이번 포스트에는 airflow dag를 구성하여 pyspark job을 실행시킨 후, S3에 데이터를 복사해 넣고 EC2를 자동으로 종료하겠습니다.
어떤 프로젝트인지 잘 모르시는 분은 아래의 링크를 참고해주세요.
EC2에 환경 구성이 되지 않으신 분은 아래의 링크를 참고해주세요
1. PySpark ETL 파일 생성하기
cd ~
nano api_development_xml_pyspark.py#스파크가 pandas보다 느리고, 스파크는 큰 데이터가 아니면 의미없지만, 스파크에서 배운 data transformation을 활용 하기위해 스파크를 채택
import requests
from bs4 import BeautifulSoup
from datetime import datetime, date, timedelta
from typing import Union
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql import Row
from pyspark.sql.types import StructField, StructType, DoubleType, IntegerType, TimestampType, StringType
#sparksession 드라이버 프로세스 얻기
spark = SparkSession.builder.master("local[*]").config("spark.driver.extraClassPath","/home/ubuntu/mysql-connector-java-8.0.28/mysql-connector-java-8.0.28.jar").appName("pyspark").getOrCreate()
now = datetime.now()
today = date.today()
oneday = timedelta(days=1)
def getCovid19Info(start_date: date, end_date: date):
url = 'http://openapi.data.go.kr/openapi/service/rest/Covid19/getCovid19InfStateJson'
api_key_utf8 = 'mrAZG1yevJBgcaaSuVLOgJ%2BS6blzA0SXlGYZrwxwpARTaMnSotfqFooTr6dgKpPcTBtE96l0xE%2B%2BmXxDrWt19g%3D%3D'
api_key_decode = requests.utils.unquote(api_key_utf8, encoding='utf-8')
params ={
'serviceKey' : api_key_decode,
'startCreateDt' : int('{:04d}{:02d}{:02d}'.format(start_date.year, start_date.month, start_date.day)),
'endCreateDt' : int('{:04d}{:02d}{:02d}'.format(end_date.year, end_date.month, end_date.day)),
}
response = requests.get(url, params=params)
content = response.text
elapsed_us = response.elapsed.microseconds
print('Reqeust Done, Elapsed: {} seconds'.format(elapsed_us / 1e6))#100만
return BeautifulSoup(content, "lxml")#python xml인 lxml로 변환
#union을 통해 date, datetime 두개의 type모두 허용
def getCovid19SparkDataFrame(start_date: Union[date, datetime], end_date: Union[date,datetime]):
#key값의 데이터 타입 정의
convert_method = {
'accdefrate' : float,
'accexamcnt' : int,
'createdt' : lambda x: datetime.strptime(x, '%Y-%m-%d %H:%M:%S.%f'),
'deathcnt' : int,
'decidecnt' : int,
'seq' : int,
'statedt' : str,
'statetime' : str,
'updatedt' : lambda x: datetime.strptime(x, '%Y-%m-%d %H:%M:%S.%f'),
}
#파싱 후 dictionay들의 list 형태 변환 과정 이해하기
temp = getCovid19Info(start_date, end_date)
items = temp.find('items')
item_list = []
for item in items:
item_dict = {}
for tag in list(item):
try:
item_dict[tag.name] = convert_method[tag.name](tag.text)
except Exception:
item_dict[tag.name] = None
item_list.append(item_dict)
#dictionary의 list를 spark DataFrame으로 바꾸는 방법 dictionary 속의 key를 schema를 정의해준다.
CovidInfo_item_Schema = StructType([
StructField('accdefrate', DoubleType(), True),#누적확진률
StructField('accexamcnt', IntegerType(), True),#누적의심신고검사자
StructField('createdt', TimestampType(),True),#등록일시분초
StructField('deathcnt', IntegerType(), True),#사망자 수
StructField('decidecnt', IntegerType(), True),#확진자 수
StructField('seq', IntegerType(), True),#게시글 번호(감염현황 고유값)
StructField('statedt', StringType(), True),#기준일
StructField('statetime', StringType(), True),#기준시간
StructField('updatedt', TimestampType(), True)#수정일시분초
])
df_Covid19 = spark.createDataFrame(item_list,CovidInfo_item_Schema)
return df_Covid19
#XML로 부터 파싱된 item들의 모든 데이터를 리턴
#데이터 조회시 메소드.show() ex)getAllCovid19Data().show()
def getAllCovid19Data():
df_Covid19 = getCovid19SparkDataFrame(date(2019,1,1), now)
print("Today: {}\nLoaded {} Records".format(now.strftime('%Y-%m-%d'),df_Covid19.distinct().count()))
