면접을 보러다니면서 뭐를 더 학습 해야될지 알게 돼서, 목표가 있어서 다행이라는 생각이 듭니다.
Great Expectation 들어 본 적 있는데, 막상 적용해보거나 실무에서 얘기가 나온적이 없어서 제대로 학습해보지 못했었습니다.
이번 기회에 관련해서 간단히 정리해보고, 비슷한 제품이 있는지 확인 후에 비교해보겠습니다.
1. 데이터 정합성이란? 그리고 왜 필요한지?
데이터가 일관성 있고, 정확하며, 신뢰할 수 있는 상태로 유지되는 것을 의미. 다시 말해, 데이터가 의도한 대로 잘 구성되어 있고, 오류 없이 유지되는지
2021.01.08 - [DataBase] - [DataBase] 무결성(Integrity)과 정합성(Consistency)
[DataBase] 무결성(Integrity)과 정합성(Consistency)
#데이터 무결성(Data Integrity) : 데이터 값이 정확한 상태 #데이터 정합성 : 어떤 데이터들이 값이 서로 일치함. - 중복 데이터를 많이 사용하면 데이터끼리 정합성을 맞추기 어렵다. - 비정규형을
spidyweb.tistory.com
정보계에서는 운영계(OLTP)의 데이터를 삭제, 변경사항까지 반영하여 그대로 가져와서 데이터를 분석해야 올바른 통계와 수치를 보고하고 반영할 수 있습니다.
따라서 정보계 데이터가 운영계와 정합성이 맞는지를 확인하는 것도 중요합니다.
운영계의 변경사항을 반영하기 위해 CDC를 도입하는 것도 같은 이유입니다.
아래의 툴들은 운영계와 정보계의 정합성을 확인하는 tool의 예시입니다.
- Talend Data Quality
- Talend ETL과 통합된 품질 검증 도구
- 데이터 클렌징, 중복 탐지, 정합성 검사 가능
- informatica Data Validation
- Informatica 기반 환경에서 사용
- GUI 기반 데이터 비교, 매핑 테스트 포함
- Apache griffin
- 배치/실시간 데이터 정합성 검사를 지원하는 오픈소스 데이터 품질 플랫폼 (Spark 기반)
- 실시간 + 배치 정합성 검사 모두 지원
- 운영계 vs 정보계 정합성 비교 시 주로 사용
- AWS Deequ
- Spark 기반의 데이터 품질 검사 라이브러리로, 데이터 검사를 코드로 작성하고 자동화 가능
- Amazon에서 개발한 오픈소스
- "단위 테스트처럼" 데이터 품질 규칙을 코드로 정의
- GreatExpectations
