728x90
[File 크기]
컬럼 수: 21개의 컬럼
레코드 수: 총 3,647,595 rows(records)
csv: 578MB
parquet: 44.7MB
(gz.parquet: 34.6MB)
[비교 관점]
spark에서의 성능이란 file을 스캔할 때 스캔한 양(읽어들인 양)과 스캔시간이 중요
[CSV vs Parquet 특징 비교] (json은 덤ㅎㅎ)
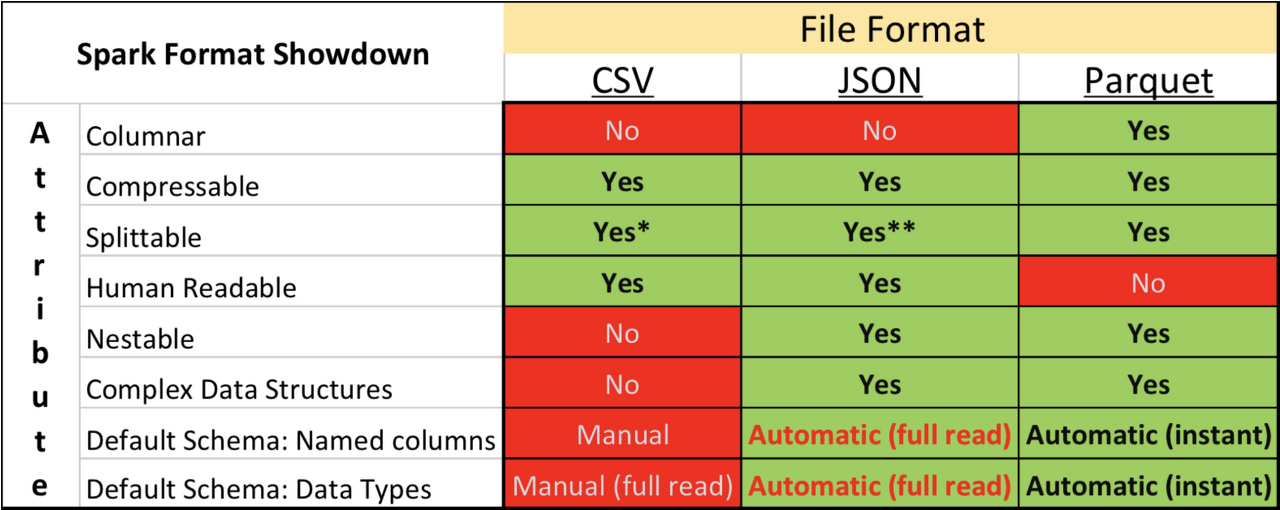
1. CSV
csv는 일반적인 text, 즉 row단위로 읽는 file format
1) 1개의 column select
df_csv.select(F.col("Exam_No")).show(100000)Physical plan

== Physical Plan ==
CollectLimit (3)
+- * Project (2)
+- Scan csv (1)
(1) Scan csv
Output [1]: [Exam_No#16]
Batched: false
Location: InMemoryFileIndex [file:/C:/Users/유저이름/Downloads/origin_csv]
ReadSchema: struct<Exam_No:int>
(2) Project [codegen id : 1]
Output [1]: [cast(Exam_No#16 as string) AS Exam_No#102]
Input [1]: [Exam_No#16]
(3) CollectLimit
Input [1]: [Exam_No#102]
Arguments: 100001
Stage
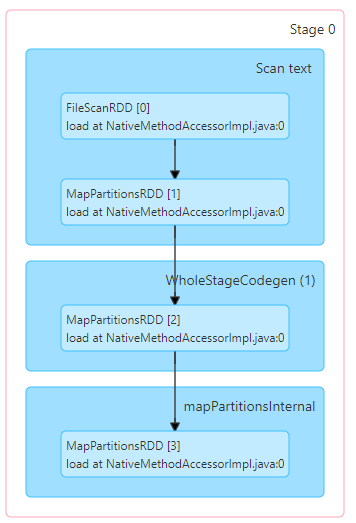







* 100,000rows가 아닌 4096row만 select한다면?

