728x90
이번 포스트에는 Athena를 통해 Glue Catalog에 데이터베이스와 테이블을 생성하는 방법을 포스팅 하겠습니다.
*IAM에서 S3, Athena, Glue에 대한 FullAccess 정책을 부여 받았다고 가정하고 실행
1. 일반적인 EXTERNAL TABLE 생성
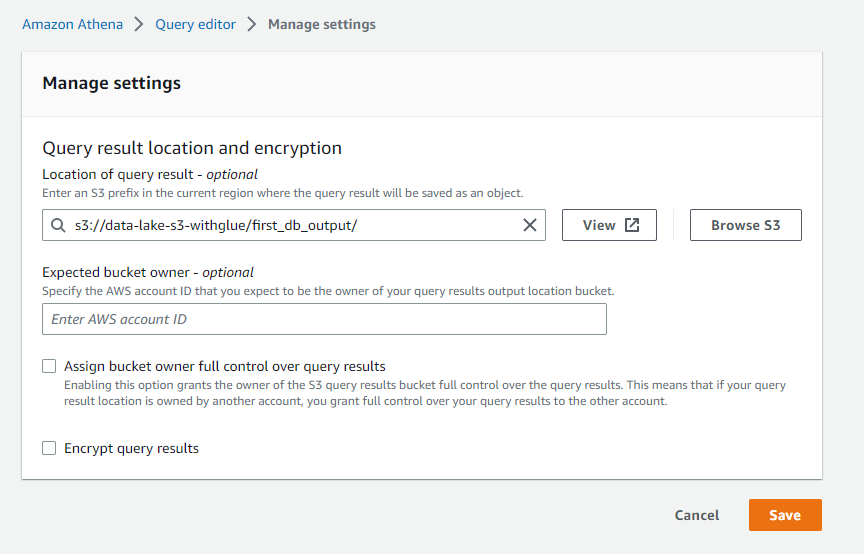
1) 결과 파일 s3경로 지정
settings의 manage 클릭

manage settings의 browse s3로 결과가 담길 S3 URI를 지정
2) database 생성
문법
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT 'database_comment']
[LOCATION 'S3_loc']
[WITH DBPROPERTIES ('property_name' = 'property_value') [, ...]]실제 생성
CREATE DATABASE first_db
COMMENT 'first_database'
LOCATION 's3://data-lake-s3-withglue/first_db/'생성된 데이터베이스 확인
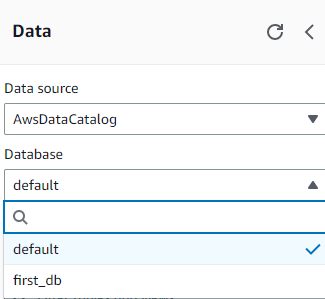
3) table 생성
문법
CREATE EXTERNAL TABLE [IF NOT EXISTS]
[db_name.]table_name [(col_name data_type [COMMENT col_comment] [, ...] )]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[WITH SERDEPROPERTIES (...)]
[LOCATION 's3://bucket_name/[folder]/']
[TBLPROPERTIES ( ['has_encrypted_data'='true | false',] ['classification'='aws_glue_classification',] property_name=property_value [, ...] )실제 생성
CREATE EXTERNAL TABLE IF NOT EXISTS first_db.tab1(
col1 string COMMENT 'column1',
col2 string COMMENT 'column2',
col3 bigint COMMENT 'column3',
col4 string COMMENT 'column4'
)
COMMENT 'table1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://data-lake-s3-withglue/first_db/tab1/'
TBLPROPERTIES ('classification'='csv')* 참고로 big data 개념에 맞게 athena(glue catalog)에는 PK 및 FK의 개념이 없음
생성된 테이블 확인
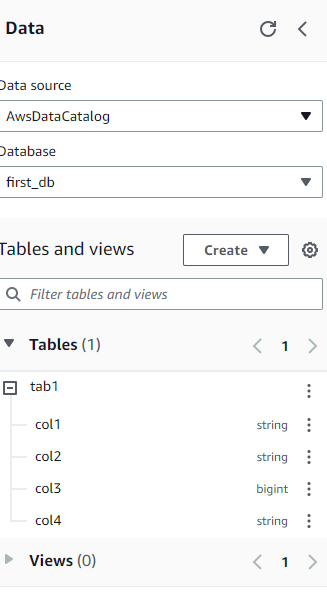
4) 데이터 insert
INSERT INTO first_db.tab1 VALUES
('first','one',1,'하나'),
('second','two',2,'둘'),
('third','three',3,'셋'),
('fourth','four',4,'넷'),
('fifth','five',5,'다섯'),
('sixth','six',6,'여섯'),
('seventh','seven',7,'일곱')데이터(파일) 생성 확인