- 데이터가 기대하는 규칙(expectations)을 만족하는지 자동으로 검사하고 리포트하는 프레임워크
- 주로 ETL/ELT 파이프라인에 통합되어, 정합성 / 품질 / 규칙 위반 여부를 검사
- SQL, Pandas, Spark, Snowflake 등 다양한 백엔드와 호환
2. GreatExpectations
Python을 기반으로 한 Data Quality Open Source Framework. 다양한 데이터 소스를 사용 할 수 있으며 (S3, FileSystem, RDBMS 등) Pandas, Spark 등의 API를 이용할 수도 있음
1) 핵심 기능
- Data Validation: Expectation을 생성 하여, 특정 데이터 Batch 단위에 대해 원하는 결과가 반환 되는지 검증 (ex. null 여부, unique 여부, 문자열 길이, 값의 범위 등)
- Data Profiling: Data의 각 Column에 대한 통계 등을 반환 (ex. 최대값, 최솟값, 중간값 등)
- Data Docs: Data Validation, Data Profiling에 대한 결과를 HTML Document로 반환
2) 핵심 개념
- Data Context: Great Expectations Project를 실행 하기 위한 메타 데이터 정보들이 포함
- Data Sources: Great Expectations Project와 실제 데이터를 연결 해 주는 컴포넌트
- Checkpoints: Checkpoint는 Great Expectations에서 데이터를 검증하는 추상적인 계층
2-1) Data Context
- Data Context는 Great Expectations (이하 GX) Project의 파일 접근 등에 필요한 메타 데이터와 설정 값 등을 보유
- GX Project Python API의 Entrypoint 역할을 수행 하며, 대부분의 작업이 Data Context의 메타 데이터를 이용하여 수행
- Data Context에는, 추후 설명할 Data Docs의 접근에 필요 한 정보들과 Stores의 접근에 필요 한 정보들을 지정해 줄 수 있음

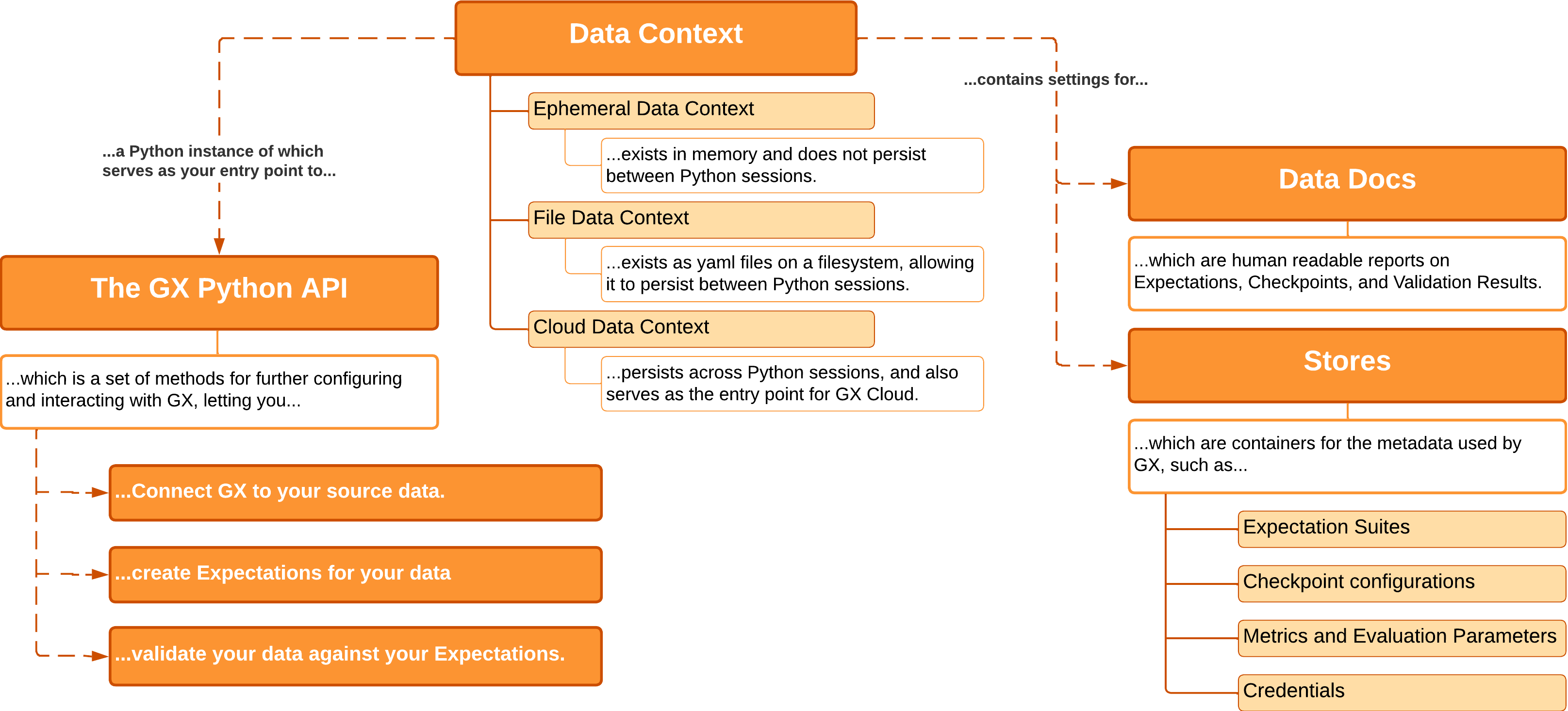
3가지 종류의 Data Context
- Ephemeral Data Context: In-Memory 내에 존재하는 Data Context
