1. requests
- Requests 는 파이썬에서 HTTP를 사용하기 위해 쓰여지는 라이브러리 데이터를 보낼 때 딕셔너리 형태로 보낸다
- 없는 페이지를 요청해도 에러를 띄우지 않는다
어떤 방식(method)의 HTTP 요청을 하느냐에 따라서 해당하는 이름의 메소드를 사용
- GET 방식: requests.get()
- POST 방식: requests.post()
- PUT 방식: requests.put()
- DELETE방식: requests.delete()
response
요청(request)을 보내면 응답(response)을 python 객체로 받음
response = requests.get("url~~")
# 내가 보낸 request 객체에 접근 가능
response.request # <PreparedRequest [GET]> 출력
# 응답 코드
response.status_code # 정상인 경우 200 출력
# 200 (OK 코드)이 아닌 경우 에러 raise
response.raise_for_status()
# json response일 경우 딕셔너리 타입으로 바로 변환
response.json()
# content 속성을 통해 바이너리 타입(byte)으로 데이터를 받을 수 있다.
# 바이너리타입을 받아야 하는 이미지를 받을 때 주로사용
response.content # byte type
#text 속성을 통해 유니코드 타입으로 데이터를 받을 수 있다.
response.text # str typeresponse.content 출력

response.text 출력

2. URLlib
- 파이썬에서는 웹과 관련된 데이터를 쉽게 다룰 수 있도록 urllib모듈을 제공
- 데이터를 보낼 때 인코딩하여 바이너리 형태로 보낸다
- 없는 페이지를 요청하면 에러를 띄운다
URL을 파싱하는 모듈
urllib.parse
from urllib import parse
url = parse.urlparse("https://www.4xr.co.kr/ranking/goods_list.php?cate=01")
print(url)
# parseResult(scheme='https', netloc='www.4xr.co.kr', path='/ranking/goods_list.php', params='', query='cate=01', fragment='')웹 페이지 요청 및 데이터를 가져오는 모듈
urllib.request
from urllib import request
response = request.urlopen("https://www.4xr.co.kr/ranking/goods_list.php?cate=01")
print(response.read().decode("utf-8"))
print(type(request.read().decode("utf-8"))) # <class 'str'> 출력text형식 (str)으로 가져온다.
response.read().decode("utf-8") 출력

query 변수와 parse_qs 함수
- 쿼리 스트링을 가져오기 위해서는 urlparse함수를 통해 반환된 객체의 query 변수와 parse_qs 함수를 이용
- 리턴 타입이 딕셔너리(dictionary)
from urllib import parse
url = parse.urlparse("https://www.4xr.co.kr/ranking/goods_list.php?cate=01")
print (parse.parse_qs(url.query))
# {'cate': ['01']}
print(parse.parse_qs(url.query)['cate'][0])
# '01'*URL의 ?다음에 오는 것들을 쿼리스트링이라 하며, key=value 형태로 구성되어 있다.
3. BeautifulSoup4(bs4)
HTML정보로 부터 원하는 데이터를 가져오기 쉽게, 비슷한 분류의 데이터별로 나누어주는(parsing) 파이썬 라이브러리
BeautifulSoup를 사용한 여러가지 파싱방법
- html.parser
- lxml
- html5lib
- xml
soup = BeautifulSoup(response.text, "html.parser")
#속도 중간
#<b/>처럼 유효하지 않은 태그를 <b></b> 쌍으로 만듦
#<a></p>와 같은 유효하지않은 태그를
#<a></a>처럼 만듦 시작 태그는 쌍으로 만들고, 끝 태그는 무시되는 개념
soup = BeautifulSoup(response.text, "lxml")
#속도 매우빠름
#완전한 형태의 html를 파싱하는 경우 빠르며
#결과로 원본html문서의 자료구조를 반환할 것이다.
#</b>처럼 혼자 있는 태그는 무시된다.
soup = BeautifulSoup(response.text, "html5lib")
#속도 매우느림
#완전한 형태의 html를 파싱하는 경우 빠르며
#결과로 원본html문서의 자료구조를 반환할 것이다.
#</b>처럼 혼자있는 태그를 <b></b>쌍으로 만든다.
#<head></head>가 없는 경우 추가시킨다.
soup = BeautifulSoup(response.text, "xml")
#속도 매우빠름
#html이 아닌 xml로 선언하며 <b/>처럼 유효하지
#않은 코드는 그대로 유효하지않은 태그로 있게된다.*response.text vs response.content
response.text는 str타입(unicode)이고, response.content는 bytes타입