데이터 조회
select *
from first_db.tab12. CTAS(Create Table As Select)
버킷 내에 폴더가 생성되지 않아 있어도, 로케이션을 주면 자동으로 생성 됨
CREATE TABLE first_db.ctas_tab1
WITH (format = 'parquet',
write_compression = 'SNAPPY',
external_location = 's3://data-lake-s3-withglue/first_db/ctas_tab1/'
)
AS SELECT *
FROM first_db.tab1테이블 정보 확인
SHOW CREATE TABLE first_db.ctas_tab1
데이터(파일) 생성 확인
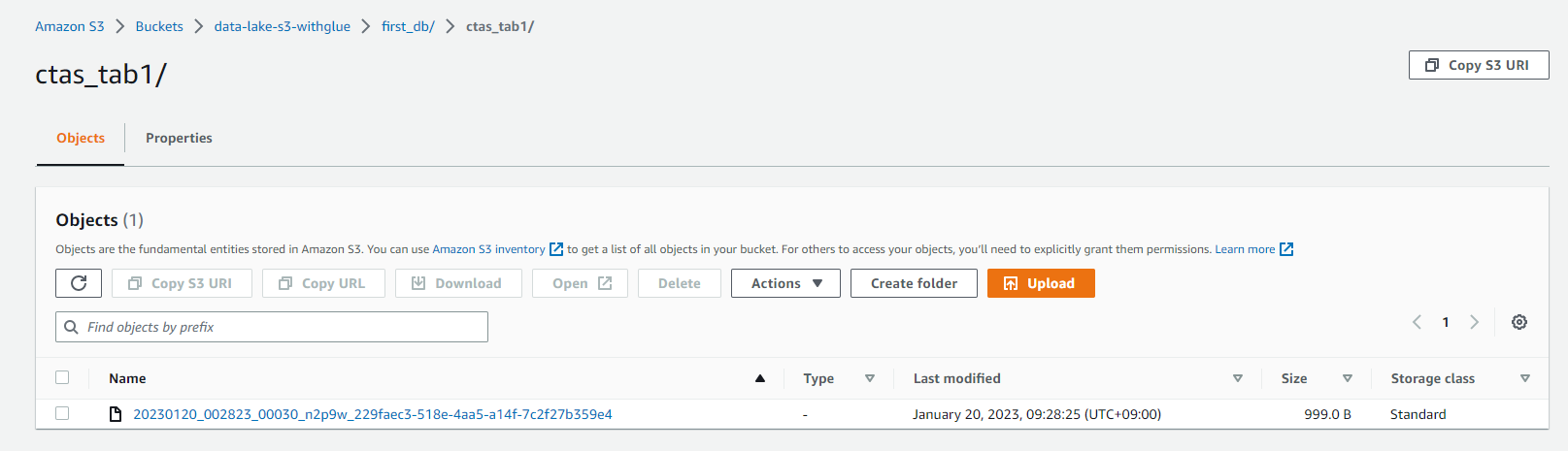
데이터 조회

