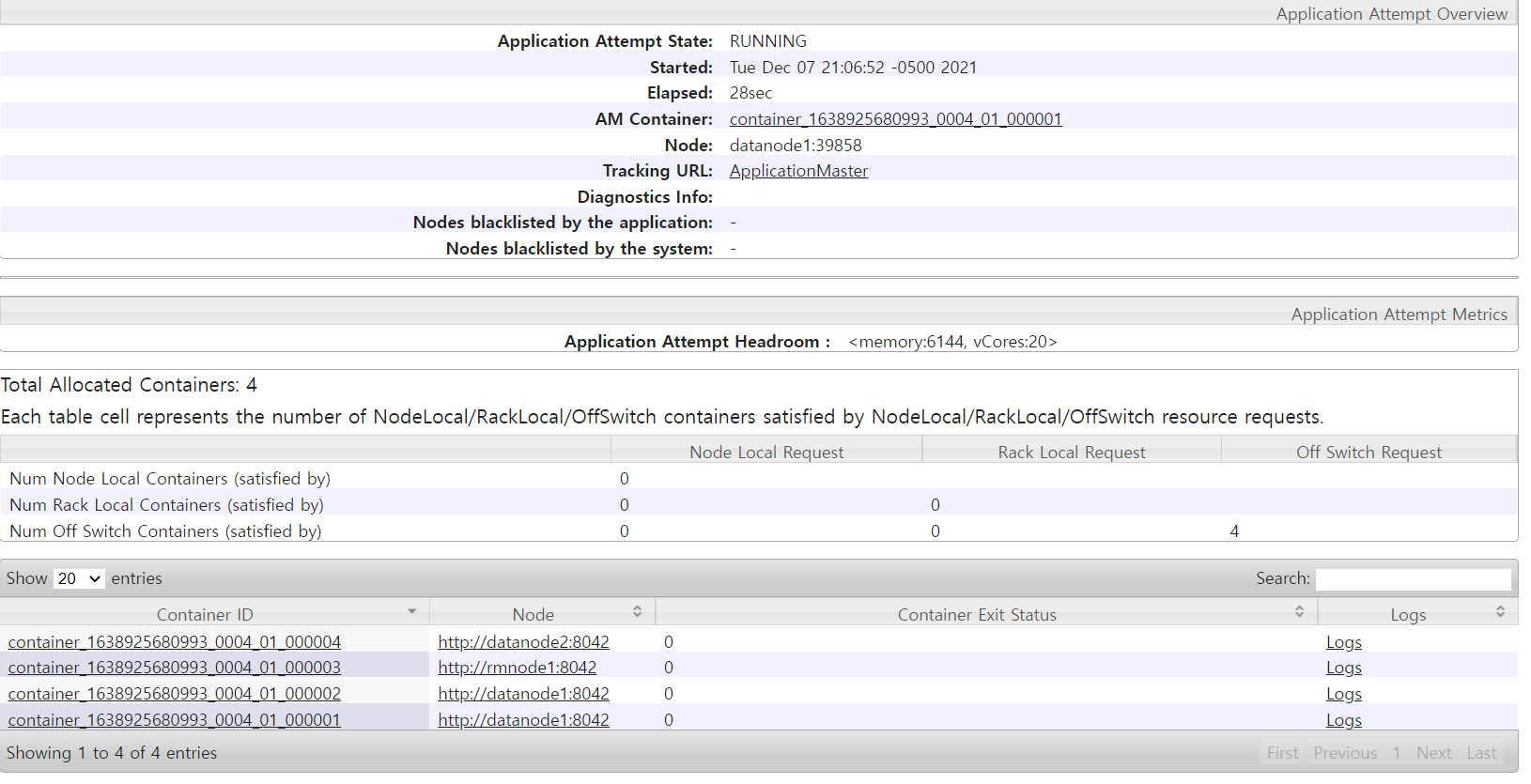
- spark config에서 설정한 4개의 executor가 실행되고 있는 지(driver 포함)
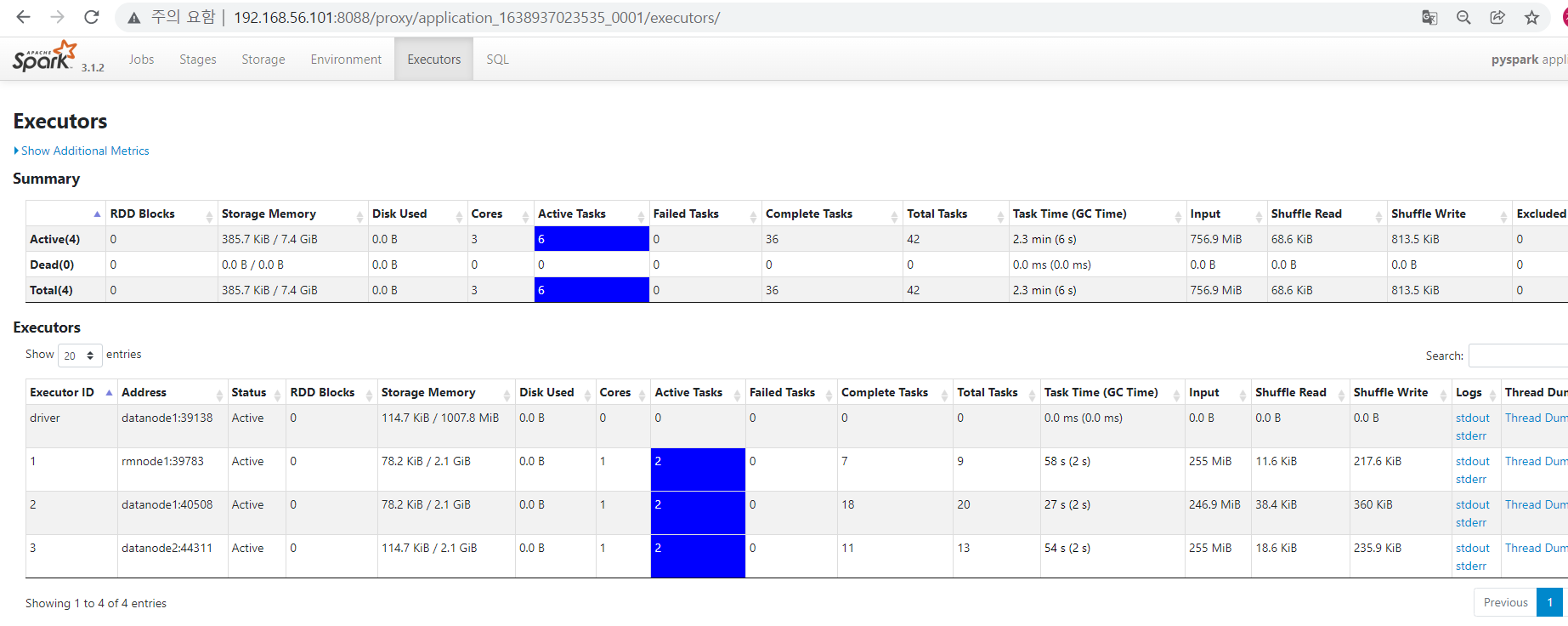
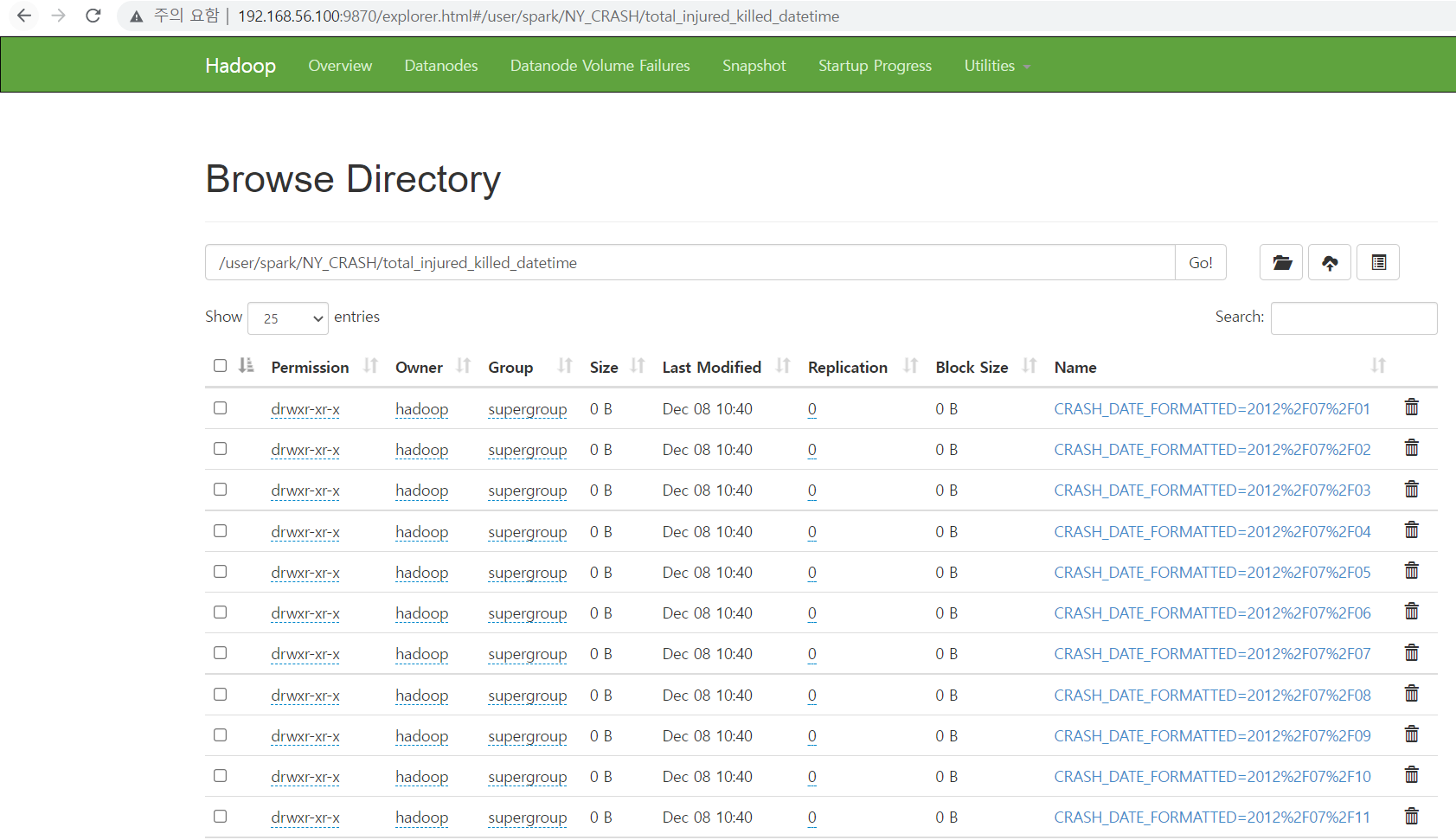
- job 이 다 돌면 hdfs에 의도한 데로 쓰여졌는지
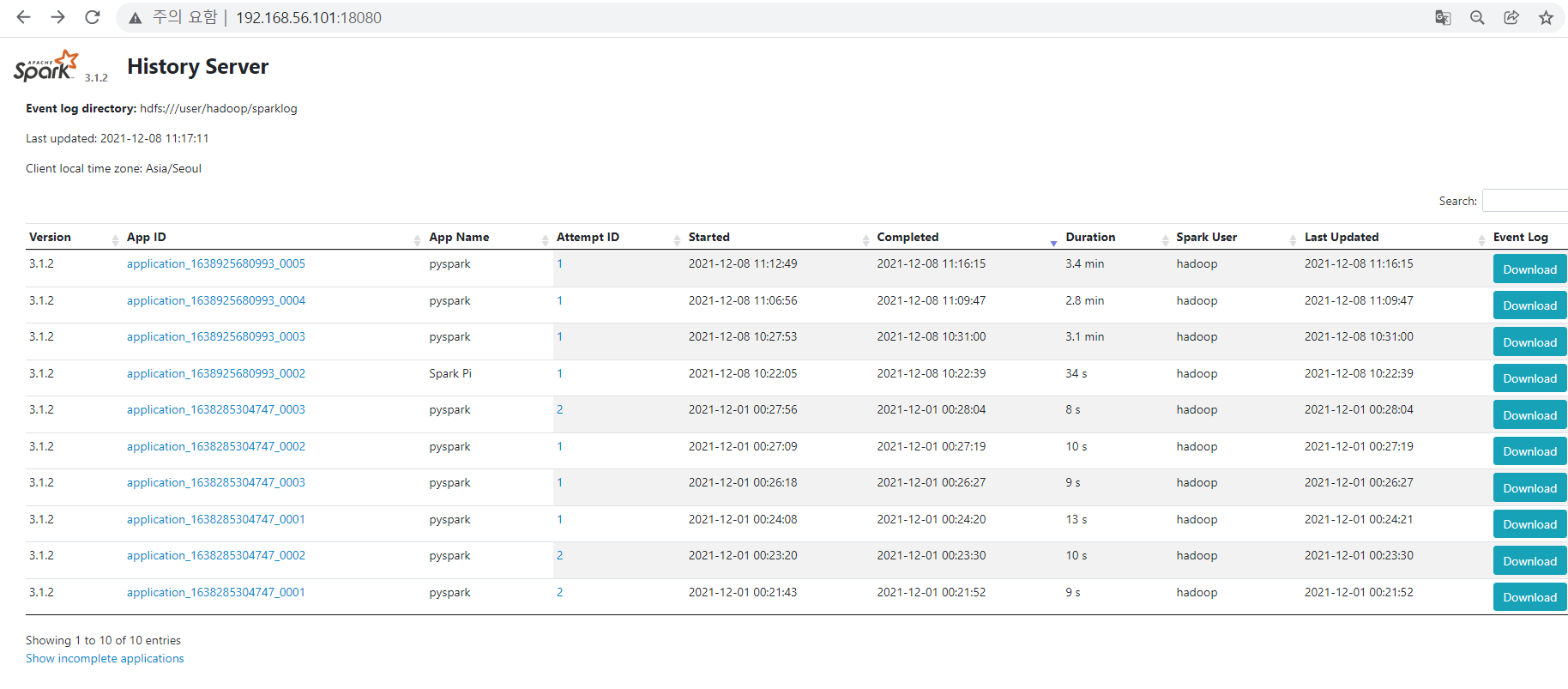
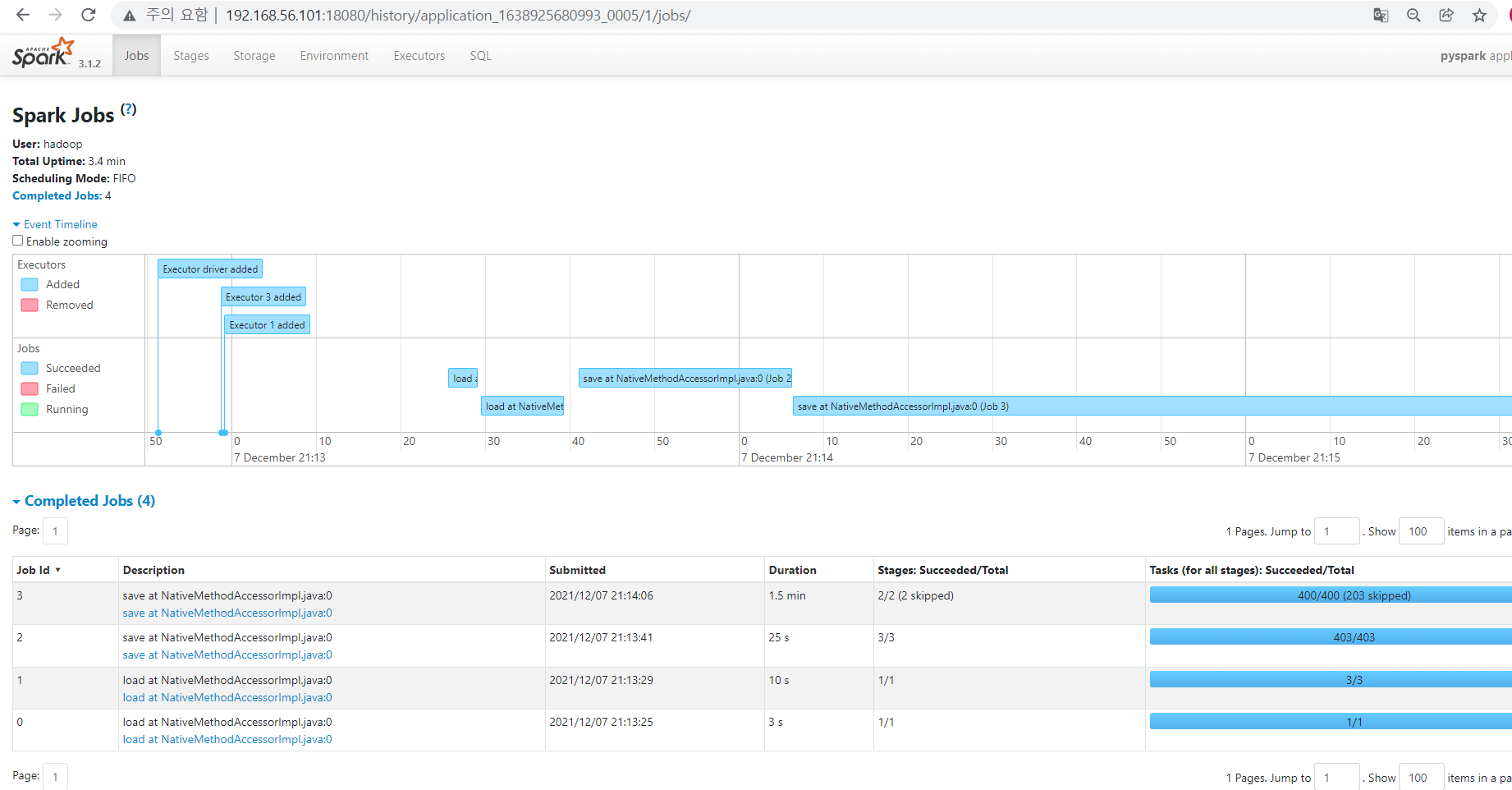