return df_Covid19
#코로나 매일의 확진자, 누적확진자, 사망자, 누적사망자, 치명률, 검사자,누적검사자를 뽑아낸 dataframe
#임시 선별 검사자 수는 제외(api를 못구함)
#데이터 조회시 메소드.show() ex)getAllCovidAffectedNumbers().show()
def getAllCovidAffectedNumbers():
from pyspark.sql import Window
df_Covid19 = getCovid19SparkDataFrame(date(2019,1,1), now)
df_Covid19_result_All=\
df_Covid19.distinct()\
.withColumn("decidecnt-1",F.coalesce(F.lead(F.col("decidecnt"),1).over(Window.orderBy(F.col("statedt").desc())),F.lit(0)))\
.withColumn("deathcnt-1",F.coalesce(F.lead(F.col("deathcnt"),1).over(Window.orderBy(F.col("statedt").desc())),F.lit(0)))\
.withColumn("기준날짜",F.from_unixtime(F.unix_timestamp(F.col("statedt"),"yyyyMMdd"),"yyyy-MM-dd"))\
.select(F.col("기준날짜")
,(F.col("decidecnt")-F.col("decidecnt-1")).alias("당일확진자수")
,F.col("decidecnt").alias("누적확진자수")
,(F.col("deathcnt")-F.col("deathcnt-1")).alias("당일사망자수")
,F.col("deathcnt").alias("누적사망자수")
,F.round((F.col("deathcnt")/F.col("decidecnt")*F.lit(100)),2).alias("전체확진자치명률(%)"))
return df_Covid19_result_All
#코로나 오늘의 확진자, 누적확진자, 사망자, 누적사망자, 치명률, 검사자,누적검사자를 뽑아낸 dataframe
#임시 선별 검사자 수는 제외(api를 못구함)
#데이터 조회시 메소드.show() ex)getAllCovidAffectedNumbers().show()
def getTodayCovidAffectedNumbers():
from pyspark.sql import Window
now_date=now.strftime('%Y-%m-%d')
df_Covid19 = getCovid19SparkDataFrame(date(2019,1,1), now)
df_Covid19_result_Today=\
df_Covid19.distinct()\
.withColumn("decidecnt-1",F.coalesce(F.lead(F.col("decidecnt"),1).over(Window.orderBy(F.col("statedt").desc())),F.lit(0)))\
.withColumn("deathcnt-1",F.coalesce(F.lead(F.col("deathcnt"),1).over(Window.orderBy(F.col("statedt").desc())),F.lit(0)))\
.withColumn("기준날짜",F.from_unixtime(F.unix_timestamp(F.col("statedt"),"yyyyMMdd"),"yyyy-MM-dd"))\
.where(F.col("기준날짜")==now_date)\
.select(F.col("기준날짜")
,(F.col("decidecnt")-F.col("decidecnt-1")).alias("당일확진자수")
,F.col("decidecnt").alias("누적확진자수")
,(F.col("deathcnt")-F.col("deathcnt-1")).alias("당일사망자수")
,F.col("deathcnt").alias("누적사망자수")
,F.round((F.col("deathcnt")/F.col("decidecnt")*F.lit(100)),2).alias("전체확진자치명률(%)"))
return df_Covid19_result_Today
#코로나 범위내의 확진자, 누적확진자, 사망자, 누적사망자, 치명률, 검사자,누적검사자를 뽑아낸 dataframe
#임시 선별 검사자 수는 제외(api를 못구함)
#데이터 조회시 메소드.show() ex)getAllCovidAffectedNumbers().show()
def getPeriodCovidAffectedNumbers(start_date: Union[date, datetime], end_date: Union[date,datetime]):
from pyspark.sql import Window
df_Covid19 = getCovid19SparkDataFrame(date(2019,1,1), now)
df_Covid19_result_Period=\
df_Covid19.distinct()\
.withColumn("decidecnt-1",F.coalesce(F.lead(F.col("decidecnt"),1).over(Window.orderBy(F.col("statedt").desc())),F.lit(0)))\
.withColumn("deathcnt-1",F.coalesce(F.lead(F.col("deathcnt"),1).over(Window.orderBy(F.col("statedt").desc())),F.lit(0)))\
.withColumn("기준날짜",F.from_unixtime(F.unix_timestamp(F.col("statedt"),"yyyyMMdd"),"yyyy-MM-dd"))\
.where(F.col("기준날짜").between(start_date,end_date))\
.select(F.col("기준날짜")
,(F.col("decidecnt")-F.col("decidecnt-1")).alias("당일확진자수")
,F.col("decidecnt").alias("누적확진자수")
,(F.col("deathcnt")-F.col("deathcnt-1")).alias("당일사망자수")
,F.col("deathcnt").alias("누적사망자수")
,F.round((F.col("deathcnt")/F.col("decidecnt")*F.lit(100)),2).alias("전체확진자치명률(%)"))
return df_Covid19_result_Period, start_date, end_date#이후에 함수별로 저장할 때, DF가 기간으로 입력받은 것을 알기위해 기간값도 리턴
#위의 3개의 메소드를 통해 데이터프레임을 입력받아 c드라이브 covid19_result 폴더에 함수 형태에 따른csv파일로 저장
