이번 포스트에는 EMR-6.2.0 버전을 Hadoop, Hive, Zookeeper, livy,Spark JupyterHub와 JupyterEnterpirseGateway를 포함하여 띄우겠습니다.
1. Software Configuration
- HA 구성을 하시려면 use multiple mastger nodes 란에 check합니다(이번 포스트에는 HA구성 없음)
- AWS Glue Data Catalog Setting에는 Hive table과 Spark table의 metadata를 Glue로 대신하여서 연동할 것인지에 대해 물어보는 옵션인데, Glue에 작업해 둔 것이 있어서 체크.(없으신 분들은 체크 해제)
- JupyterEnterpriseGateway는 EMR과 연동할 Notebook에 필요
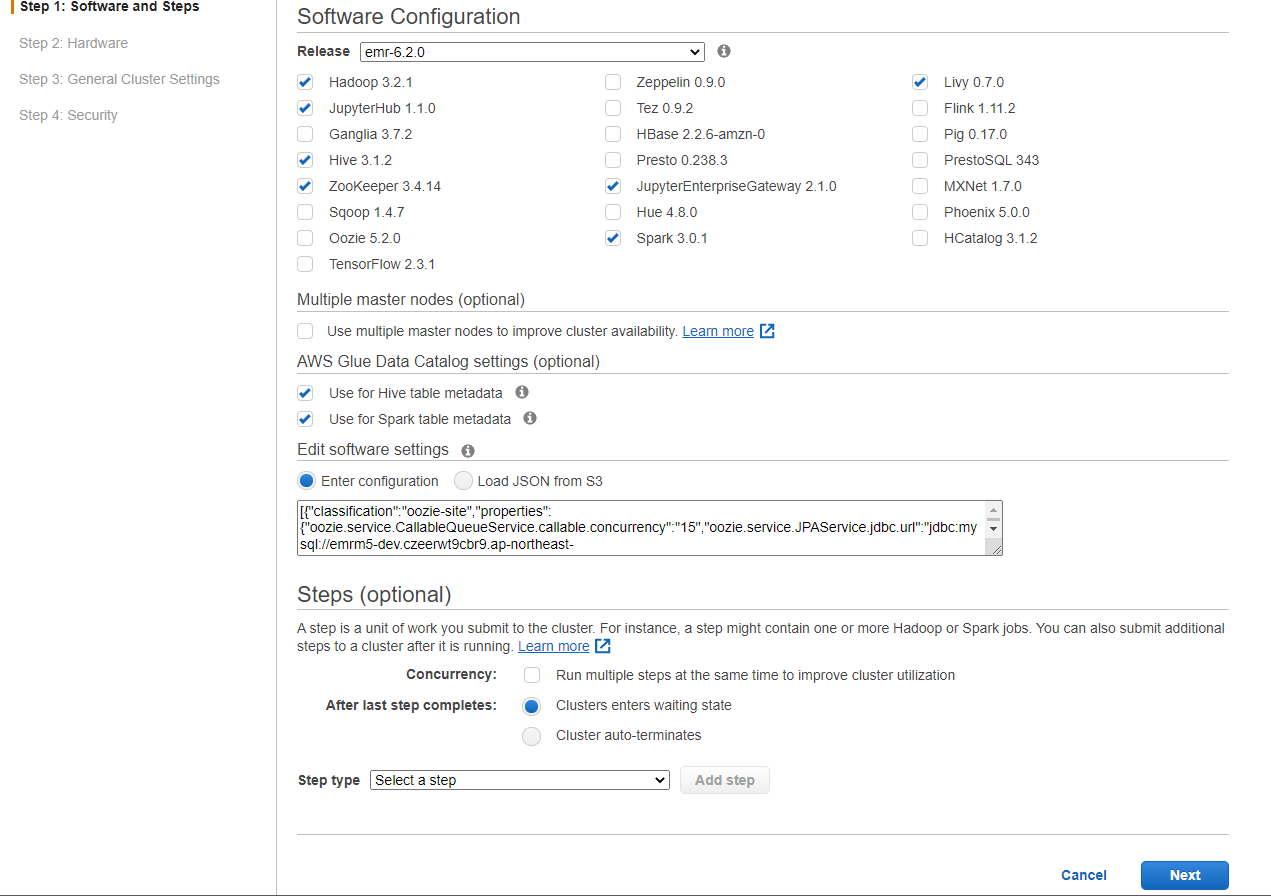
- edit software settings- 소프트웨어의 config, properties를 지정하는 란
enter configuration 체크
[{"classification":"spark-defaults","properties":{"spark.executor.memory":"10g","spark.driver.memory":"10g","spark.master":"yarn","spark.driver.cores":"4","spark.executor.cores":"4","spark.submit.deployMode":"cluster","spark.dynamicAllocation.maxExecutors":"15","spark.sql.shuffle.partitions":"400","spark.serializer":"org.apache.spark.serializer.KryoSerializer","spark.dynamicAllocation.minExecutors":"0","spark.dynamicAllocation.initialExecutors":"6","spark.dynamicAllocation.enabled":"True","spark.dynamicAllocation.executorAllocationRatio":"1"}}]
2. Hardware 구성
- cluster composition- Uniform instance groups 로 지정
- Networking- 미리 구성된 network(VPC)와 EC2 subnet을 설정

