이번 포스트에는 Spark를 설치해 보겠습니다.
vritualbox 설치,ubuntu설치, ssh통신, hadoop 설치가 완료 되지 않으신 분은 아래의 URL을 참고하여 완료해 주세요.
1.virtualbox 설치 및 ubuntu 설치
spidyweb.tistory.com/212?category=842040
[Hadoop] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 1.virtualbox에 ubuntu 설치하기
1.virtual box를 다운로드한다. www.virtualbox.org/wiki/Downloads Downloads – Oracle VM VirtualBox Download VirtualBox Here you will find links to VirtualBox binaries and its source code. VirtualBox..
spidyweb.tistory.com
2.power shell과 ssh통신
[Hadoop] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 2.ubuntu terminal과 SSH 통신
1.ubuntu에 openssh-server 설치 2.ssh 시작하기 3.포트포워딩 설정하기 virtualbox 설정 - 네트워크 - 포트포워딩 + 클릭 - ubuntu를 만들게되면 보통 ip가 10.0.2.15로 할당됩니다. 여기서 중요한건 게스트ip..
spidyweb.tistory.com
3.hadoop 설치
[Hadoop] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 3.ubuntu 에 hadoop(하둡) 다운로드,설치
이번 포스트에는 virtualbox에 하둡을 설치하겠습니다. virtualbox에 ubuntu를 설치하지 못하신 분이나, windows의 powershell로 ssh통신을 할 줄 모르시는 분이면 아래URL의 포
4.hive 설치
https://spidyweb.tistory.com/215
[Hadoop] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 4.ubuntu 에 Hive(하이브) 다운로드,설치
이번 포스트에는 Hive를 설치해 보겠습니다. vritualbox 설치,ubuntu설치, ssh통신, hadoop 설치가 완료 되지 않으신 분은 아래의 URL을 참고하여 완료해 주세요. 1.virtualbox 설치 및 ubuntu 설치 spidyweb.tist..
spidyweb.tistory.com
1.Spark 설치에 필요한 package 다운로드하기
-jdk
-scala
1)sudo apt install default-jdk scala git -y
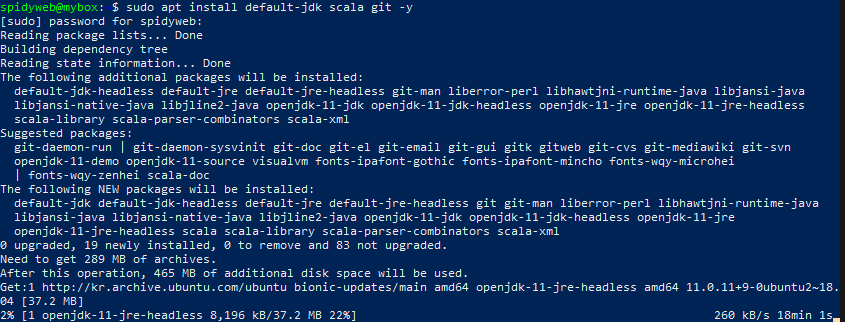
2)java -version; javac -version; scala -version;
-java, java컴파일러, scala 버전을 확인합니다.
2. Spark 다운로드 및 환경설정 하기
(hdoop 계정으로 실습합니다.)
아래의 버전은 매번 버젼이 바뀌므로 https://downloads.apache.org/spark/
Index of /spark
downloads.apache.org
에서 참고하여 맞는 버전으로 설치하시면 됩니다.
1) wget https://downloads.apache.org/spark/spark-3.0.2/spark-3.0.2-bin-hadoop2.7.tgz

