728x90
이번 포스트에는 LakeHouse Table Format 중 하나인 Apache Iceberg에 대해서 정리해보겠습니다.
1. LakeHouse Table Format이란?
데이터 레이크(Data Lake)의 유연함과 데이터 웨어하우스(Data Warehouse)의 구조화된 관리 기능을 결합하기 위해 고안된 테이블 기반의 저장 포맷
1) 기존 구조의 문제
| 시스템 | 장점 | 단점 |
| Data Lake | 저렴한 저장, 유연한 포맷(csv/parquet) | ACID 없음, 원본과 분석용 데이터의 정합성 문제 발생 |
| Data Warehouse | 구조적 쿼리, ACID 보장, 높은 품질 | 비싸고, 폐쇄적, 실시간 ingest 어려움 |
- 위의 시스템 2개를 하나로 통합 한 것이 Lakehouse 아키텍처
- Data lake로 방대한 양의 데이터를 저장하고 glue catalog같은 것으로 테이블을 만든다 할 수는 있지만, 실시간으로 스키마가 변경된다거나, 데이터가 update, delete되는 경우 분석 테이블에 그 변경분과 삭제분이 반영이 되지 않습니다.
- 기존의 data lake개념은 append만 되고 파일의 특정 row에 대한 직접 수정이나 삭제를 할 수는 없기 때문에, 실시간으로 분석이 필요한 경우에 그 변경분과 삭제분을 LakeHouse table format으로 snapshot version으로써 관리합니다. 즉, 변경,삭제분에 대해 반영된 파일을 append하여 새로운 버전으로써 만들어 버리는 것.
- 결국 원본 데이터가 자주 바뀌며, 그것을 분석데이터에 반영을 해야 될 떄 사용하는 테이블 포멧입니다. 실제로 변경이나 삭제에 대한 감지는 debezium이나 flink같은 CDC를 통해 하게 되며, 감지된 부분을 테이블에 반영하는 것이 Lakehouse table format입니다.
2. Iceberg란?
대규모 데이터 레이크를 위한 Lakehouse 테이블 포맷
- 기존의 Hive 테이블 포맷(예: Hive 메타스토어 + HDFS 기반 테이블)에서 발생하는 문제를 개선하기 위해 설계됨
- 데이터 파티셔닝, 스키마 진화, 트랜잭션 관리, ACID 보장을 지원하는 현대적인 테이블 포맷
3. 왜 Iceberg를 사용하는지?
- 대규모 데이터셋에 적합한 성능과 확장성
- 테이블 메타데이터를 계층적으로 관리해 수십만~수백만 개 파일도 빠르게 탐색 가능
- 기존 Hive 테이블에서 발생하는 느린 메타데이터 스캔 문제 해결
- 스키마 진화 및 파티션 진화 지원
- 컬럼 추가, 삭제, 이름 변경 등 스키마 변경을 안전하게 수행 가능
- 파티션 필드도 변경 가능 (기존 Hive는 불가능)
- ACID 트랜잭션 지원
- 데이터 읽기/쓰기 시 일관성 보장
- 복수 클라이언트 동시 쓰기 지원
- RDBMS의 Update, Delete와 같은 작업을 반영할 수 있음
- 시간 여행 (Time Travel) 기능
- 과거 특정 시점 테이블 데이터 조회 가능
- 실수로 삭제한 데이터 복구 가능
- 효율적인 스캔과 푸시다운 필터
- 메타데이터 기반의 데이터 파일 필터링으로 불필요한 데이터 읽기 최소화
- 다양한 처리 엔진 지원
- Apache Spark, Flink, Trino, Presto 등 여러 엔진과 호환됨
4. Iceberg 내부 구조
1) 테이블 위치 (Table Location)
- Iceberg 테이블은 객체 스토리지(S3, HDFS, GCS 등)의 디렉터리(폴더) 형태로 존재합니다.
- 이 디렉터리에 여러 메타데이터와 데이터 파일이 저장됩니다.
2) 주요 메타데이터 파일 및 구성
2-1. 메타스토어(Metadata Store)
- Iceberg는 Hive 메타스토어 같은 별도 메타데이터 저장소 없이도 자체 메타데이터 파일을 관리.
- 메타데이터는 테이블 디렉터리 내 파일로 저장되어 관리됨.
2-2. Table Metadata (테이블 메타데이터 JSON 파일)
- Iceberg 테이블의 가장 중요한 파일.
- 테이블 스키마, 파티션 스키마, 현재 활성 스냅샷, 스냅샷 목록, 데이터 파일 목록, 프로퍼티 등이 JSON 형식으로 저장됨.
- 메타데이터 파일은 테이블 디렉터리에 metadata/ 하위에 저장됨.
- 메타데이터 파일은 immutable하며, 테이블 상태 변경 시 새로운 파일 생성 후 최신 메타데이터로 참조됨.
2-3. 스냅샷 파일 (Snapshot Files)
- 스냅샷은 테이블의 특정 시점 상태를 나타내는 메타데이터 객체.
- 각 스냅샷은 자신이 포함하는 데이터 파일 리스트와 관련 메타데이터를 가리킴.
- 스냅샷 파일도 JSON 포맷이며, 메타데이터 JSON 안에서 참조됨.
- 시간여행(time travel), rollback 등에 사용됨.
2-4. 스냅샷 로그 (Snapshot Log Files)
- 스냅샷 변경 이력을 기록하는 파일.
- 주로 최근 스냅샷 상태를 빠르게 조회하는 데 활용.
2-5. Manifest Lists
- 스냅샷 당 여러 manifest list 파일이 존재.
- Manifest list는 여러 개의 manifest 파일 경로를 포함하는 JSON 리스트.
- Manifest 리스트는 스냅샷이 가리키는 전체 데이터 파일 집합을 조직화함.
2-6. Manifest Files
- 실제 데이터 파일의 상세 정보를 담고 있는 JSON 파일.
- 데이터 파일 경로, 파티션 값, 행 수, 컬럼별 통계(최소/최대값, null 수) 등이 포함됨.
- 이 정보는 쿼리 시 불필요한 데이터 파일 스캔 방지 및 빠른 필터링에 도움.
3) 데이터 파일 (Data Files)
- Parquet, Avro, ORC 등 컬럼 기반 저장 포맷 사용 가능.
- 실제 테이블의 데이터가 저장되어 있음.
- Manifest 파일이 이 데이터 파일들의 위치와 메타정보를 관리.

