EMR Serverless가 client mode로 설정되어 있는 것을 보면서 왜 client 모드 일까? cluster모드는 안되는 걸까? 라는 의문점을 가졌었고, 막상 두 개의 차이점을 설명하려 해봐도 명확히는 설명을 할 수 없어서 이번 기회에 비교하여 정해보겠습니다.
Spark Driver
비교해보기에 앞서 driver 개념이 두 개를 비교할 때 필요 하므로, Spark Driver부터 간단하게 짚고 넘어가겠습니다.
- 프로그램의 main()메소드가 실행되는 프로세스
- Spark Context, Spark Session을 생성하고 RDD를 만들고 Transformation, action 등을 실행하는 사용자 코드를 실행
- DF, DS, UDF를 생성하고 애플리케이션 정보 유지 관리를 담당
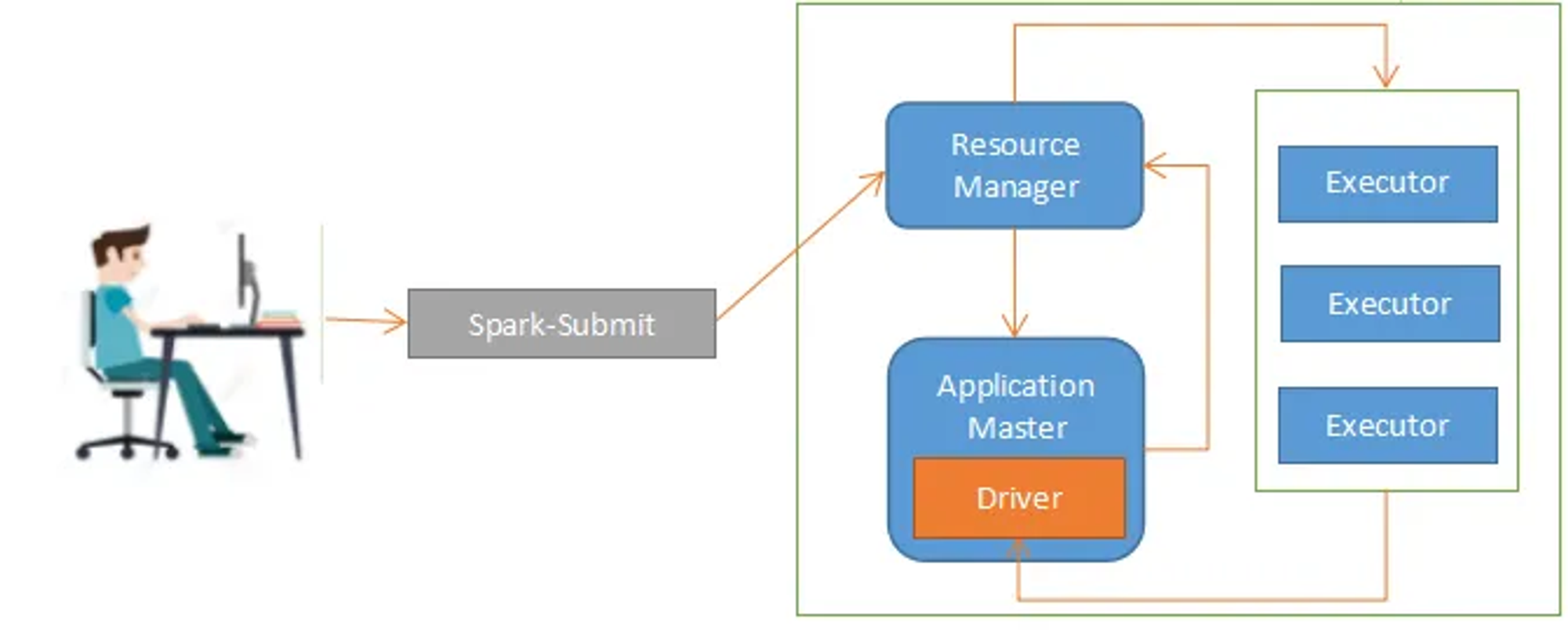
Cluster Mode
- 드라이버 프로세스가 Cluster 내의 Application Master 에서 실행되는 모드
- driver가 YARN 컨테이너에서 동작하기 때문에 driver에 장애가 발생할 경우 다른 노드에서 driver가 재실행
- 주로 Production 환경에 적합
Client Mode
- EMR에서의 default deploy mode임
- 드라이버 프로세스가 Cluster 와 관련 없는 다른 외부 서버(ex, 내 방 데탑)에서 실행되는 모드
- 주로 개발과정에서 대화형 디버깅을 할 때 사용(스파크 쉘) 따로 지정하지 않으면 기본으로 선택되는 모드임
- Spark Driver 프로세스가 failed된 경우 재시도 하지 않음, client가 YARN과의 연결이 끊긴경우 job이 killed 됨

비교표
| Cluster mode | Client mode | |
| 드라이버가 실행 되는 곳 | Application Master | client |
| 자원 요청 주체 | Application master | Application master |
| executor 프로세스 실행 주체 | YARN ResourceMaster and NodeManager | YARN ResourceMaster and NodeManager |
| spark shell 지원 여부 | No | Yes |
Spark on EMR Serverless
- client mode가 default인 이유는? → 원래 EMR은 client mode가 default다
- cluster mode로 실행하는 방법이 있는가? → 없다.