-wget을 통해 스파크 3.0.1 하둡 2.7tgz파일을 다운 받습니다.
2) tar xvf spark-*
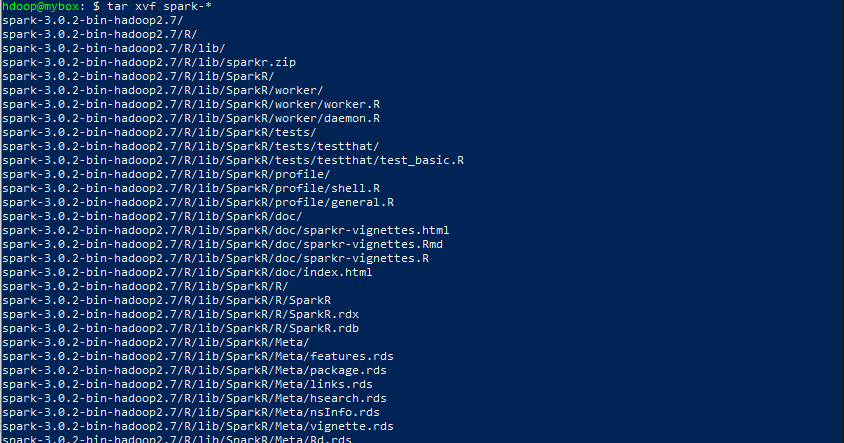
-tgz파일을 압축해제 해줍니다.
3) sudo mv spark-3.0.2-bin-hadoop2.7 /opt/spark

-압축해제한 폴더를 /opt/spark 디렉토리로 이동시켜줍니다.
3.스파크 환경 구성하기
1) nano .profile
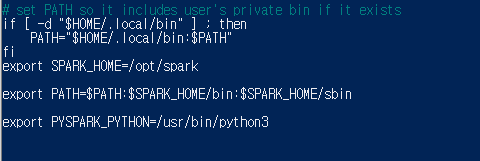
.profile 파일에 아래의 설정을 넣고 저장해줍니다.
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3
2) source ~/.profile
-/profile 파일 적용시켜주기
*.profile 파일이란? .bashrc 와의 차이점은??
아래의 링크에 정리
https://spidyweb.tistory.com/221
4.스파크 stand alone master server 실행 시켜보기
1) start-master.sh

ubuntu 브라우저를 통해 http://127.0.0.1:8080/ 로 접속해 Spark web user interface를 확인합니다.
(http://localhost:8080/ 로도 접속 가능합니다 127.0.0.1이 곧 localhost 즉 자신의 ip입니다.)
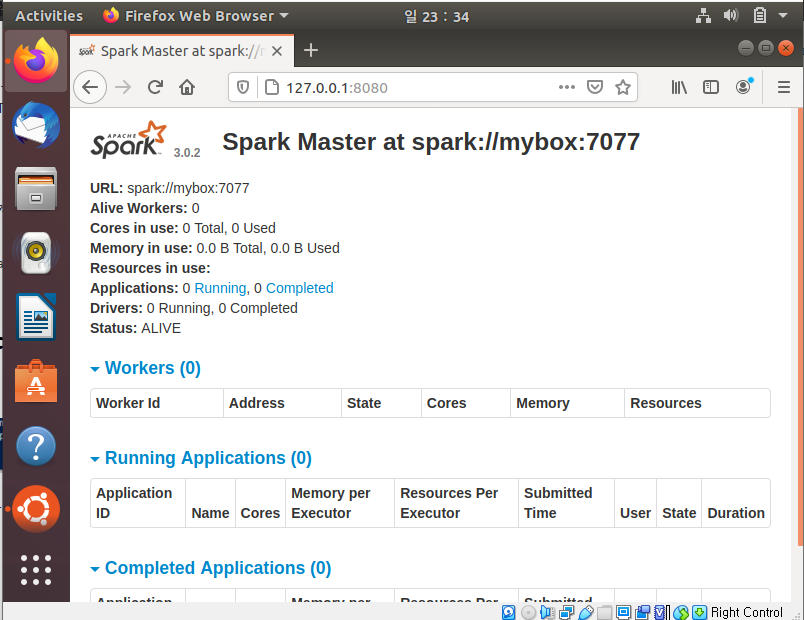
master를 중지시키려면 stop-master.sh
5.스파크 Slave-server 실행해보기(worker process)
1)start-slave.sh spark://master:port
저같은 경우엔 start-slave.sh spark://mybox:7077 로 실행시켰습니다.


worker process가 뜬 것을 알 수 있습니다.
slave 를 중지시키려면 stop-slave.sh
2) start-slave.sh -m 512M spark://master:port
마찬가지로 저같은 경우엔 start-slave.sh -m 512M spark://mybox:7077로 실행시켰습니다.