def saveDataAsCSV(dataframe):
if type(dataframe) == tuple:
dataframe[0].cache()#cache의 수명은 함수가 호출되서 끝나기까지 이므로 매 함수마다 적용
start_date=dataframe[1]
end_date=dataframe[2]
if dataframe[0].count() == getPeriodCovidAffectedNumbers(start_date, end_date)[0].count():
print("it worked!")
return dataframe[0].coalesce(1).write.format("csv").option("header","true").mode("overwrite").save("/home/ubuntu/covid19_result/period/")
else:
dataframe.cache()
if dataframe.count() == getAllCovidAffectedNumbers().count():#dataframe처음 호출, 함수를 통한 dataframe처음 호출, dataframe != getAllCovidAffectedNumbers()
print("it worked!")
return dataframe.coalesce(1).write.format("csv").option("header","true").mode("overwrite").save("/home/ubuntu/covid19_result/all_day/")#count때 호출된 dataframe이 cache된다.
elif dataframe.count() == getTodayCovidAffectedNumbers().count():
print("it worked!")
return dataframe.coalesce(1).write.format("csv").option("header","true").mode("overwrite").save("/home/ubuntu/covid19_result/today/")
#파티션별로 나누어 파일 저장(daily partition별로 데이터 적재)
def saveDataAsPartitionCSV(dataframe):
if type(dataframe) == tuple:
dataframe[0].cache()#cache의 수명은 함수가 호출되서 끝나기까지 이므로 매 함수마다 적용
start_date=dataframe[1]
end_date=dataframe[2]
if dataframe[0].count() == getPeriodCovidAffectedNumbers(start_date, end_date)[0].count():
print("it worked!")
return dataframe[0].write.format("csv").option("header","true").mode("overwrite").partitionBy("기준날짜").save("/home/ubuntu/covid19_result/partition/period/")
else:
dataframe.cache()
if dataframe.count() == getAllCovidAffectedNumbers().count():
print("it worked!")
return dataframe.write.format("csv").option("header","true").mode("overwrite").partitionBy("기준날짜").save("/home/ubuntu/covid19_result/partition/all_day/")
elif dataframe.count() == getTodayCovidAffectedNumbers().count():
print("it worked!")
return dataframe.write.format("csv").option("header","true").mode("overwrite").partitionBy("기준날짜").save("/home/ubuntu/covid19_result/partition/today/")
#mysql DB에 Covid19 DataFrame의 데이터를 저장
def saveDataToMySQL(dataframe):
if type(dataframe) == tuple:
dataframe[0].cache()#cache의 수명은 함수가 호출되서 끝나기까지 이므로 매 함수마다 적용
else:
dataframe.cache()
if dataframe.count() == getAllCovidAffectedNumbers().count():
print("insert to mysql Covid19 table")
return dataframe.coalesce(1).write.format("jdbc").options(
url='jdbc:mysql://localhost:3306/COVID19',
driver='com.mysql.cj.jdbc.Driver',
dbtable='Covid_19_info',
user='root',
password='root'
).mode('overwrite').save()
if __name__=="__main__":
try:
today_infection_num = (getTodayCovidAffectedNumbers().first()["당일확진자수"])
infection_num_diff = (getTodayCovidAffectedNumbers().first()["당일확진자수"] -
getPeriodCovidAffectedNumbers(today-oneday,today)[0].where(F.col("기준날짜")==str(today-oneday)).first()["당일확진자수"])
print("오늘(%s)의 확진자수는 %d명입니다.\n" % (today, today_infection_num))#df.first()['column name'] 혹은 df.collect()[0]['column name'], 오늘의 데이터가 없을 경우 none type이 되어 에러를 낸다.try except 처리
if infection_num_diff >= 0:
print("어제보다 코로나 확진자가 %d명 늘었습니다.\n" % (infection_num_diff))
else:
print("어제보다 코로나 확진자가 %d명 줄었습니다.\n" % (-infection_num_diff))
except TypeError:
print("오늘의 데이터가 아직 입력되지 않았습니다.")
saveDataAsCSV(getAllCovidAffectedNumbers())
saveDataAsPartitionCSV(getAllCovidAffectedNumbers())
saveDataToMySQL(getAllCovidAffectedNumbers())ETL파일을 한번 실행시킴으로써 올바르게 작성되었는지 확인합니다.
python3 api_development_xml_pyspark.py단일 파일 결과