GX Context를 실행하는 Python Session 외에서는 존재 하지 않음 - File Data Context: File 형태로 Configuration을 설정 하는 방식
GX Context를 실행하는 Python Session 간 해당 설정을 공유 가능, 큰 프로젝트를 관리 한다면 권장 하는 형식 - Cloud Data Context: GX Cloud를 사용 할 때만 해당, GX Cloud에 Context를 저장하는 형태
Stores
Data Context는 각 Core Concepts에서 필요한 저장 공간에 대한 정보들도 지정 가능하며, 아래에 저장 가능
- Local File System
- Amazon S3
Store의 종류
- Expectation Store: 데이터 검증을 담당하는 Expectation 정보를 저장
- Validation Store: 데이터 검증 결과를 저장
- Checkpoint Store: Checkpoint의 메타 데이터를 저장
- Data Docs Store: Data Docs를 저장
- Metric Store: Anomaly Detection을 위해 사용 되며, 계산 완료 된 Metric (e.g. 열의 평균, 레코드 수)를 저장 한 후, 데이터의 추이를 분석 하는데 사용
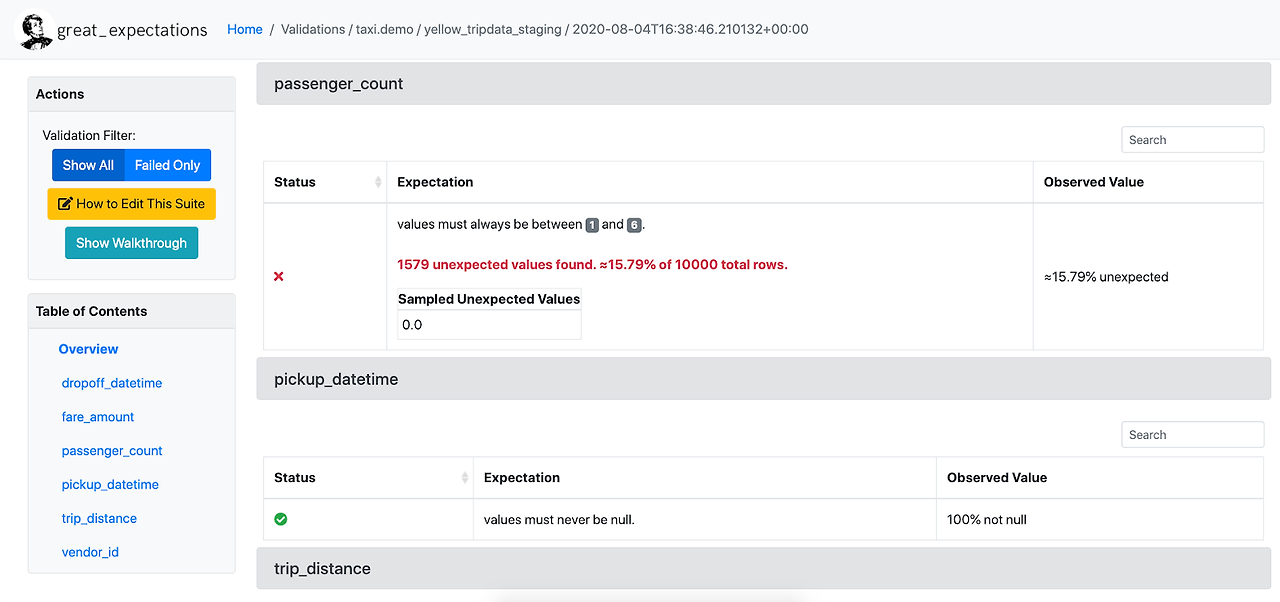
Data Docs
Data Docs를 이용하여 Great Expectations Application으로 생성 된 데이터 (Data Validation, Data Profiling 결과 등)를 HTML 문서로 확인 (원하는 File System에 호스팅 하여 사용 가능)
2-2) Data Sources
Data Sources는 Great Expectations와 실제 데이터 (Local file, S3, HDFS, RDBMS 등)를 연결 해 주는 Component

- Data Asset(s)
- Data Asset은 Data Sources 내의 Data Record의 추상적인 모음 입니다. Data Asset > Batch > Batch Request로 Hierarchy가 설정
- Batch(es)
- Batch는 Data Asset의 고유한 부분 집합. 예를 들면 특정 테이블을 Data Asset이라고 가정 하였을 때, month, day, hour 등의 partition으로 나누어진 데이터가 Batch라고 볼 수 있습니다.