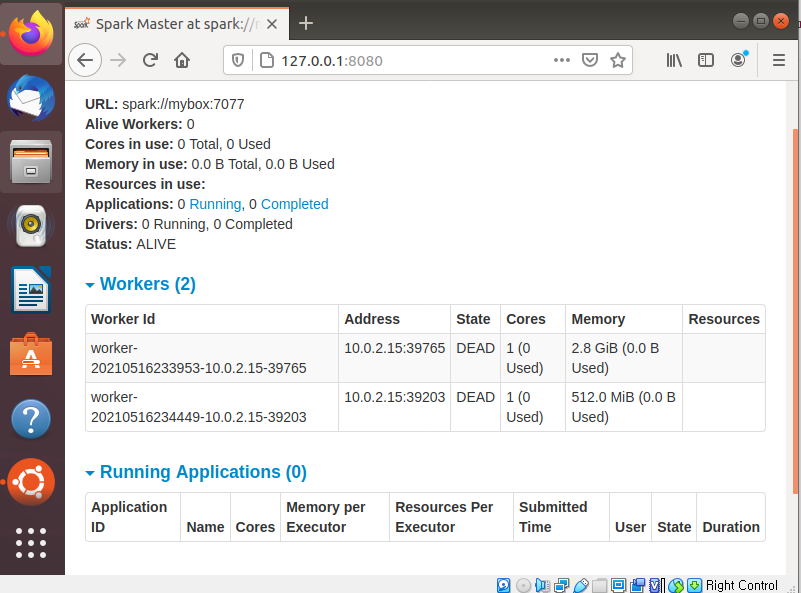
*start-all.sh
*stop-all.sh 로 각각 master, slave를 둘다 실행시키고 둘다 중지시킬 수 있습니다.
6.spark shell(scala) pyspark TEST
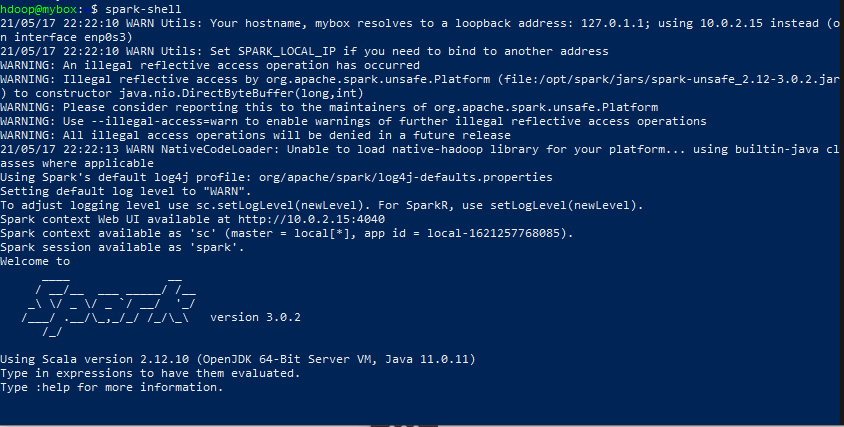
1) spark-shell
-scala로 spark shell을 실행시킵니다.
spark shell환경에서 나오는건 :q enter
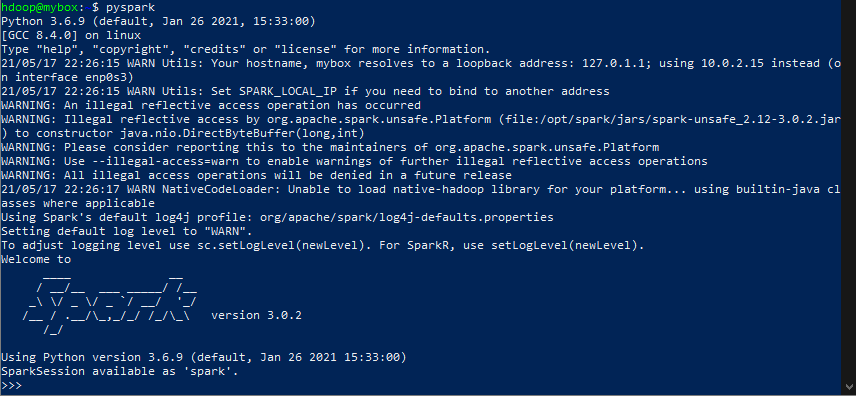
2) pyspark
-pyspark 환경으로 접속합니다.
pyspark 환경에서 나오는건 quit() enter


댓글