partitioned 된 결과

MySQL DB

2. aws cli 설치 및 config 설정
1) AWS CLI2 설치
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install2) 환경변수 등록
nano .profile
export AWS_HOME=/usr/bin/local/3) AWS config 설정
먼저 AWS credential access key를 만들어야 합니다.


key file을 다운로드하고
aws configure를 통해 파일에 적혀있는 key를 입력합니다.
AWS access KEY ID
AWS Secret access KEY
Default region name

여기까지 완료
3. S3 bucket 생성 및 S3 데이터 전송 테스트
S3에 전송을 하기전 bucket을 create해둡니다.

또한 S3에 직접 쓰는 것이 아닌 복사하는 행위 이기에 버킷 속에 디렉토리도 미리 생성해둡니다.
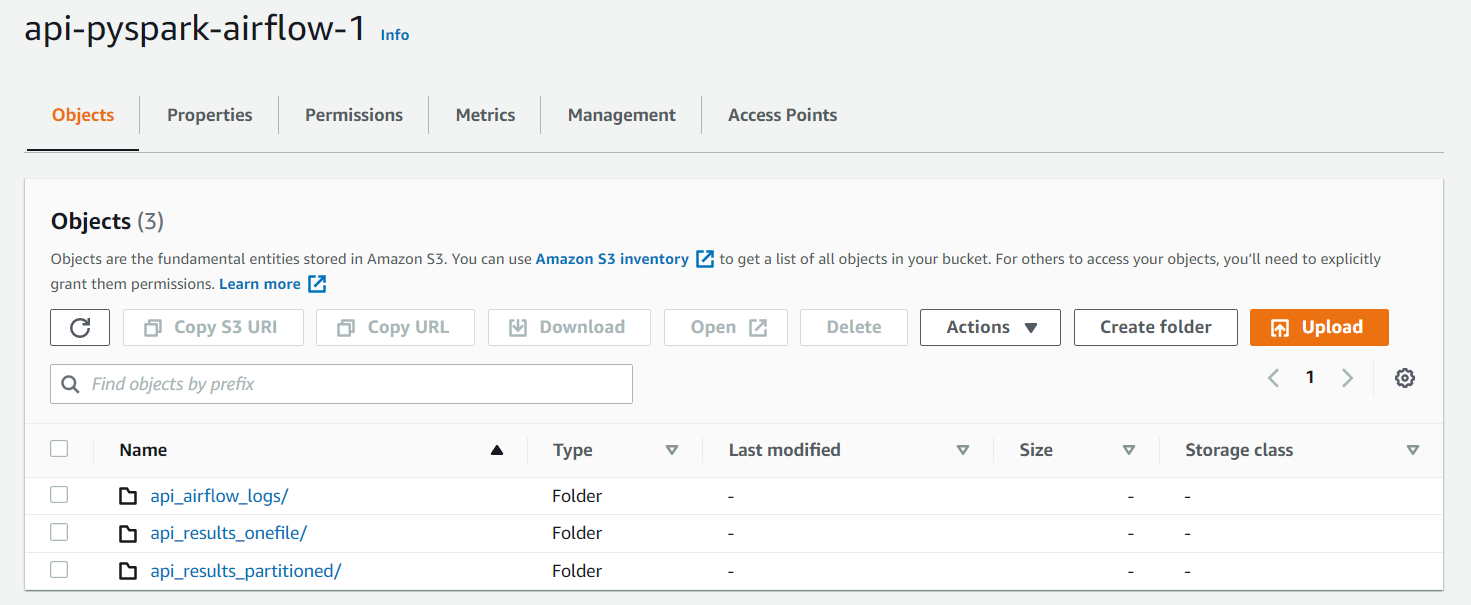
S3에 테스트해본 api_development_xml_pyspark.py 결과 데이터를 복사해봅니다.
aws s3 sync /home/ubuntu/covid19_result/partition/all_day/ s3://api-pyspark-airflow-1/api_results_partitioned/ && aws s3 sync /home/ubuntu/covid19_result/all_day/ s3://api-pyspark-airflow-1/api_results_onefile/