- subnet구성 시 체크할 점
(subnets configure에서 Auto-assign public IPv4 address yes인지 체크)
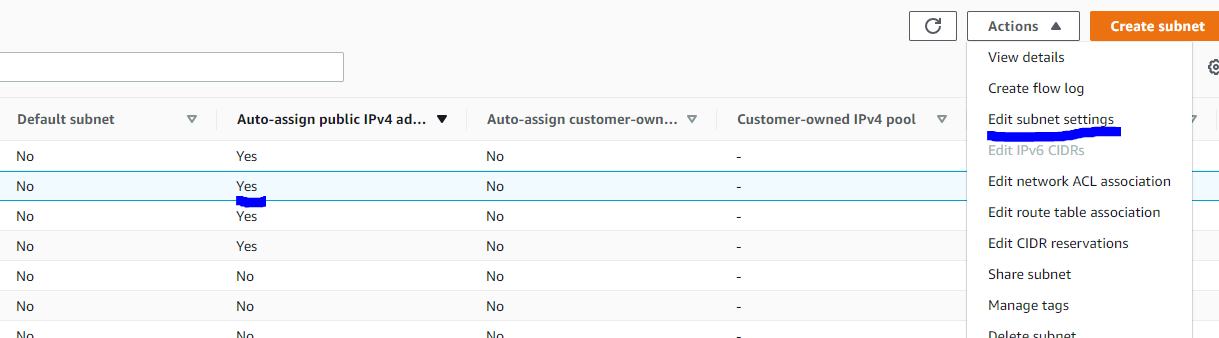
public ipv4 address No 일시 yes로 바꾸는 법

vcp setting - vpc dns hostnames 나오게 기능 체크

router Routes 추가

router subnet pubic subnet을 향하게 설정(edit subnet associations)
internet gateways 설정한 vpc로향하게

- master와 core노드는 on-demand로써 구입 함으로써 구성
- task node는 spot정책을 통해 구입 함으로써 구성

- Cluster scaling - 클러스터를 자동으로 scale in,out 하는 옵션
- Auto-termination - cluster의 활동이 잠잠해지면 자동으로 끌 수 있는 옵션
- EBS Root Volume - root device의 기본 용량(EBS) 설정

3. general cluster settings
- log 위치, log 보안, 디버깅, 예기치못한 클러스터 종료 예방 체크하기(체크해제되어야 클러스터를 내릴 수 있다)

4. Security
- ssh 접근 가능한 security group을 생성
- security options에 EC2 keypair를 생성하여 emr-master-ec2 .pem file을 잘 보관해둔다.(masternode(ec2 instance)에 접근하기 위함)
- EMR master노드, core & task node 각각 security group 을 설정
- EMR master노드에는 ssh로 접근이 가능한 security group 추가