3. SELECT INSERT INTO
1) tab2 생성
tab1과 컬럼의 데이터형식이 동일해야 한다(그래야 데이터가 잘리지도 않을 뿐더러 같은 형식으로 들어오게 된다.)
CREATE EXTERNAL TABLE IF NOT EXISTS first_db.tab2(
col1 string,
col2 string,
col3 bigint,
col4 string
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://data-lake-s3-withglue/first_db/tab2/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'parquet.compression'='SNAPPY',
'presto_query_id'='20230120_002823_00030_n2p9w')2) 데이터 입력
INSERT INTO first_db.tab2
SELECT *
FROM first_db.tab1데이터(파일) 생성 확인
데이터 조회
SELECT *
FROM first_db.tab2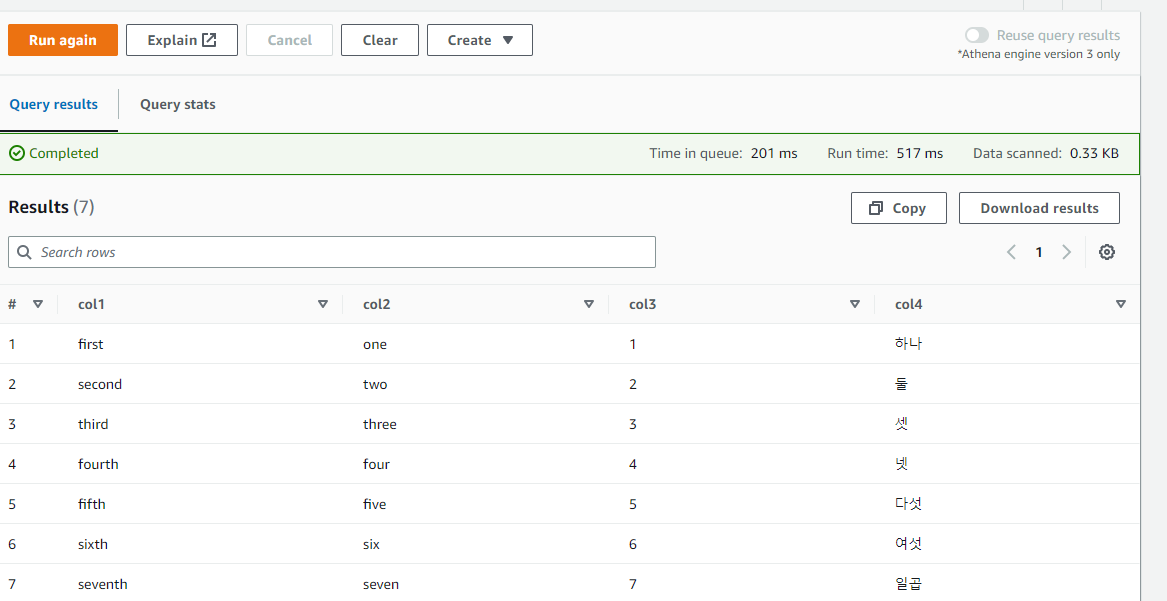
4. Glue Data Catalog에서 생성된 DB, Table 확인


728x90
'Cloud > AWS Cloud Computing' 카테고리의 다른 글
| [AWS] Landing Zone과 AWS Control Tower 정리 (0) | 2023.01.31 |
|---|---|
| [AWS] IAM vs Lakeformation 권한 관리 차이 정리 (0) | 2023.01.31 |
| [AWS] RDS(Relational Database Service) vs AuroraDB (feat. MySQL, PostgreSQL) (0) | 2022.12.28 |
| [AWS] ec2 instance stop vs terminate 인스턴스 중지와 종료의 차이 (0) | 2022.02.11 |
| [AWS] EC2 의 vCPU, vCore, core당 스레드(논리 프로세서), yarn에서 vcore할당 비교 (0) | 2021.12.10 |



댓글