주요 파일들의 관계도, 구조
Table Location/
│
├── metadata/
│ ├── v1.json (current table metadata file)
│ ├── snap-xxxx.json (snapshot files)
│ ├── manifest-list-xxxx.json (manifest lists)
│ └── manifest-xxxx.json (manifest files)
│
├── data/ (또는 다른 위치에 있을 수 있는 데이터 파일들)
│ ├── part-xxxx.parquet
│ └── ...5. Iceberg 성능 튜닝
- 메타데이터 컴팩션(Metadata Compaction)
- 메타데이터 파일이 너무 많아지면 스캔 속도가 떨어짐
- 주기적으로 메타데이터 파일을 병합해 관리 효율 개선
- 데이터 파일 크기 최적화
- 너무 작은 데이터 파일이 많으면 읽기 작업이 비효율적
- 파일 크기를 적절히 조절해 IO 비용 감소 (예: 1GB 내외 권장)
- 스냅샷 관리 (스냅샷 청소)
- 오래된 스냅샷 제거하여 메타데이터 파일 수 감소 및 디스크 공간 절약
- 불필요한 스냅샷을 주기적으로 삭제
- 파티셔닝 전략 최적화
- 적절한 파티션 필드를 선정하여 쿼리 필터링 효율 증대
- 과도한 파티셔닝은 메타데이터 부하 증가로 오히려 역효과 발생 가능
- 병렬 작업 최적화
- Spark 같은 처리 엔진과 결합 시, 병렬도 조절 및 적절한 캐싱 활용
- 쿼리 최적화
- 컬럼 프루닝(Column Pruning), 필터 푸시다운을 적극 활용
- 쿼리 시 불필요한 컬럼이나 파티션 제외
- 클러스터 및 인프라 최적화
- 객체 스토리지(S3, HDFS 등)의 IO 특성 파악 후 적절한 네트워크 및 클러스터 설정
6. AWS에서 Iceberg 테이블 생성해보기
flink와 같은 프레임워크로 iceberg 테이블을 생성하는 것이 맞는 방법이지만, 수동으로도 테이블을 생성할 수 있고 관련해서 간단하게 확인해보겠습니다.
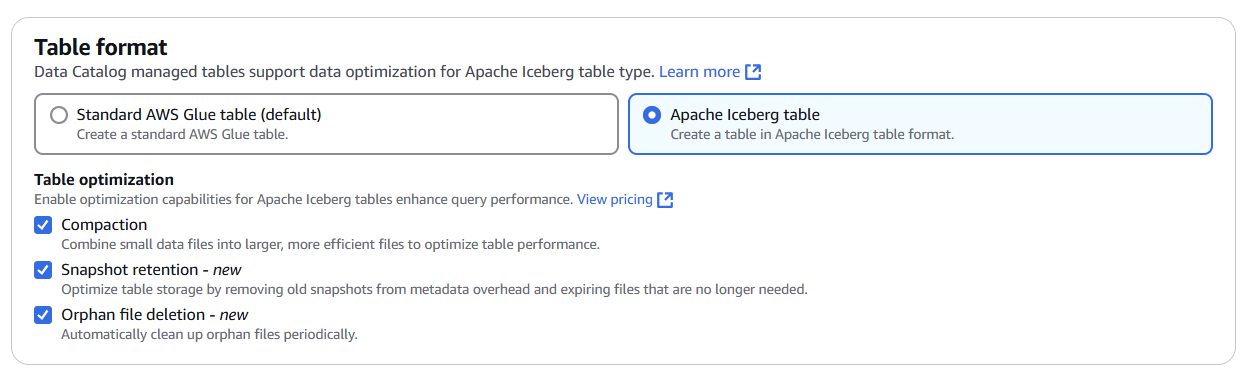
AWS Glue Table format에서 Apahce Iceberg table을 선택해서 생성할 수 있습니다.
Table의 최적화를 위해 3개 옵션을 지원합니다.
- compaction: 작은 파일을 합쳐서 큰 파일로 생성하는 옵션
- snapshot retention: 오래된 snaption을 제거하는 옵션
- orphan file deletion: Iceberg 테이블의 현재 메타데이터(즉, 최신 스냅샷)에서 참조하지 않는 데이터 파일이나 메타데이터 파일을 삭제하는 옵션

최적화와 관련된 configuration을 기본값을 사용할 수도 있고, 커스텀 셋팅을 사용할 수도 있습니다.

테이블 로케이션을 정하는 건 glue table과 마찬가지로 external table이기 때문에 동일하게 설정되어야 합니다.
컬럼정의를 하는 스키마까지 완성하게 되면 iceberg테이블을 사용할 수 있게 됩니다.
728x90
댓글