Create cluster(약 15분)
5. cluster를 띄운 후 구성된 master node 의 public DNS로 ssh 접속
master node ssh로 연결
ssh -i ~/key위치/~.pem hadoop@public DNS
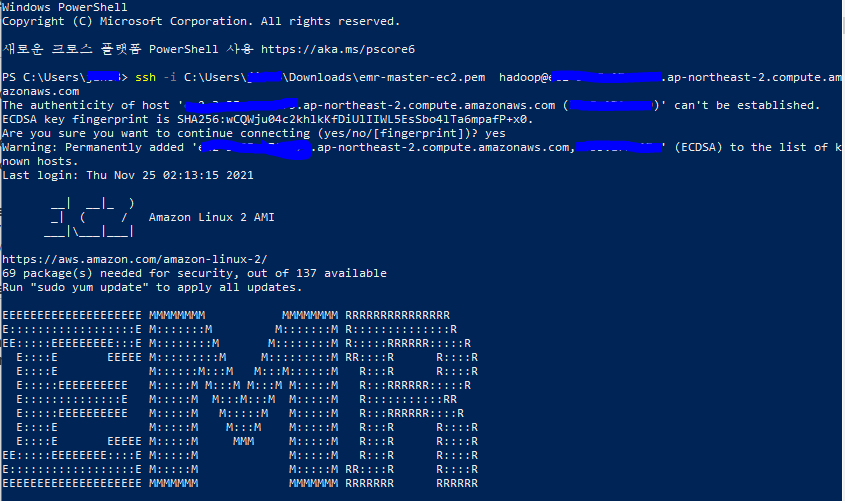
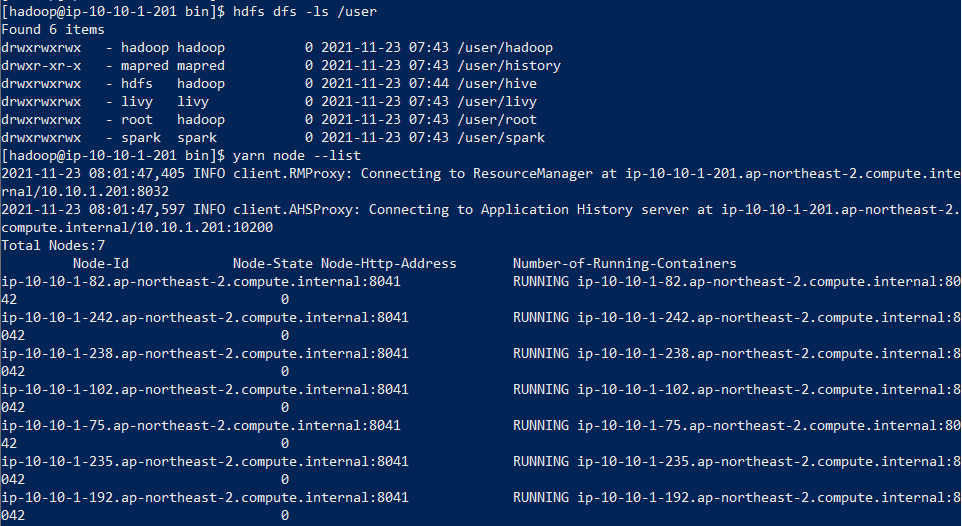
SSH tunneling
ssh -i pem키 위치\~~.pem -N -L [호스트pc에서 입력할 포트]:[master node의 public DNS]:[마스터 노드 내 접근할 프로세스의 포트번호] hadoop@[master node의 public DNS]


ISSUE
hue를 포함해서 띄우려하면 boot strap action error (EMR version때문인 것으로 추정)
[24/Nov/2021 21:28:17 -0800] spark_shell ERROR Spark is not enabled
Traceback (most recent call last):
File "/usr/lib/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py", line 39, in <module>
from spark.conf import LIVY_SERVER_SESSION_KIND
ImportError: No module named spark.conf
[24/Nov/2021 21:28:17 -0800] query_api ERROR Some application are not enabled: No module named impala.server
Traceback (most recent call last):
File "/usr/lib/hue/apps/jobbrowser/src/jobbrowser/apis/query_api.py", line 39, in <module>
from impala.server import get_api as get_impalad_api, _get_impala_server_url
ImportError: No module named impala.server
'Cloud > AWS Cloud Computing' 카테고리의 다른 글
| [AWS] ec2 instance stop vs terminate 인스턴스 중지와 종료의 차이 (0) | 2022.02.11 |
|---|---|
| [AWS] EC2 의 vCPU, vCore, core당 스레드(논리 프로세서), yarn에서 vcore할당 비교 (0) | 2021.12.10 |
| [AWS] EC2 instance type 정리 (0) | 2021.11.22 |
| [AWS] AWS 환경셋팅 & 리눅스 인스턴스 접속 (0) | 2021.03.16 |
| [AWS] EC2(Elastic Compute cloud)란? EC2만드는 방법 (0) | 2021.02.07 |


댓글