*S3에 복사를 하게 되는 경우 큰 문제점이 하나 생기는데, 매일 생성 되는 서버마다 돌리는 batch job이 각각 다른이름의 csv파일을 생성하게됩니다. 또한 이 생성된 파일은 복사를 하게되면 overwrite가 아닌 append개념이 되버리기 때문에, s3의 각 디렉토리에 파일이 매일같이 쌓이게되어 중복 데이터의 문제가 발생합니다
-> 결국에는 S3에 직접 overwrite로 쓰는 것으로 변경을 해야합니다.
4. airflow dag 구성하기
cd ~
cd airflow/dags
nano api_development_dag.pyapi_development_dag.py 생성
#api_development_dag.py
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'spidyweb',
'retries': 0,
'retry_delay': timedelta(seconds=20),
'depends_on_past': False
}
#현재시각은 2022년 2월 27일 9시 20분 이고 매일 오전 10시에 실행 되게끔 하루 단위로 schedule interval 설정
#한국 시각은 airflow 내에서의 시각보다 9시간 빠르므로 실행시키려는 시각의 9시간 전으로 실행
dag_Spark_api = DAG(
'dag_Spark_api_batch',
start_date=datetime(2022, 2, 28, 1, 00),
default_args=default_args,
schedule_interval='0 1 * * *',
catchup=False,
is_paused_upon_creation=False,
)
#pyspark job 실행
cmd="python3 /home/ubuntu/api_development_xml_pyspark.py"
#S3에 pyspark job 실행결과를 복사한다.
cmd2="echo 'copying api_result files to S3' && aws s3 sync /home/ubuntu/covid19_result/partition/all_day/ s3://api-pyspark-airflow-1/api_results_partitioned/ && aws s3 sync /home/ubuntu/covid19_result/all_day/ s3://api-pyspark-airflow-1/api_results_onefile/"
#S3에 airflow log를 복사한다.
cmd3="echo 'copying airflow log files to S3' && aws s3 sync /home/ubuntu/airflow/logs/dag_Spark_api_batch/spark_api_xml/ s3://api-pyspark-airflow-1/api_airflow_logs/"
#모든 작업이 끝나고 7분뒤에 EC2서버를 종료한다.
cmd4="echo ‘this server will be terminated after 7minutes’ && sleep 7m && aws ec2 terminate-instances --instance-id $(ec2metadata --instance-id)"
#시작을 알리는 dummy
task_start = DummyOperator(
task_id='start',
dag=dag_Spark_api,
)
#시작이 끝나고 다음단계로 진행되었음을 나타내는 dummy
task_next = DummyOperator(
task_id='next',
trigger_rule='all_success',
dag=dag_Spark_api,
)
#끝을 알리는 dummy
task_finish = DummyOperator(
task_id='finish',
trigger_rule='all_success',
dag=dag_Spark_api,
)
#오늘의 목표인 bash를 통해 python file 실행시킬 BashOperator
api_PySpark_1 = BashOperator(
task_id='spark_api_xml',
dag=dag_Spark_api,
trigger_rule='all_success',
bash_command=cmd,
)
#생성된 spark 결과물 파일을 s3로 복사하는 BashOperator
task_Copy_results_to_S3 = BashOperator(
task_id='copy_results',
dag=dag_Spark_api,
trigger_rule='all_success',
bash_command=cmd2,
)
#airflow log files 를 s3로 보내는 BashOperator
task_Copy_Log_to_S3 = BashOperator(
task_id='copy_log',
dag=dag_Spark_api,
trigger_rule='all_success',
bash_command=cmd3,
)
#ec2를 종료시키는 BashOperator
task_terminate_server = BashOperator(
task_id='terminate_server',
dag=dag_Spark_api,
trigger_rule='all_success',
bash_command=cmd4,
)
#의존관계 구성
task_start >> task_next >> api_PySpark_1 >> task_Copy_results_to_S3 >> task_Copy_Log_to_S3 >> task_finish >> task_terminate_serverwebserver 에 들어가 dag가 잘 생성되었는지 확인



5. EC2 이미지 저장
여기까지 해온 작업을 이미지로서 저장하겠습니다.
EC2 instances 들어가서 해당 instance 체크박스 클릭 -> image and templates -> create image 로 생성합니다.


6. airflow 작업 완료 확인
의도한대로 airflow가 작업이 완료된다면,
- pyspark job을 수행
- s3에 복사
- airflow log를 s3에 복사
- EC2의 instanceid를 받아 EC2를 자동으로 종료
의 결과를 확인하면 됩니다.
1.

2.

3.

4.


다음 포스트에는 EC2이미지를 통해 자동으로 서버를 띄우고, 결론 및 보완할 점을 정리하겠습니다.




댓글