이번 포스트에는 회사에서 수동으로 처리하고 있던 일회성 ETL작업을 Airflow DAG으로 묶어서 파이프라인을 만든 경험에대해서 소개해드리겠습니다.
기존 업무 처리방식과 Airflow DAG의 필요성
ETL 방식

우리가 처리하는 ETL방식은 ETL요청이 들어왔을 때, 최초 적재 → 증분값 daily하게 배치로 적재 하는 개념이였습니다.
ETL 최초 적재 세부 과정
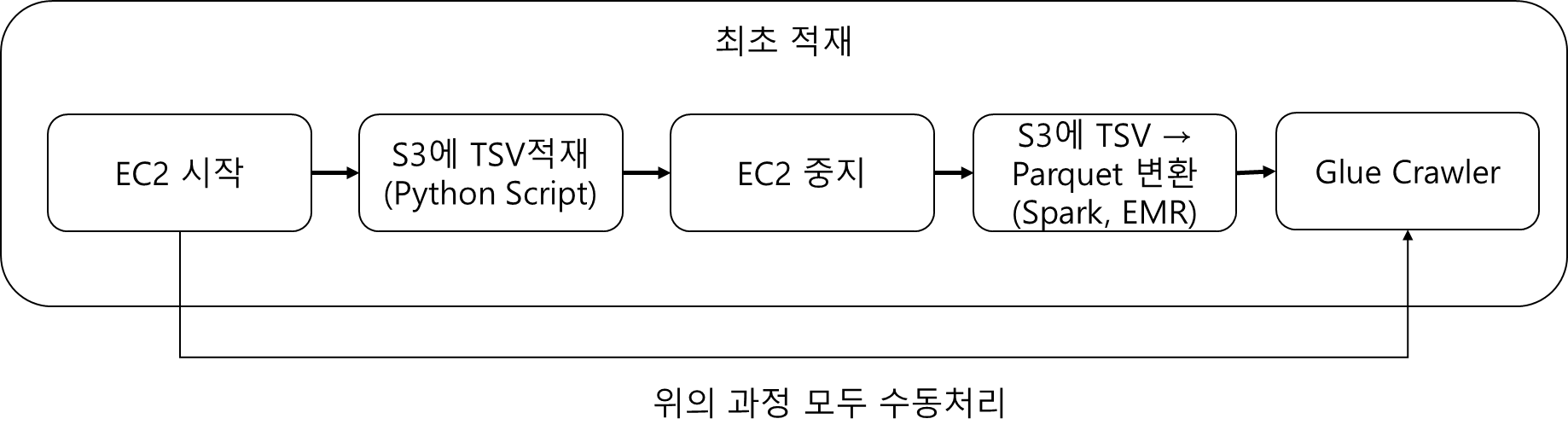
위의 과정을 거쳐 1개의 테이블에 대한 ETL과정이 끝납니다. (정확히는 우리는 data lake형태로 사용하고 있어, ELT입니다.)
언급 된대로 위의 과정을 일일히 서버를 키고, 서버에 명령어 날리고 zeppelin에 들어가서 코드 날리고 그러한 과정들이 모두 수동으로 이뤄지다보니, 되게 간단한 작업임에도 불구하고, 일처리하는데 있어서는 제법 시간을 소모했었습니다.
Airflow DAG의 필요성
위의 최초 적재 과정이 모두 Airflow DAG로써 묶을 수 있는 작업들이였고, TSV 적재 혹은 parquet 변환 작업은 기존에 사용하고 있던 EC2 서버와 상시로 띄워진 EMR을 사용하기만 하면 됐습니다.
그래서 수동으로 처리하던 각 작업을 Airflow DAG로 묶어 일괄처리하는 자동화 파이프라인을 만들어 보기로 했습니다.
DAG 구성
구성 계획
이왕 Airflow로 각 작업들을 묶어서 구성하는 김에 추가 기능이 있으면 좋겠다고 생각했는데,
1. ETL을 요청한 사람에게 완료됐음을 알리는 Email을 보내는 기능
2. 처리한 상세 결과를 Slack에 받아보는 기능
3. 우리 사내에 구축한 DMP(BigData Platform)에 ETL처리가 완료됐음을 자동으로 반영하는 기능
까지도 추가됐으면 좋겠다고 생각했습니다.
따라서 최종적으로 구성된 DAG의 각 Task flow는 아래와 같습니다.