- Batch Requests
- Great Expectations Application에서 한 개 이상의 Batch 데이터를 가져올 수 있음.
- Batch 객체를 가져와, Batch Requests로 파티션 별 데이터를 추출 하여, 이를 추후 Expectations Suite에서 사용, 검증 로직을 수행 하는 방식으로 사용 할 수 있음
2-3) Expectations
- Expectations는 데이터를 검증하는 컴포넌트.
- 입력 되는 데이터에 대해 (Batch) 검증을 수행
- Expectation Suites
- Expectation Suites는 Expectation의 집합
- Great Expectations에서는 Expectation Suites에 있는 Expectation들을 바탕으로, Data Verification을 수행
- Data Assistants
- Data Assistant는 Batch Data를 분석 하여 Expectation Suites를 빠르게 생성 할 수 있도록 돕는 도구
- Use Case는 Automatic Constraints Suggestion등
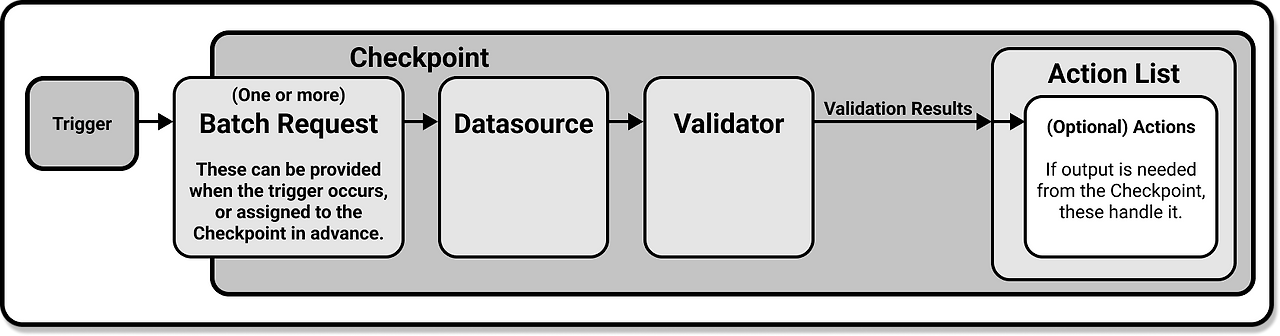
2-4) Checkpoint
- Checkpoint는 Great Expectations에서 데이터를 검증하는 수단
- Data Batch와 Expectation Suites를 묶은 추상 계층
- Validation Results
- Checkpoint를 통해 수행한 Validation 결과
- Data Context를 통해 Data Docs로 Export 가능
- Actions
- Validation Result에 따라서, 사용자가 설정한 Action을 수행 할 수 있음
- Email Notification, Slack Notification 등을 수행 할 수 있음
3) 예시 코드
spark와 결합한 GE
from pyspark.sql import SparkSession
import great_expectations as ge
# 1. SparkSession 생성
spark = SparkSession.builder \
.appName("GreatExpectationsSparkExample") \
.getOrCreate()
# 2. 샘플 Spark DataFrame 생성
data = [
("Alice", 25),
("Bob", 30),
("Charlie", None), # 일부러 null 포함
]
df = spark.createDataFrame(data, ["name", "age"])
# 3. GE가 인식할 수 있도록 Spark DataFrame을 래핑
df_ge = ge.dataset.SparkDFDataset(df)
# 4. Expectation 정의 및 실행
df_ge.expect_column_values_to_not_be_null("name")
df_ge.expect_column_values_to_be_between("age", min_value=20, max_value=35)
# 5. Validation 결과 확인
results = df_ge.validate()
print(results)
# (선택) 실패한 expectation이 있다면 로그 출력
if not results["success"]:
for r in results["results"]:
if not r["success"]:
print("❌ Failed Expectation:", r["expectation_config"]["expectation_type"])
예시 결과
{
"success": false,
"results": [
{
"expectation_config": {
"expectation_type": "expect_column_values_to_not_be_null",
...
