이번 포스트에는
spark-submit 실습한 파일을 가지고 설치한 airflow로 spark-submit해보도록 하겠습니다.
+
헷갈리는 개념인 start_date, execution_date, schedule_interval, data interval에 대한 조작과 이해를 돕는 실습을 하겠습니다.
spark-submit을 통해 만든 .py file과 실습내용은 아래의 링크에 있습니다.
https://spidyweb.tistory.com/303
[Spark] spark standalone 모드로 pyspark 실습(.py spark submit)+ui확인하기
이번 포스트에서는 spark standalone 모드 즉, yarn을 이용하지 않고 local(단일 노드로) pyspark을 제출하는 .py 파일을 생성해 스크립트 실행을 시켜 제출해보도록 하겠습니다. 하둡 및 스파크를 설치하
spidyweb.tistory.com
airflow 개념에 대해 잘 모르시는 분은 아래의 링크를 참조해주세요.
2021.10.17 - [BigData] - [BigData] Apache Airflow 설치 및 실습 하기 series (1) Airflow란? DAG란?
[BigData] Apache Airflow 설치 및 실습 하기 series (1) Airflow란? DAG란?
안녕하세요 이번 포스트에는 Airflow의 개념에 대해서 알아보고 어떤 역할을 하는지, 그리고 핵심인 DAG파일에 대해서 알아보겠습니다. 1. Apahce Airflow란? 에어비앤비에서 python기반으로 개발한 워크
spidyweb.tistory.com
airflow 설치가 완료되지 않으신 분은 아래의 링크를 참조해주세요.
[BigData] Apache Airflow 설치 및 실습하기 series (2) Airflow 2.1 ubuntu 20.04에 설치하기
안녕하세요 이번 포스트에는 Airflow만 독단적으로 설치해보겠습니다. 다음포스트에는 DAG파일을 집중분석하여 실습해보도록 하겠습니다. 준비사항 우분투 20.04 LTS 서버와 충분한 디스크 공간 sudo
spidyweb.tistory.com
실습 환경
이 포스트는 hadoop 및 spark가 설치되어 있어야하며, airflow와 같은 노드에 있습니다.
spark-submit은 내부적으로 spark binary인 spark-submit 을 호출하는 방식으로 spark을 실행하고 있고, 각자의 환경에 알맞은 spark을 각 airflow worker에 다운로드 한후 다운로드 경로를 $SPARK_HOME을 환경변수로 등록하고 $SPARK_HOME/bin 을 path에 추가하는 작업이 완료 되어야 합니다.
hadoop 설치
[Hadoop] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 3.ubuntu 에 hadoop(하둡) 다운로드,설치
이번 포스트에는 virtualbox에 하둡을 설치하겠습니다. virtualbox에 ubuntu를 설치하지 못하신 분이나, windows의 powershell로 ssh통신을 할 줄 모르시는 분이면 아래URL의 포스트부터 선행하여 주세요! spidyw
spidyweb.tistory.com
spark 설치
[Spark] virtual box linux [ubuntu 18.04]에 스파크 설치,다운로드 5.ubuntu 에 spark(스파크) 다운로드,설치
이번 포스트에는 Spark를 설치해 보겠습니다. vritualbox 설치,ubuntu설치, ssh통신, hadoop 설치가 완료 되지 않으신 분은 아래의 URL을 참고하여 완료해 주세요. 1.virtualbox 설치 및 ubuntu 설치 spidyweb.tis..
spidyweb.tistory.com
1. airflow web과 scheduler 실행하기
1) 웹 서버 띄우기
airflow webserver -p 8081
현재 8081포트를 포트포워딩한 상태입니다.

2) 스케줄러 실행하기
airlfow scheduler

2. DAG file 만들기
- /airflow/dags 디렉토리에 file을 만들면 경로가 설정되어 있어, dags가 ui 에도 보이게됩니다.
- dags 디렉토리가 없다면 생성하고 그 안에 file을 생성하시면됩니다.