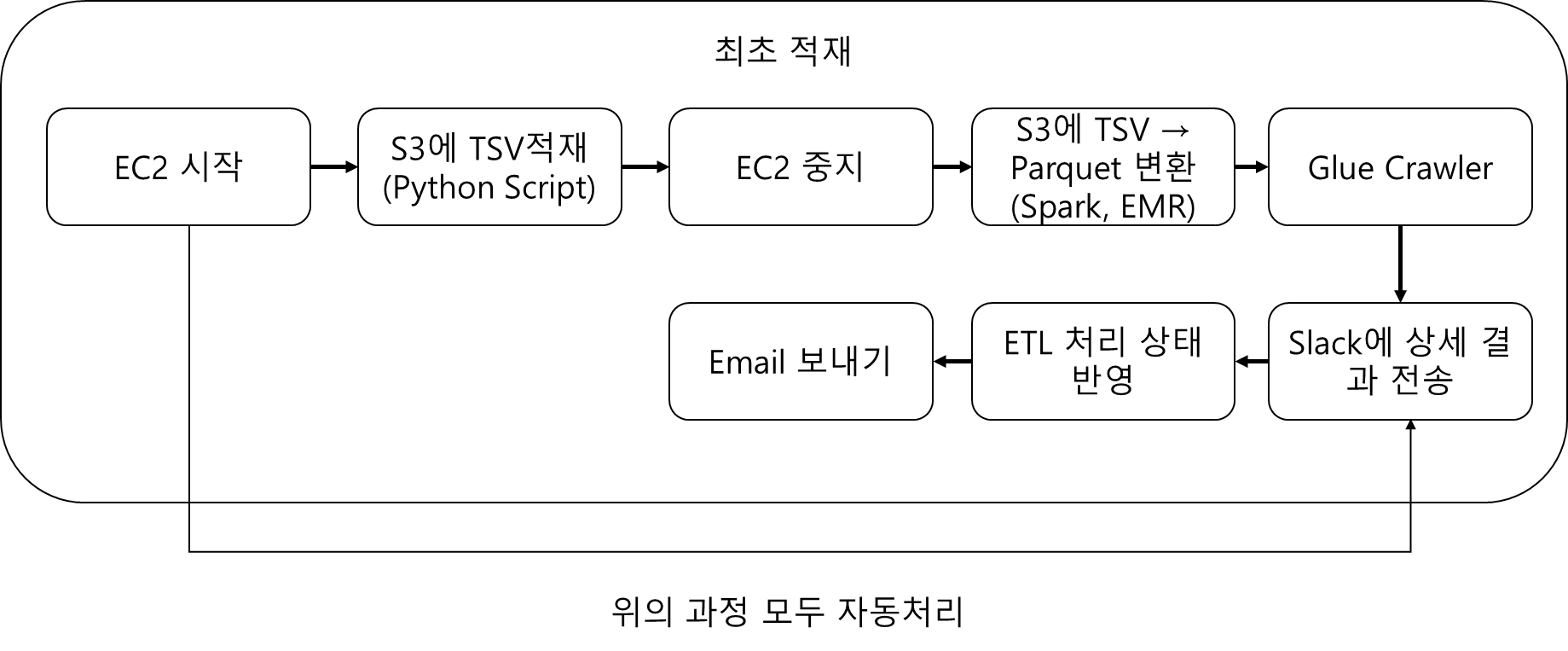
각 Task 별 작업 내용
1. EC2 시작
airflow provider에서 제공하는 EC2 시작시키는 Operator를 사용하여 TSV 생성 작업을 하기위해 해당하는 EC2 서버를 켜는 Task로 시작을 구성했습니다.
from airflow.providers.amazon.aws.operators.ec2 import EC2StartInstanceOperator
start_ec2_task = EC2StartInstanceOperator(
task_id='start_ec2_task',
instance_id=instance_id,
aws_conn_id='aws_default', # Specify the Airflow connection ID containing your AWS credentials
region_name=region_name,
dag=dag
)2. S3에 TSV적재(Python Script)
시작된 EC2 서버에 기존에 ETL하던 명령어를 전달하여 실행시키기 위해 BashOperator를 통해 해당 서버에 명령어를 전달했는데, 여기서 파라미터를 건네주는데 엄청나게 많은 시간을 소비했습니다.
아래와 같은 명령어로 파라미터를 넘겨주어 context나 kwargs를 받아 사용하려는 방법으로 많이 리서칭을 해봤으나, 결국은 전역변수로써 저장할 수 밖에 없었습니다.
# 처음에 사용해본 방법
airflow dags trigger -c {json으로 구성된 파라미터들} dag_id파라미터 중에 테스크 타입을 나타내는 파라미터가있는데 그 값들에 따라 if문으로 분기처리를 했어야 했기 때문에
전역 변수인 Variables를 사용했습니다.
# TSV파일 생성 시 아래와 같은 Taskflow의 분기처리가 필요했다.
if 파라미터1 = 'A':
Taskflow1
elif 파라미터1 = 'B' or 파라미터1 = 'C':
Taskflow2아래의 명령어로 airflow Variables 설정과 동시에 dag 수동으로 제출
# airflow 서버에서 airflow dag을 수동으로 제출하기 전에 Variable에 변수를 생성하는 작업을 먼저했다.
/airflow 경로/airflow variables set 변수에사용될키 "{\"파라미터1\": \"파라미터값1\", \"파라미터2\": \"파라미터값2\",
\"파라미터3\": \"파라미터값3\", \"파라미터4\": \"파라미터값4\", \"파라미터5\": \"파라미터값5\"}" &&
/airflow 경로/airflow dag trigger dag_id그래서 정의한 전역변수로 아래와 같은 BashOperator에 파라미터값을 사용할 수 있었습니다.