},
"success": true
},
{
"expectation_config": {
"expectation_type": "expect_column_values_to_be_between",
...
},
"success": false # age에 None이 있어서 실패
}
]
}3. 비슷한 tool은 뭐가 있을까? 비교
| 항목 | Apache Griffin | GreatExpectations | AWS Deequ |
| 제작/개발 주체 | Apache Software Foundation | Superconductive (오픈소스 커뮤니티 중심) | Amazon (AWS Labs) |
| 기반 언어 | Java / Scala | Python | Scala (PyDeequ로 Python도 가능) |
| 엔진 연동 | Apache Spark | Pandas, Spark, SQLAlchemy 등 다양한 백엔드 지원 | Apache Spark |
| UI 제공 여부 | ✅ 제공 (Web Dashboard) | ✅ (HTML 리포트로 출력, 대시보드는 간단한 수준) | ❌ 없음 (코드 기반 결과 확인) |
| 주요 사용 환경 | 대규모 데이터 품질 관리, 운영계 vs 정보계 비교 | 다양한 데이터 파이프라인 (ETL, 테스트 자동화 등) | AWS 환경 (Glue, EMR), 코드 기반 품질 검사 |
| 데이터 검증 방식 | 소스-타겟 정합성 검사 중심 (accuracy) | 단일 소스 품질 검사 중심 (expectations) | 단일 소스 품질 검사 (constraints) |
| 실시간 스트리밍 지원 | ✅ 가능 (실시간 룰 엔진 존재) | ❌ 비동기 or 배치 기반 | ❌ 스트리밍 지원 없음 |
| 정합성 비교 기능 | ✅ 소스 vs 타겟 정확도 검증 (ex: 운영계 ↔ 정보계) | ⚠️ 간접 가능 (Spark로 읽어서 비교는 가능) | ⚠️ 간접 가능 (Spark 기반 비교 로직 작성 필요) |
| 프로파일링 기능 | ✅ 기본 제공 (통계 기반 구조 분석) | ✅ 상세한 데이터 프로파일링 지원 | ✅ 자동 프로파일링 가능 |
| 결과 저장 및 리포팅 | DB/파일 저장 + 웹 리포트 | HTML/JSON 등 저장 가능 | MetricsRepository에 저장 (커스텀 필요) |
| 학습 곡선 | 높음 (설정 및 운영 복잡) | 중간 (Python 친화적, 문서 풍부) | 중간~높음 (Scala/Python 숙련 필요) |
| 운영 환경 적합도 | 엔터프라이즈 (복잡한 품질 통제용) | 데이터 사이언스, ML/ETL 개발 파이프라인 중심 | AWS/Spark 중심의 코드 기반 품질 검사 자동화 |
참조:
https://justkode.kr/data-engineering/great-expectations/
https://www.youtube.com/watch?v=F3yvXqzkDhU&list=PLYDwWPRvXB8_XOcrGlYLtmFEZywOMnGSS
'BigData' 카테고리의 다른 글
| [BigData] 파일 포멧과 압축 포멧 선택 기준 정리 (parquet, Avro, gzip,snappy,ZSTD) (0) | 2025.05.05 |
|---|---|
| [BigData] Parquet vs ORC vs Avro 빅데이터 파일 포멧 비교 정리 (0) | 2025.01.08 |
| [BigData] 헷갈릴 만한 용어 정리 HDFS 노드, EMR cluster 노드, Spark Application (process) 정리 (0) | 2021.08.19 |
| [Hadoop] HDFS에 데이터 저장하기(뉴욕택시 데이터,green taxi data) (4) | 2021.07.04 |


댓글