AWS 엔지니어 분께서 달아준 답변
Hello To answer your question: per my understanding there is no way to change the deploy mode from 'client' in EMR Serverless. The reason is that there isn't really a difference between the two modes on EMR Serverless. In a regular EMR cluster, there is a master node from the end user's point of view, but on EMR Serverless there is no real 'master node'. To explain what I mean, let me put it this way: Consider the example of running a Spark job on EMR on EC2 cluster by running the 'spark-submit' command as a step (which is practically identical to running this directly on the master node). In this scenario, the deploy mode of the Spark job has a direct impact on how the job will run since we have an awareness of the underlying architecture of the cluster as well as the daemons running on each specific node. Using 'client-mode' will cause the Spark driver container to run on the master node, as such resources on this node (Memory and CPU) will be used by this container. If enough jobs are running in client mode, this can cause the Master Node to move resources away from crucial daemons such as the YARN ResourceManager and HDFS DataNode daemons to run the Spark driver containers which in turn can cause cluster issues (eg: YARN ResourceManager restart). For this reason it is considered a better practice to run these jobs in cluster mode (in most cases). Comparing this with EMR Serverless, there is no 'master' node. Everything is abstracted away and from the end user point of view each node can be considered to be identical. As such, where the driver runs makes no difference because we don't need to take into account other daemons like we did in EMR on EC2 and the job will run the same with either configuration. Please let me know if this explanation helps or if you have any further questions.
안녕하세요. 질문에 답하려면 EMR serverless에서는 배포 모드를 'client'에서 변경할 방법이 없는 것으로 알고 있습니다. 그 이유는 EMR serverless에서 두 모드 사이에 실제로 차이가 없기 때문입니다. 일반 EMR 클러스터에는 최종 사용자의 관점에서 마스터 노드가 있지만 EMR 서버less에는 실제 '마스터 노드'가 없습니다. 제가 의미하는 바를 설명하기 위해 'spark-submit' 명령을 실행하여 EC2 클러스터에서 EMR에서 스파크 작업을 실행하는 예를 한 단계(마스터 노드에서 직접 실행하는 것과 실질적으로 동일함)로 생각해 보겠습니다. 이 시나리오에서는 각 특정 노드에서 실행되는 데몬뿐만 아니라 클러스터의 기본 아키텍처를 알고 있으므로 스파크 작업의 배포 모드가 작업을 실행하는 방식에 직접적인 영향을 미칩니다. '클라이언트 모드'를 사용하면 마스터 노드에서 스파크 드라이버 컨테이너가 실행되므로 이 컨테이너에서 이 노드(메모리 및 CPU)의 리소스가 사용됩니다. 클라이언트 모드에서 실행 중인 작업이 충분히 있는 경우 마스터 노드가 중요한 데몬(예: YARN 리소스 매니저 재시작)에서 리소스를 이동하여 스파크 드라이버 컨테이너를 실행할 수 있습니다. 이러한 이유로 이러한 작업을 클러스터 모드에서 실행하는 것이 더 나은 방법으로 간주됩니다(대부분의 경우). EMR serverless와 비교하면 '마스터' 노드는 없습니다. 모든 것이 추상화되어 최종 사용자의 관점에서 각 노드는 동일한 것으로 간주될 수 있습니다. 따라서 EC2에서 EMR에서 실행한 것과 같은 다른 데몬을 고려할 필요가 없고 작업이 두 구성 중 하나로도 동일하게 실행되기 때문에 드라이버가 실행되는 위치에 차이가 없습니다. 이 설명이 도움이 되거나 추가 질문이 있으면 알려주십시오.
'BigData > Spark & Spark Tuning' 카테고리의 다른 글
| [Spark Tuning] Spark Memory 와 JVM (0) | 2023.10.17 |
|---|---|
| [Spark] cache() vs persist() 차이점 정리 (feat. storage level) (0) | 2023.09.19 |
| [Spark] EMR Serverless + Airflow로 spark job 제출해보기 (EmrServerlessStartJobOperator, boto3 + PythonOperator) (0) | 2023.08.27 |
| [Spark Tuning] Spark 3.x 버전 특징 정리 (0) | 2023.08.10 |
| [Spark] spark dataframe -> RDB로 적재하기 (2) | 2023.07.10 |




댓글