- spark job history server에 job이 제출된 이력이 남는지
알게 된 점
1. spark on yarn은 findspark모듈이 필요없다. spark-submit을 하면서 find-spark-home을 불러오기때문이다.
2. exception-in-thread-main-java-io-ioexception-cannot-run-program-error-2
python 경로가 설정되지 않았다는 에러
PYSPARK_PYTHON=/usr/bin/python3
를 /etc/profile
spark-env.sh
spark-defaults.conf
#spark.yarn.appMasterEnv.PYSPARK_PYTHON /usr/bin/python3
3개중 하나를 시도해본다.
or executor로 쓰일 모든 노드에 python3가 설치되어있는지 확인
3. yarn.ApplicationMaster: Final app status: FAILED, exitCode: 13, (reason: User application exited with status 1
spark.deafults.conf 에 설정들이 오타 혹은 잘못된 hdfs경로 같은걸로 설정 되어 있지 않은 지 확인
4. ERROR yarn.ApplicationMaster:User application exited with status 1
spark application(제출할 python file) 내에 code상 문제가 없는지 체크(특히 input,out put file경로 및 실제로 file체크하는지 등등)
5. stages 에서 skipped되는 이유는?
불필요한 작업, 이미 cache된 작업들은 생략된다.
6. python script > spark-submit > spark-defaults.conf 우선순위로 config가 적용된다.
지속적으로 수정해 나갈 생각입니다.
*노드별 memory와 executor core 산정하기
*driver node에 core가 부여되지 않는 이유
*yarn(Application Master,AM)에서 driver node로 연결되는 Application Master나 spark job history, log를 ip 192.168.56.101직접 입력하지 않고, 클릭만으로 UI가 뜰 수 있게 수정하기



댓글