nano dag_Spark_spidyweb.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'spidyweb',
'retries': 0,
'retry_delay': timedelta(seconds=20),
'depends_on_past': False
}
dag_Spark_spidyweb = DAG(
'dag_Spark_spidyweb_id',
start_date=days_ago(2),
default_args=default_args,
schedule_interval='@once',
catchup=False,
is_paused_upon_creation=False,
)
cmd='spark-submit /home/hadoop/pyspark_ETL_parquet.py'
#시작을 알리는 dummy task_start = DummyOperator(
task_id='start',
dag=dag_Spark_spidyweb,
)
#시작이 끝나고 다음단계로 진행되었음을 나타내는 dummy task_next = DummyOperator(
task_id='next',
trigger_rule='all_success',
dag=dag_Spark_spidyweb,
)
#끝을 알리는 dummy
task_finish = DummyOperator(
task_id='finish',
trigger_rule='all_done',
dag=dag_Spark_spidyweb,
)
#오늘의 목표인 bash를 통해 spark-submit할 operator
task_PySpark_1 = BashOperator(
task_id='spark_submit_task',
dag=dag_Spark_spidyweb,
bash_command=cmd,
)
#의존관계 구성
task_start >> task_next >> task_PySpark_1 >> task_finish
|
cs |
위의 내용을 입력 후 ctrl+x Y enter로 저장하고 나옵니다.

dag_Spark_spidyweb_id dag가 생성된 것을 알 수 있습니다.
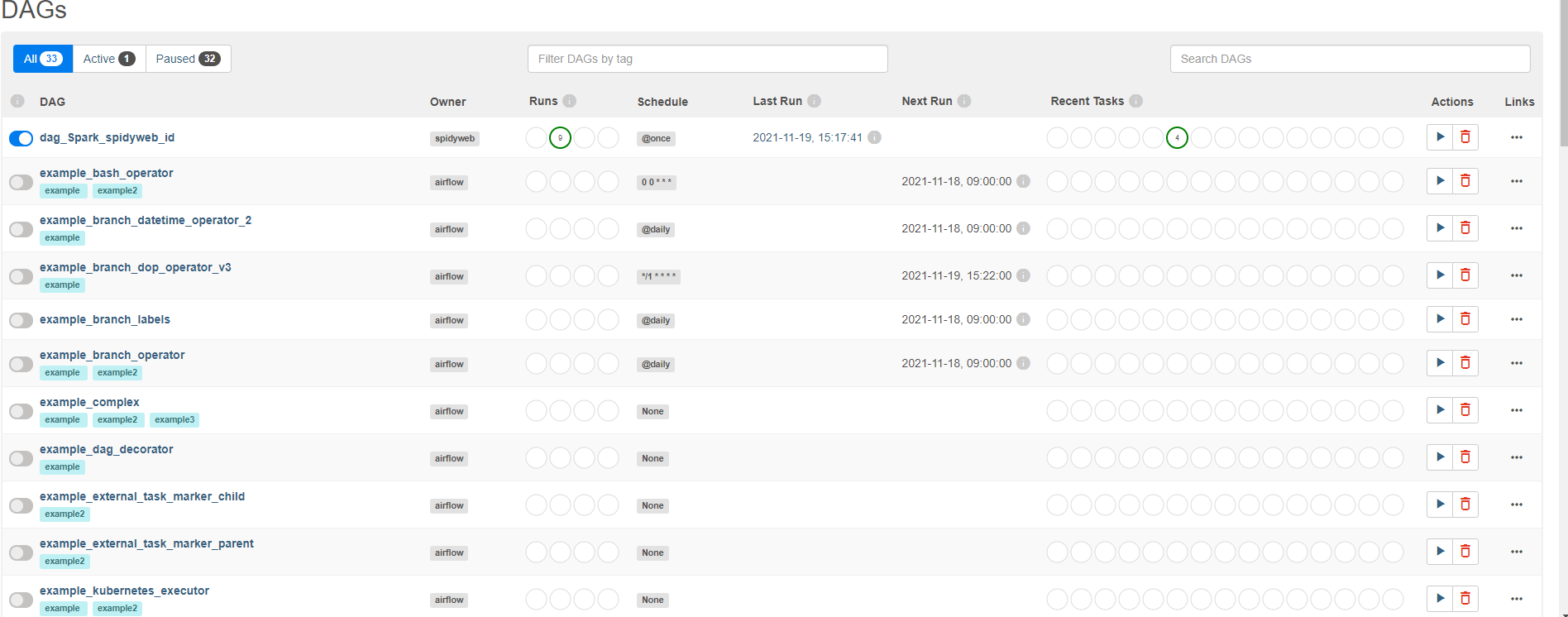