지정한 records가 줄면 scan한 데이터(input size)도 적어진다.
2) 전체 컬럼 select
df_csv.select("*").show(100000)Stage



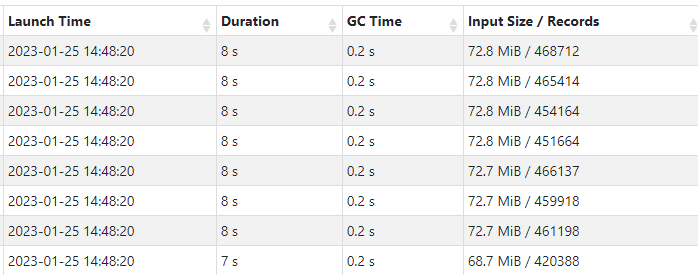




3) 결론
- 하나의 컬럼과 전체컬럼의 10만 rows를 읽을 때 스캔된(읽어들인) 양은 15.9MiB로 동일
- 지정한 row 수가 달라지면 파일을 scan(input size)하는 데이터 양이 달라진다. (100,000개 15.9MiB, 4096개 712KiB)
- 하나의 컬럼과 전체컬럼의 10만 rows를 읽을 때 소요된 시간은 읽어들인 데이터의 크기자체가 매우 적기 때문에, 시간 또한 매우 적게 나오게되므로 차이가 나진 않지만, 같은 크기의 데이터를 스캔했으므로, 동일할 것으로 보임(네트워크 등 다른 지연시간을 제외한 순수 작업에 걸린시간)
- row 기반 컬럼 특징상 지정한 row 수에 따라 스캔에 소요되는 시간이 달라지게 됨
2. Parquet
1) 1개의 컬럼 select
df_parquet.select(F.col("Exam_No")).show(100000)Physical plan

== Physical Plan ==
CollectLimit (3)
+- * Filter (2)
+- Scan text (1)
(1) Scan text
Output [1]: [value#0]
Batched: false
Location: InMemoryFileIndex [file:/C:/Users/유저이름/Downloads/origin_csv/part-00000-0476ec4f-9d04-40c3-8038-b5ad47c08648-c000.csv, ... 7 entries]
ReadSchema: struct<value:string>
(2) Filter [codegen id : 1]
Input [1]: [value#0]
Condition : (length(trim(value#0, None)) > 0)
(3) CollectLimit
Input [1]: [value#0]
Arguments: 1

parquet는 csv와 다르게 scan time이 나오게 되는데, 필요한 데이터의 parquet file을 스캔하면서 소요된 시간을 의미
== Physical Plan ==
CollectLimit (4)
+- * Project (3)
+- * ColumnarToRow (2)
+- Scan parquet (1)
(1) Scan parquet
Output [1]: [Exam_No#58]
Batched: true
Location: InMemoryFileIndex [file:/C:/Users/유저이름/Downloads/origin_parquet]
ReadSchema: struct<Exam_No:int>
(2) ColumnarToRow [codegen id : 1]
Input [1]: [Exam_No#58]
(3) Project [codegen id : 1]
Output [1]: [cast(Exam_No#58 as string) AS Exam_No#102]
Input [1]: [Exam_No#58]
(4) CollectLimit
Input [1]: [Exam_No#102]
Arguments: 100001
Stage




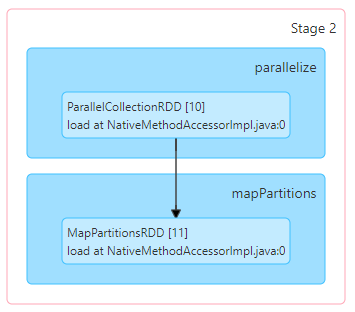



*1batch 단위의 records(4096rows)를 show()한다면?

