NCP 서비스 중 MongoDB cluster를 생성해보면서, cluster를 구성할 수 있는 방법들을 정리 해봤습니다.
1. MongoDB Cluster Type 비교
| 클러스터 타입 | 이중화 구성 | 서버 생성 수(대) | 구성 |
| Stand-alone | X | 1 | Standalone |
| Single Replica Set | O | 3~7 | Primary, Secondary, Arbiter |
| Sharding | O | Mongos : 2~5 Config : 3 Shard: 2개 이상(최대 5개) Shard(Replica Set)당 Member: 3~7 Shard(Replica Set)당 Arbiter: 0~1 |
Mongos, Primary, Secondary, Arbiter |
2. Single replica set vs sharding
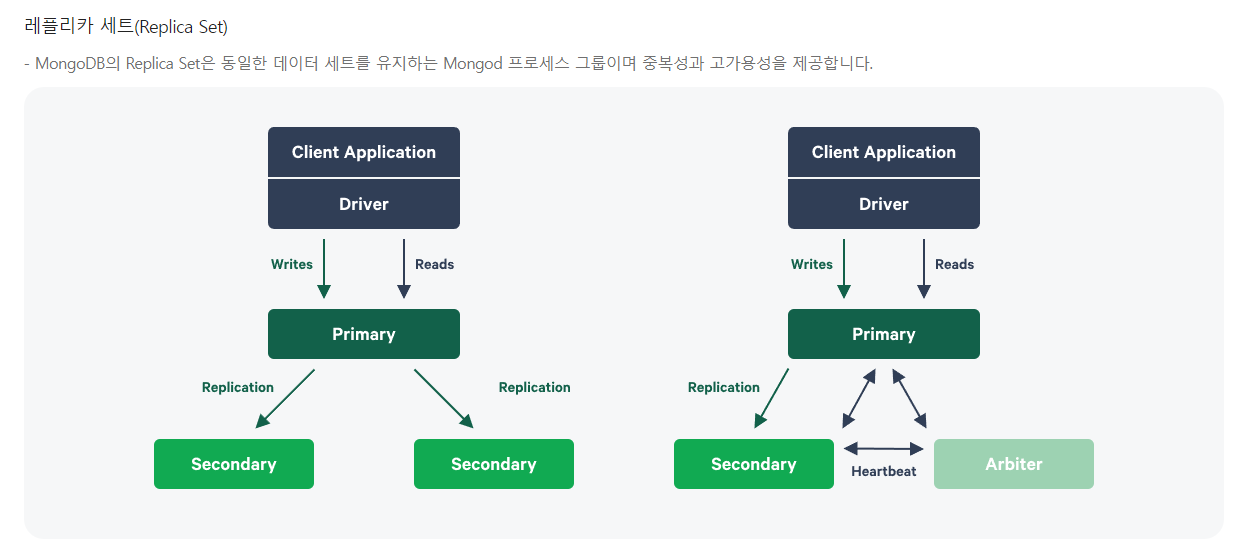
Single Replica Set에서는 클라이언트가 직접 DB 서버에 접근하여 데이터 read/write를 수행하지만, Sharding에서 클라이언트는 mongos라고 불리는 Router 서버에 접근하고 필요한 데이터 read/write 작업은 mongos를 통해 수행된 후 클라이언트에게 전달됩니다. Sharding에서는 n개의 Shard를 구성하며, 각각의 Shard는 Single Replica Set과 동일한 구성
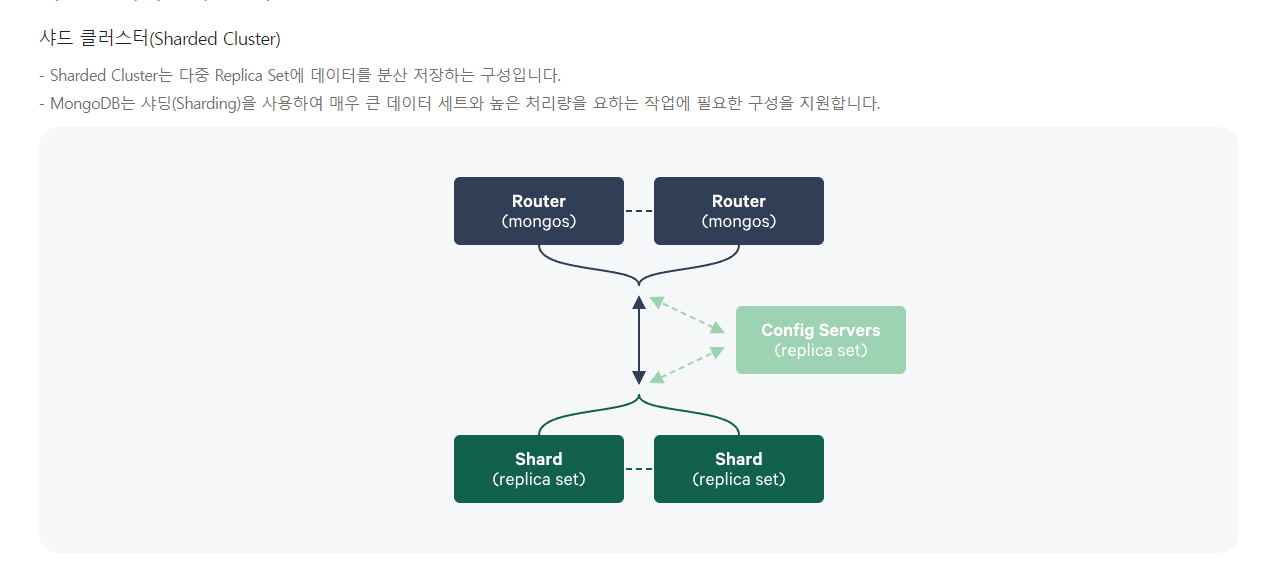
생성 되는 서버 수
| Mongos | config-server | arbiter | member | total | |
| Single-Replica Set | x | x | x | pss(3대) | 3대 |
| Sharding | 2(2~3 선택가능) | 3(default) | x | pss(3대) x shard 수 | 11대 |
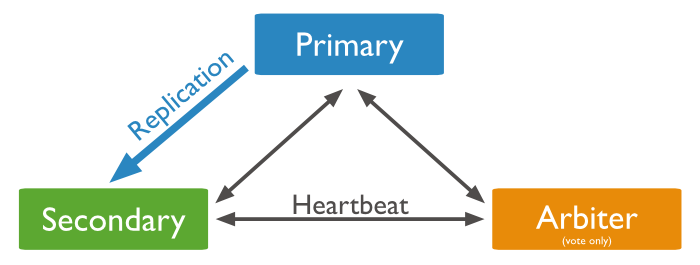
PSS(Primary secondary secondary) Primary 서버가 죽은 경우 secondary중에서 primary로 격상되는데, ReplicaSet에 의해 투표를 하게되어 secondary 노드 중에서 격상될 서버가 지정되는 방식