3. DAG 실행 및 결과 확인
1) airflow DAG running과 success 확인하기
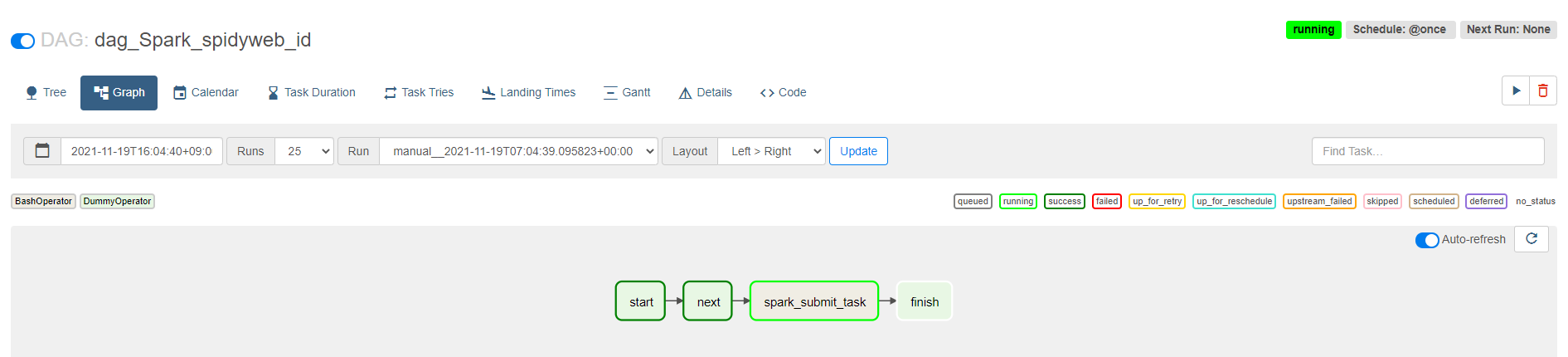
끝났을 때의 DAG(success,초록색으로 전부 변함)
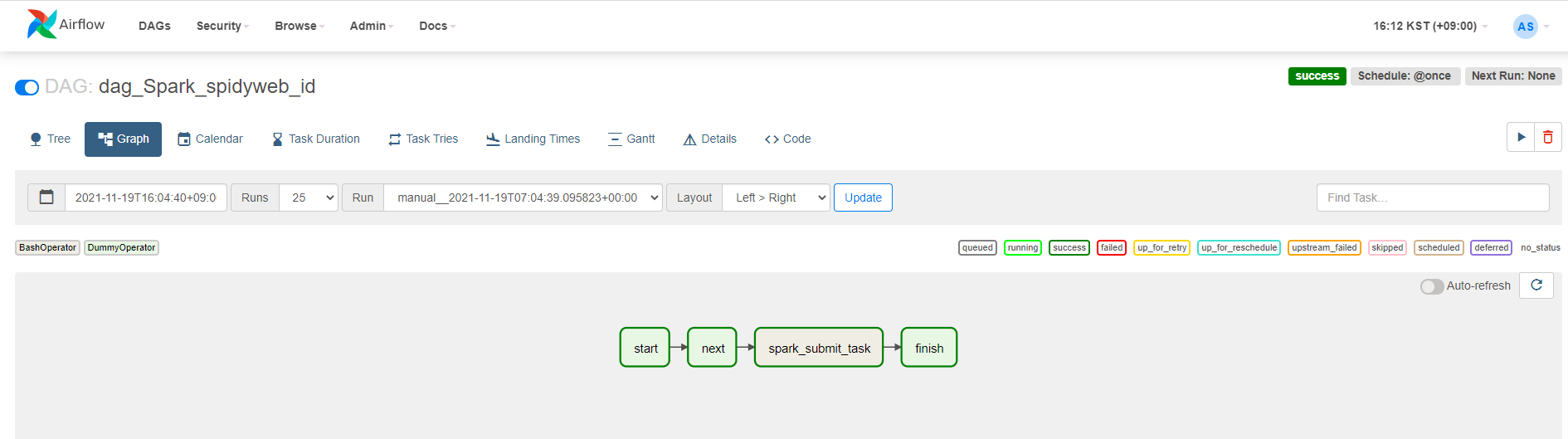
2) spark ui확인하기
현재 spark_submit_task가 돌고 있으므로 spark session이 생성되어 4040포트로 확인할 수 있습니다.(4040포트포워딩 완료가 되어야함)
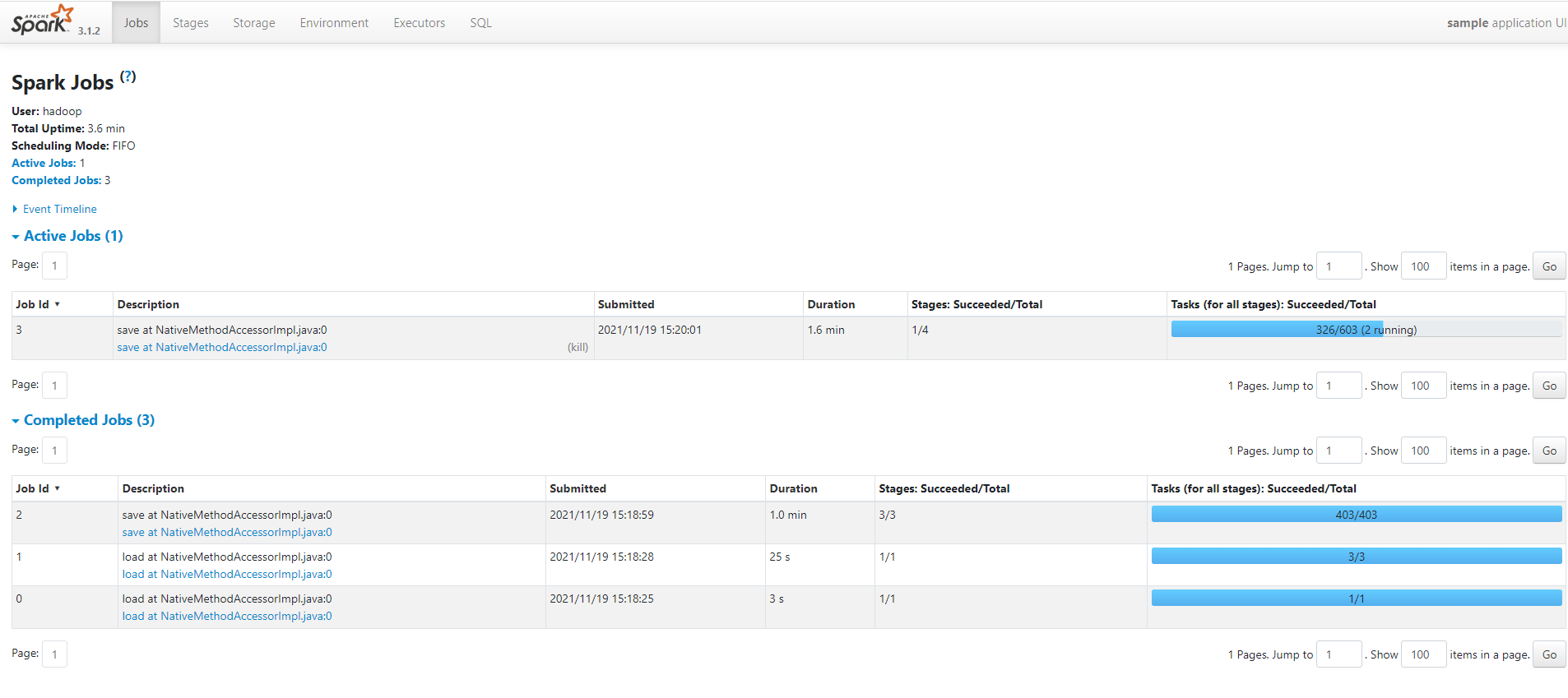
spark job이 다 돌면 spark.stop()에 의해 spark session은 죽습니다.(4040을 통한 ui확인도 불가)
3) hdfs ui확인하기
spark를 통해 directory가 써지고 있는 작업이여서 _temporary로 작업중
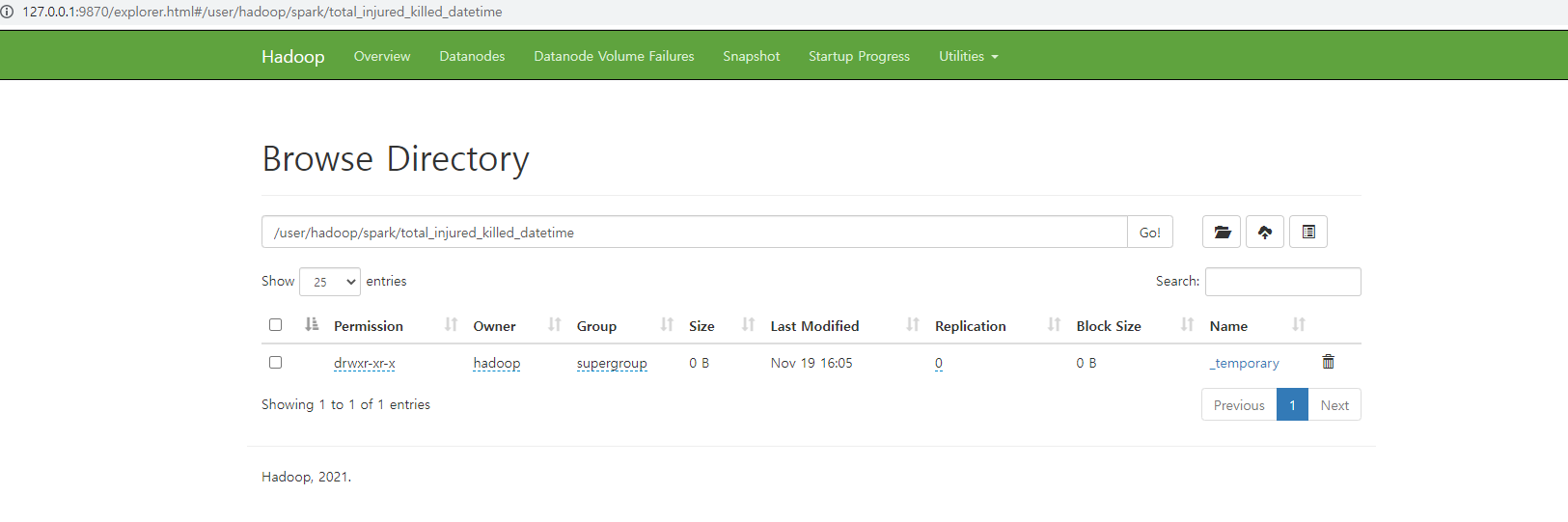
hdfs에 써진 디렉토리와 파일
4. start_date, schedule_interval, execution_date에 대한 조작과 이해 그리고 data interval
- 기존의 start_date에 대한 설정:
- 현재 시각을 10:35 가정
- 여태까지 start_date는 현재 시각 이전의 날짜,시간으로 설정(days_ago(2))했었다.
그렇게 설정을하게되면 DAG를 생성한 즉시 scheduling이 시작되며,
execution_date가 scheduling된 시간으로 설정됩니다. - 실제 실행시간은 execution_date에서 shcedule_interval 시간이 지난 시각에 시작되고
- 제출한 job은 schedule_interval 동안의 데이터를 가지고 job을 제출하게 됩니다.
ex) 10:35~10:45 동안의 데이터(schedule_interval='0/10 * * * *')
- 미래시점의 start_date에 대한 설정:
- 현재 시각을 10:45 이라고 가정
- start_date를 10:50 으로 설정(미래 시점)
DAG를 생성해도, 10:50 에 scheduling이 시작된다.