columnar특성 상 지정한 record 수가 한 개의 물리 파일 내에 존재한다면, 해당 파일의 한 개의 컬럼 만을 스캔 하기 때문에, 레코드 수와 관계없이 동일한 양의 스캔을 함(405.9KiB)
*1개가 아닌 2개의 column을 show()한다면?

columnar 특성 상 지정한 column수가 늘어나면 input size도 그에 맞게 증가 함
2) 전체컬럼 select
df_parquet.select("*").show(100000)
"""
df_parquet.select(F.col("Exam_No"),
F.col("List_No"),
F.col("First_Name"),
F.col("MI"),
F.col("Last_Name"),
F.col("List_Agency_code"),
F.col("List_Agency_Desc"),
F.col("List_Title_Desc"),
F.col("Cert_Seq_No"),
F.col("Request_Date"),
F.col("Salary"),
F.col("Cert_Issue_No"),
F.col("Cert_Date"),
F.col("Reissue_Date"),
F.col("Cert_Expiration_Date"),
F.col("No_Certified"),
F.col("No_Requested"),
F.col("Provisional_Replacement"),
F.col("No_Vacancies"),
F.col("List_Title_Code"),
F.col("Sel_Cert_Description")).show(100000)
일일히 지정하나, select("*")하나 카탈리스트 옵티마이저의 동일한 쿼리플랜에 의해 동일하게 적용 됨
"""Physical plan

== Physical Plan ==
CollectLimit (3)
+- * Filter (2)
+- Scan text (1)
(1) Scan text
Output [1]: [value#0]
Batched: false
Location: InMemoryFileIndex [file:/C:/Users/유저이름/Downloads/origin_csv/part-00000-0476ec4f-9d04-40c3-8038-b5ad47c08648-c000.csv, ... 7 entries]
ReadSchema: struct<value:string>
(2) Filter [codegen id : 1]
Input [1]: [value#0]
Condition : (length(trim(value#0, None)) > 0)
(3) CollectLimit
Input [1]: [value#0]
Arguments: 1text를 scan한 양은 말그대로 글자의 크기를 스캔한 크기라서 csv,parquet와 무관하게 데이터 크기는 동일