3. 클러스터를 구성하는 서버 종류
- arbiter 서버: mongod로써의 데이터 저장 기능을 가지지 않지만, 마스터 서버 장애 시에 마스터 서버 선출을 위한 투표권을 행사할 수 있는 서버,마스터 서버의 장애 발생 이외에는 arbiter는 DB서버로의 행위를 수행하지 않음
- mongos(router) 서버: 어플리케이션으로부터 쿼리를 받아서 각 샤드로 쿼리를 보내주는 역할, 라우터 역할을 하는 서버

- Config Server: sharding cluster에 존재하는 별도의 서버로, 각 Shard 별 데이터 분산 메타 데이터가 저장되는 서버
(샤딩이 활성화된 데이터베이스와 컬렉션의 정보만 관리)
(샤딩이 되지 않은 객체들은 컨피그 서버가 아니라 각 샤드서버가 로컬로 관리)
Mongos(라우터 서버)는 요청된 일을 분배하여 이동시키는 일을 하기 때문에 데이터를 찾는 일 까지는 하지 못한다. 한다고 하면 아마 속도가 느려질 것이다. 그래서 Config Server에 메타데이터(데이터를 찾기 위해 어디로 가야하는지의 정보(목차))를 저장하여 요청하는것
4. 성능
- 샤드: 대량의 데이터를 처리하기 위해 여러 개의 DBMS에 분할하는 기술로, DBMS 안에서 데이터를 나누는 것이 아니라 DBMS 밖에서 데이터를 나누는 방식
데이터를 여러 서버에 분산해서 저장하고 처리할 수 있는 기술, horizontal partitioning
→ 데이터를 분산 저장함으로써 각 서버의 처리량을 균형 있게 분산, 쿼리 성능 향상
- shard(replica set) → DB server (분산 처리)
- shard 내의 replica set(pss) 구조에 의해 primary가 다운 되어도 shard가 가지고 있던 collection의 document 정보는 유지 됨 (고가용성)
- mongos → shard를 통신하게 해주는 router
- Config servers → shard가 동기화 될 수 있도록 메타 데이터와 설정들 저장
즉, 물리적으로 분할 된 컬렉션에 데이터를 수평 파티셔닝으로 분할하여 하나의 컬렉션처럼 보이게 함
→ 동일한 컬렉션을 가지고 분산 처리가 가능하게 됨