10:50이 지난 시점에 이제 start_date는 과거시점이 되므로 schedule_interval 주기에 따라 실행
execution_date도 scheduling된 시간인 10:50 으로 설정 - 실제 실행시간은 마찬가지로 execution_date에서 shcedule_interval 시간이 지난 시각에 시작
- 제출한 job은 schedule_interval 동안의 데이터를 가지고 job을 제출
ex) 10:50~11:00 동안의 데이터(schedule_interval='0/10 * * * *')
- data_interval 확인:
- data_interval은 airflow 2.2v 부터 들어온 개념
- execution_date의 종말이 오고 새롭게 쓰이는 개념
- data_interval 동안의 데이터를 job으로써 던지는 것.
- data interval의 start는 execution_date,
data interval의 end는 execution_date로부터 schedule_interval 시간이 지난 시각
data interval의 run after는 실제 job이 시작되는 시간
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
from datetime import datetime, timedelta
from datetime import timezone
import pendulum
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago
KST = pendulum.timezone("Asia/Seoul")
default_args = {
'owner': 'spidyweb',
'retries': 0,
'retry_delay': timedelta(seconds=20),
'depends_on_past': False
}
dag_Spark_spidyweb = DAG(
'dag_Spark_spidyweb_id',
start_date=datetime(2021, 12, 14, 11, 00, tzinfo=KST),
default_args=default_args,
schedule_interval='0/10 * * * *',
catchup=False,
is_paused_upon_creation=False,
)
#현재 시각은 2021-12-14 10:52분이고, 위의 start_date는 #2021-12-14 11:00으로 잡혀있다. 즉 11:00분에 dag가 scheduling되는 것이다. #schedule_interval은 10분으로 설정되어 있으므로, #2021-12-14 11:00(execution_date) ~ 2021-12-14 11:10까지의 데이터를 시작으로 #2021-12-14 11:10부터 실제로 job을 실행하여 10분간격으로 실행시킨다. cmd='spark-submit /home/hadoop/pyspark_ETL_parquet.py'
#시작을 알리는 dummy
task_start = DummyOperator(
task_id='start',
dag=dag_Spark_spidyweb,
)
#시작이 끝나고 다음단계로 진행되었음을 나타내는 dummy
task_next = DummyOperator(
task_id='next',
trigger_rule='all_success',
dag=dag_Spark_spidyweb,
)
#끝을 알리는 dummy
task_finish = DummyOperator(
task_id='finish',
trigger_rule='all_done',
dag=dag_Spark_spidyweb,
)
#오늘의 목표인 bash를 통해 spark-submit할 operator
task_PySpark_1 = BashOperator(
task_id='spark_submit_task',
dag=dag_Spark_spidyweb,
bash_command=cmd,
)
#의존관계 구성
task_start >> task_next >> task_PySpark_1 >> task_finish
|
cs |
*start_date가 11:00로 설정

*data interval이 start 11:00 end 11:10으로 설정
*run after가 실제 job 이 시작되는 시간
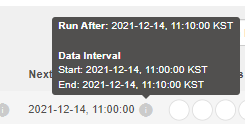
*11:10이 되어 스케쥴된 job의 실제 시작

*execution_date는 data interval의 start와 같은 2021-12-14 11:00으로 설정되었습니다.

*제출된 job을 graph로 보기

'BigData > Apache Airflow' 카테고리의 다른 글
| [Airflow] Airflow cluster, celery executor + flower + RabbitMQ 환경 구성하기 (0) | 2023.01.09 |
|---|---|
| [Airflow] docker-compose.yml로 airflow 설치하기 (0) | 2023.01.07 |
| [Airflow] Airflow 설치 + mysql로 DB지정하기 +서비스(데몬으로) 등록하기 (0) | 2022.02.10 |
| [BigData] Apache Airflow 설치 및 실습 하기 series (1) Airflow란? DAG란? (0) | 2021.10.17 |
| [BigData] Apache Airflow 설치 및 실습하기 series (2) Airflow 2.1 ubuntu 20.04에 설치하기 (0) | 2021.10.17 |




댓글