BeautifulSoup Method
- select()
select 메소드의 경우, CSS Selector로 tag 객체를 찾아 리스트로 반환 (bs4.element.ResultSet)
#태그 찾기
soup.select("title")
#특정 태그 아래에 있는 태그 찾기
soup.select("div a") #div 태그 아래에 있는 a 태그 찾기
#특정 태그 바로 아래에 있는 태그 찾기
soup.select("head > title")
soup.select("head > #link1") #아이디로 태그 찾음
#태그들의 형제 태그 찾기
soup.select("#link1 ~ .sister")
soup.select("#link1 + .sister")
#CSS class로 태그 찾기
soup.select(".sister")
#ID값으로 태그 찾기
soup.select("#link1")- select_one()
select_one()은 추출된 태그들 중에 첫 번째 값만 반환하고 select()는 리스트에 추출된 태그들을 모두 담아 해당 리스트를 반환 (find()와 같음) (bs4.element.tag)
- find()
조건에 맞는 태그가 1개이상 이면 첫 번째 값을 가져옴 (bs4.element.tag)
tag = "<p class='example' id='test01'> Hello World! </p>"
soup = BeautifulSoup(tag)
# 태그 이름만 특정
soup.find('p')
# 태그 속성만 특정
soup.find(class_='example')
soup.find(attrs = {'class':'exmaple'})
# 태그 이름과 속성 모두 특정
soup.find('p', class_='example')- find_all()
조건에 맞는 태그를 전부 가져옴 (bs4.element.ResultSet)
select vs find
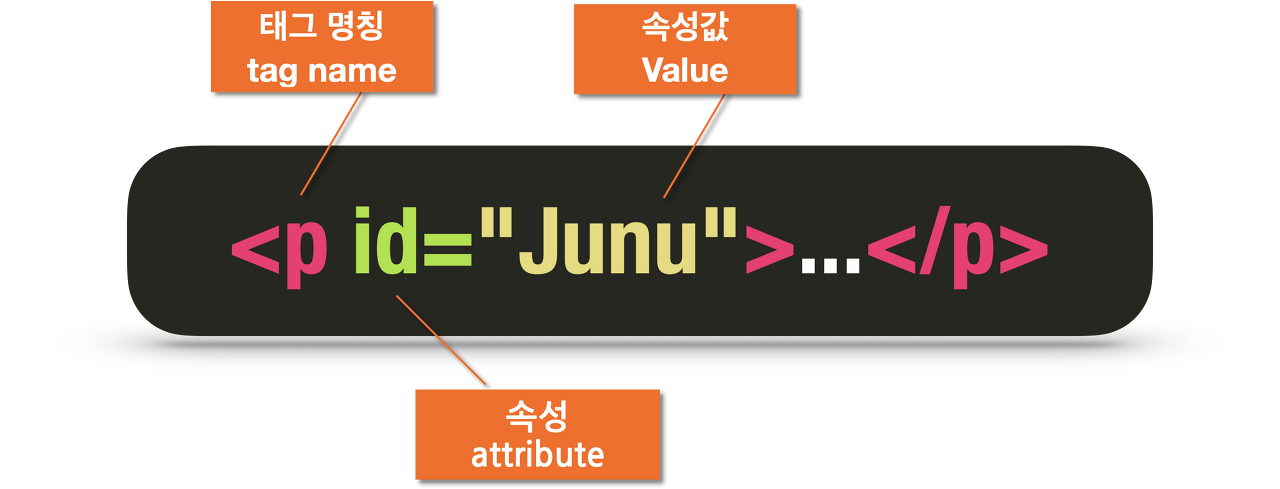
- find와 select는 태그 이름, 속성, 속성값을 특정하는 방식은 같음
- CSS는 이 외에도 다양한 선택자(selector)를 갖기 때문에 여러 요소를 조합하여 태그를 특정하기 쉬움
- 예를 들어 특정 경로의 태그를 객체로 반환하고 싶을 때, find의 경우 아래와 같이 반복적으로 코드를 작성해야 하는 반면 select는 직접 하위 경로를 지정
#find
soup.find('div').find('p')
#select
soup.select_one('div > p')CSS Selector(선택자)란?
CSS 선택자는 특정한 HTML 태그를 선택할 때 사용하는 기능으로 선택자를 이용하여 특정 HTML 태그를 선택하면 해당 태그에 원하는 스타일이나 기능을 적용할 수 있게 됨.
tag에서 값 추출하기
import requests # Python 프로그래밍 언어용 HTTP 라이브러리
from bs4 import BeautifulSoup # HTML과 XML 문서를 파싱하기위한 파이썬 패키지
import re
url = "https://www.4xr.co.kr/ranking/goods_list.php?cate=01"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.content, "lxml")- b tag와 내용 찾기
print(soup.b)
- b tag의 내용 찾기
NavigableString이면서 자녀가 하나밖에 없는 경우 string사용
print(soup.b.string)
#<class 'bs4.element.NavigableString'>이므로
#str으로 사용하려면 str(soup.b.string) 타입변환을 해줘야 함

- head tag 추출하기
print(soup.head)
- title tag 추출하기
print(soup.title)
- body tag 추출하기
print(soup.body)
- tag의 contents 추출하기
tag가 bs4.element.Tag인 것 중, tag와 white space문자,text까지 리스트로 불러 올 때, contents사용가능
print(soup.contents) # list의 형태로 반환한다.- tag의 text 추출하기
tag가 bs4.element.Tag인 것 중 사람만 읽을 수 있는 text를 원할 때, text사용
print(soup.text) # string 형태로 반환한다.
print(soup.get_text()) # string 형태로 반환한다.*text vs get_text()
- .text는 get_text()에 아무런 인자를 주지 않았을 때와 같음.
- get_text는 get_text(separator,strip,types)와 같은 매개변수를 갖고 있음.
*아직 bs4의 활용에 따른 글 정리를 깔끔하게 하지 못했습니다. 추후에 수정해 나가도록 하겠습니다.
참조:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#navigating-the-tree
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object, or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str() function returns a str
www.crummy.com
2022-07-05 최초작성
'language > Python' 카테고리의 다른 글
| [Python] pandas vs pyspark 사용 및 코드 비교 (0) | 2022.09.22 |
|---|---|
| [Python] Numpy library 개념, 기본 사용법 (0) | 2022.07.12 |
| [Python] 보편적인 python coding convention(파이썬 코딩 컨벤션) (0) | 2022.04.27 |
| [Python] re 모듈, 정규 표현식(정규식) 개념과 완전 정복하기(regex cheat sheet) SQL, HIVE, PySpark에서의 regex (0) | 2022.04.09 |
| [Python] generator 개념 및 예제 (feat. iterator) (0) | 2022.04.07 |


댓글