샤드 클러스터 쿼리 수행 절차
- 사용자 쿼리가 참조하는 컬렉션의 청크(파티션된 데이터 조각) 메타 정보를 컨피그 서버로부터 가져와서 라우터의 메모리에 캐시한다.
- 사용자 쿼리의 조건에서 샤딩 키 조건을 찾는다.
- 쿼리 조건에 샤딩 키가 있으면 해당 샤딩 키가 포함된 청크 정보를 라우터의 캐시에서 검색하여 해당 샤드 서버로만 사용자 쿼리를 요청한다. 샤딩 키 조건에 포함된 청크가 여러 샤드에 분산되있다면 대상이 되는 여러 샤드에 쿼리를 요청한다.
- 쿼리 조건에 샤딩 키가 없으면 모든 샤드로 쿼리 요청한다.
- 쿼리를 전송한 대상 샤드 서버로부터 쿼리 결과가 도착하면 결과를 병합하여 사용자에게 쿼리 결과로 커서를 반환한다.
어느 정도 성능이 필요할 때 샤드를 쓰면 되는가?
타겟 쿼리가 필요로 할 때, INSERT,UPDATE,DELETE 쿼리 모두에서 가능
<타겟 쿼리>
문서의 필드 값(샤딩의 기준 필드)을 기준으로 쿼리를 보낼 샤드를 결정
db.coll.find({date:"2015-01-01"}}) 처럼 샤딩 기준 필드가 조건으로 걸려있을 때 적용
→ 특정 샤딩 기준 필드를 기준으로 쿼리가 필요할 때 샤드를 씀
<브로드캐스트 쿼리>
샤드 클러스터 몽고디비에서 샤드 키를 쿼리 조건으로 가지지 않은 경우에는 라우터가 작업 범위를 특정 샤드로 줄일 수 없다. 그래서 이런 경우 라우터는 사용자의 쿼리를 모든 샤드로 요청하고 각 샤드로부터 온 결과를 병합해 사용자에게 반환 → full scan개념
'DataBase > NoSQL' 카테고리의 다른 글
| [NoSQL] Docker로 EC2에 MongoDB 설치해서 NoSQL booster for mongodb에 연결하기 (0) | 2024.02.25 |
|---|---|
| [NoSQL] MongoDB 집계(Aggregation)1 (0) | 2021.01.21 |
| [NoSQL] MongoDB 쿼리 언어 총정리2 (0) | 2021.01.20 |
| [NoSQL] MongoDB 쿼리 언어 총정리1 (1) | 2021.01.20 |
| [NoSQL] MongoDB Index 생성,예제,효율확인 (0) | 2021.01.19 |


댓글