parquet는 csv와 다르게 scan time이 나오게 되는데, 필요한 데이터의 parquet file을 스캔하면서 소요된 시간을 의미
== Physical Plan ==
CollectLimit (4)
+- * Project (3)
+- * ColumnarToRow (2)
+- Scan parquet (1)
(1) Scan parquet
Output [21]: [Exam_No#58, List_No#59, First_Name#60, MI#61, Last_Name#62, List_Agency_code#63, List_Agency_Desc#64, List_Title_Desc#65, Cert_Seq_No#66, Request_Date#67, Salary#68, Cert_Issue_No#69, Cert_Date#70, Reissue_Date#71, Cert_Expiration_Date#72, No_Certified#73, No_Requested#74, Provisional_Replacement#75, No_Vacancies#76, List_Title_Code#77, Sel_Cert_Description#78]
Batched: true
Location: InMemoryFileIndex [file:/C:/Users/유저이름/Downloads/origin_parquet]
ReadSchema: struct<Exam_No:int,List_No:double,First_Name:string,MI:string,Last_Name:string,List_Agency_code:int,List_Agency_Desc:string,List_Title_Desc:string,Cert_Seq_No:double,Request_Date:string,Salary:double,Cert_Issue_No:int,Cert_Date:string,Reissue_Date:string,Cert_Expiration_Date:string,No_Certified:int,No_Requested:int,Provisional_Replacement:string,No_Vacancies:int,List_Title_Code:int,Sel_Cert_Description:string>
(2) ColumnarToRow [codegen id : 1]
Input [21]: [Exam_No#58, List_No#59, First_Name#60, MI#61, Last_Name#62, List_Agency_code#63, List_Agency_Desc#64, List_Title_Desc#65, Cert_Seq_No#66, Request_Date#67, Salary#68, Cert_Issue_No#69, Cert_Date#70, Reissue_Date#71, Cert_Expiration_Date#72, No_Certified#73, No_Requested#74, Provisional_Replacement#75, No_Vacancies#76, List_Title_Code#77, Sel_Cert_Description#78]
(3) Project [codegen id : 1]
Output [21]: [cast(Exam_No#58 as string) AS Exam_No#142, cast(List_No#59 as string) AS List_No#143, First_Name#60, MI#61, Last_Name#62, cast(List_Agency_code#63 as string) AS List_Agency_code#147, List_Agency_Desc#64, List_Title_Desc#65, cast(Cert_Seq_No#66 as string) AS Cert_Seq_No#150, Request_Date#67, cast(Salary#68 as string) AS Salary#152, cast(Cert_Issue_No#69 as string) AS Cert_Issue_No#153, Cert_Date#70, Reissue_Date#71, Cert_Expiration_Date#72, cast(No_Certified#73 as string) AS No_Certified#157, cast(No_Requested#74 as string) AS No_Requested#158, Provisional_Replacement#75, cast(No_Vacancies#76 as string) AS No_Vacancies#160, cast(List_Title_Code#77 as string) AS List_Title_Code#161, Sel_Cert_Description#78]
Input [21]: [Exam_No#58, List_No#59, First_Name#60, MI#61, Last_Name#62, List_Agency_code#63, List_Agency_Desc#64, List_Title_Desc#65, Cert_Seq_No#66, Request_Date#67, Salary#68, Cert_Issue_No#69, Cert_Date#70, Reissue_Date#71, Cert_Expiration_Date#72, No_Certified#73, No_Requested#74, Provisional_Replacement#75, No_Vacancies#76, List_Title_Code#77, Sel_Cert_Description#78]
(4) CollectLimit
Input [21]: [Exam_No#142, List_No#143, First_Name#60, MI#61, Last_Name#62, List_Agency_code#147, List_Agency_Desc#64, List_Title_Desc#65, Cert_Seq_No#150, Request_Date#67, Salary#152, Cert_Issue_No#153, Cert_Date#70, Reissue_Date#71, Cert_Expiration_Date#72, No_Certified#157, No_Requested#158, Provisional_Replacement#75, No_Vacancies#160, List_Title_Code#161, Sel_Cert_Description#78]
Arguments: 100001
Stage








3) 결론
- parquet는 batch단위(여기서는 4096records)로 records를 읽음(columnarReaderBatchSize의 default 값이 4096)
→ 100,000 rows를 요청해도 4096개 단위인 102,400 records를 불러옴 - columnar특성 상 지정한 record 수가 한 개의 물리 파일 내에 존재한다면, 해당 파일의 한 개의 컬럼 만을 스캔 하기 때문에, 레코드 수와 관계없이 동일한 양의 스캔을 함
→ 파일의 전체 레코드 수를 기준으로 스캔 후 요청한 양 만큼만 보여줌 - columnar 특성 상 지정한 컬럼 수가 많으면 스캔하는 데이터의 크기도 늘어 남 1개(405.0KiB) 2개(1.3MiB) 19개(7.3MiB)
- Physical plan에서 1개의 컬럼과 모든 컬럼(21개)의 scan time(읽어들이는 시간)의 차이는 245ms vs 1.4s, columnar 는 지정한 컬럼만 읽어 들임
728x90
'BigData > Spark & Spark Tuning' 카테고리의 다른 글
| [Spark] spark dataframe -> RDB로 적재하기 (2) | 2023.07.10 |
|---|---|
| [Spark] Scala Spark 앱 만들기 (feat. Intellij) (0) | 2023.06.17 |
| [Spark Tuning] PartitionFilters vs PushedFilter 비교, predicate pushdown vs projection pushdown (0) | 2023.01.01 |
| [Spark] PySpark read & write + partitioning 간단한 예시문제 (2) | 2022.08.23 |
| [Spark] 스파크의 문법적 자유도, 스키마 조작, dummy 생성 (0) | 2022.03.26 |




댓글