tsv_to_s3 = BashOperator(
task_id='tsv_to_s3',
bash_command=f'/python file 경로/파이썬파일이름.py {파라미터1} {파라미터2} {파라미터3}',
dag=dag
)3. EC2 중지
airflow provider에서 제공하는 EC2 중지시키는 Operator를 사용하여 TSV 생성 작업이 끝나면 중지 시키게끔 구성했습니다.
from airflow.providers.amazon.aws.operators.ec2 import EC2StopInstanceOperator
stop_ec2_task = EC2StopInstanceOperator(
task_id='stop_ec2_task',
instance_id=instance_id,
aws_conn_id='aws_default', # Specify the Airflow connection ID containing your AWS credentials
region_name=region_name,
dag=dag
)4. S3에 TSV → Parquet 변환(Spark, EMR)
TSV에서 Parquet로 변환하는 코드를 그대로 사용할 계획이였고, 이미 띄워져있는 상시 EMR에다 Spark Code를 제출할 Task가 필요했습니다.
from airflow.providers.amazon.aws.operators.emr_add_step import EMRAddStepOperator
emr_step = {
'Name': 'My EMR Step',
'ActionOnFailure': 'CONTINUE',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': [
'spark-submit',
'--class', 'jar파일 내 클래스명',
'/usr/lib/spark/examples/jars/스파크코드.jar',
'--파라미터1','파라미터1값','--파라미터2','파라미터2값'
]
},
}
add_step_task = EMRAddStepOperator(
task_id='add_step_task',
job_flow_id="EMR고유번호",
aws_conn_id='aws_default', # Specify the Airflow connection ID containing your AWS credentials
step=emr_step,
dag=dag
)여기서 문제가 하나 또 발생했는데,
EMRAddStepOperator는 EMR에 제출하자마자 Airflow Dag에서는 Complete로 나오는 것이였습니다.
그래서 Glue Crawler Task가 EMR step이 끝나기도 전에 실행되어버렸습니다.
EMR Step이 끝나기를 기다리는 Task가 필요했는데, EMRStepSensor가 딱이였습니다.
from airflow.providers.amazon.aws.sensors.emr_step import EMRStepSensor
step_sensor = EMRStepSensor(
task_id='step_sensor_task',
job_flow_id=cluster_id,
step_id=step_id,
aws_conn_id='aws_default', # Specify the Airflow connection ID containing your AWS credentials
region_name=region_name,
dag=dag
)
# EMR을 띄워서 그 안에 있는 config중에 'KeepJobFlowAliveWhenNoSteps': True,가 있는데 False로 하게되는 경우
# EMR을 생성하고 Step을 제출하고 끝나게되면 종료시키는 옵션이 있다. 해당 config을 조정하지 않는다면
# EMRStepSensor를 사용한다고 EMR이 terminate될리는 없다.5. Glue Crawler
파라미터 값으로 glue crawler 이름을 받아 GlueCrawlerOperator를 통해 Task를 구성했습니다.
from airflow.providers.amazon.aws.operators.glue_crawler import GlueCrawlerOperator
crawler_task = GlueCrawlerOperator(
task_id='run_crawler_task',
crawler_name={parameter5},
aws_conn_id='aws_default', # Specify the Airflow connection ID containing your AWS credentials
region_name=region_name,
dag=dag
)6. Slack에 상세 결과 전송
Slack에 상세 결과 전송 받는 방법에 대해서는 아래의 포스트를 참고 해주시기 바랍니다.
https://spidyweb.tistory.com/509
[Airflow] Airflow DAGs 이상감지, 알림받기, 결과전송 (EmailOperator, Slack)
이번 포스트에는 Airflow DAGs이 success 및 failed 또는 Task중에 보내고 싶은 결과가 있는 경우 전송하는 방법에 대해 정리해보겠습니다. 방법으로는 EmailOperator와 Slack을 사용하는 방법으로 크게 2가지
spidyweb.tistory.com
7. ETL 처리 상태 반영
ETL작업 이후에는 DB에 상태 UPDATE를 쳐야 하는 작업이 있는데, 해당 작업을 PythonOperator + Cursor를 이용한 UPDATE문을 구성하여 하나의 Task로 구성 하였습니다.
8. Email 보내기
Email에 알림받기는 아래의 포스트를 참고 해주시기 바랍니다.
https://spidyweb.tistory.com/509
[Airflow] Airflow DAGs 이상감지, 알림받기, 결과전송 (EmailOperator, Slack)
이번 포스트에는 Airflow DAGs이 success 및 failed 또는 Task중에 보내고 싶은 결과가 있는 경우 전송하는 방법에 대해 정리해보겠습니다. 방법으로는 EmailOperator와 Slack을 사용하는 방법으로 크게 2가지
spidyweb.tistory.com




댓글