728x90
spark memory를 정리하기 전에 JVM을 알아야 합니다.
왜냐하면 spark는 Java 가상머신(JVM) 기반으로 동작하기 때문이고, 다른 언어(Python,R)로 작성한 spark code도 결국에는 Executor의 JVM에서 실행할 수 있는 Code로 알아서 변환하여 실행되기 때문입니다.
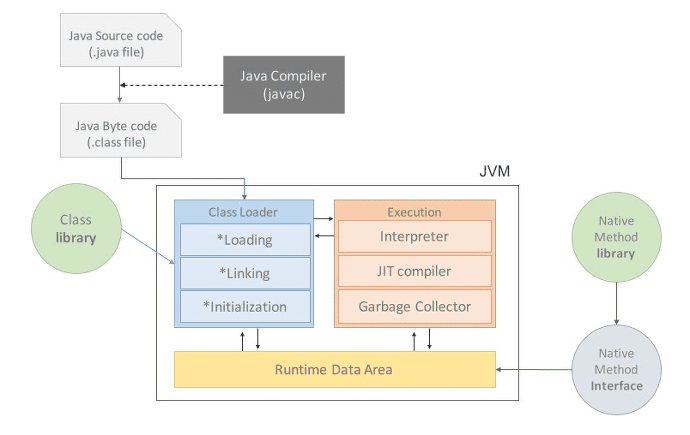
JVM(Java Virtual Machine)
자바를 실행하기 위한 가상 기계(컴퓨터)
* Java compiler는 JDK를 설치하면 bin 에 존재하는 javac.exe
1. runtime Data Area
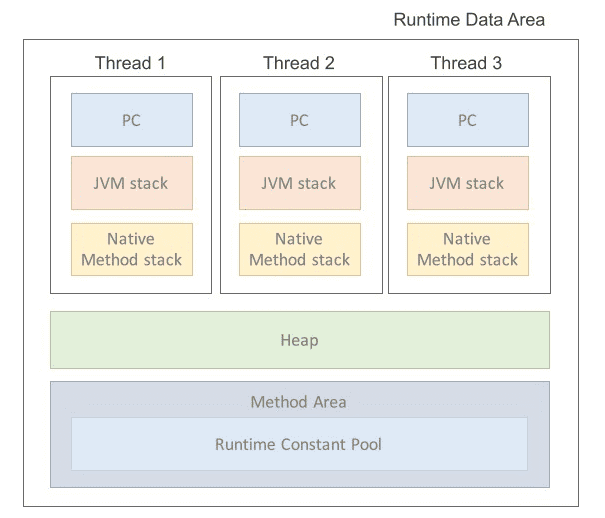
Runtime Data Area는 JVM이 프로그램을 수행하기 위해 OS로부터 별도로 할당받은 메모리 공간을 말한다. Runtime Data Area는 크게 5가지 영역으로 나눌 수 있습니다.
1) PC Register
- JVM의 PC Register는 CPU 내의 기억장치인 레지스터와 다르게 작동
- PC Register는 각 쓰레드 별로 하나씩 존재하며 현재 수행 중인 JVM Instruction의 주소를 가지게 된다. 즉, 스레드가 어떤 명령을 실행할지 기록하는 부분이라고 할 수 있음
2) JVM Stack
- 메소드(method)가 호출될 때 메서드와 메서드의 정보는 JVM Stack에 쌓이게 됨
- 즉, 메서드의 매개변수(parameter), 지역 변수(local variable), return 주소, 임시 변수 등의 정보를 기록하는 스택
- 각 스레드 별로 생성되기 때문에 다른 스레드는 접근할 수 없으며, 메서드 호출이 종료되면 스택에서 정보들이 제거됨
3) Native Method Stack
- 자바 외의 언어로 작성된 네이티브 코드들을 위한 스택
- Java Native Interface를 통해 호출되는 C/C++ 등의 코드를 수행
4) Method Area
- 모든 쓰레드가 공유하는 메모리 영역으로 클래스, 인터페이스, 메서드, 필드, Static 변수 등의 바이트 코드를 보관
- Method Area에는 Runtime Constant Pool이라는 별도의 관리 영역도 존재
- 이는 상수 자료형을 저장하고 참조하여 중복을 막는 역할을 수행
5) Heap
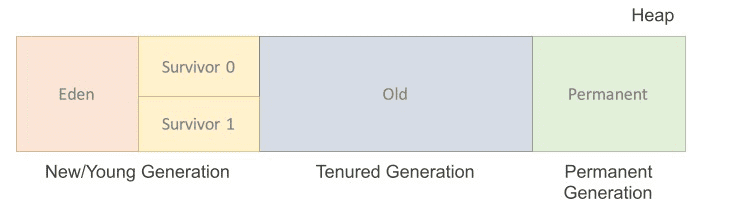
- Runtime 시점에 동적으로 할당하여 사용하는 영역
- 클래스를 이용해 인스턴스를 생성하면 Heap에 저장
- 즉, new연산자를 이용해 생성된 객체를 저장하는 영역
- Heap은 크게 New/Young 영역, Old 영역, Permanent Generation 3 영역으로 나뉘며, 참고로 java8 이후에는 Permanent 영역이 Metaspace 영역으로 바뀜
Spark Memory 관리
1. 종류
- Static Memory Manager (Static Memory Management) 정적
- Unified Memory Manager (Unified memory management) 통합
spark 1.6.0부터 통합 메모리 관리자가 Spark의 기본 메모리 관리자로 설정되었습니다.
정적 메모리 관리자는 유연성 부족으로 인해 더 이상 사용되지 않습니다.
두 메모리 관리자 모두에서 Java 힙의 일부는 Spark 애플리케이션 처리를 위해 위치하며 나머지 메모리는 Java 클래스 참조 및 메타데이터 사용을 위해 예약됩니다.
참고: JVM당 하나의 MemoryManager만 있습니다.
메모리에 대한 정보를 저장하기 위해 두 메모리 관리자는 두 개의 메모리 풀을 사용
- ExecutionMemoryPool
- StorageMemoryPool
1-1) Static Memory Manager (Static Memory Management) 정적 메모리 관리
메모리 관리를 위한 전통적인 모델이자 간단한 체계
참고: 정적 메모리 할당 방법은 Spark 3.0에서 제거되었습니다.
장점:
- Static Memory Manager 메커니즘은 구현하기 쉽습니다.
단점 :
- 저장 메모리에 여유 공간이 있어도 사용할 수 없으며 실행기 메모리가 가득 차서 디스크 유출이 있습니다. (반대의 경우도 마찬가지)
1-2) Unified Memory Manager (Unified memory management) 통합 메모리 관리
- 1.6.0 스파크 이상부터, 새로운 메모리 관리자는 스파크를 제공하는 정적 메모리 관리자를 대체 채용 Dynamic 메모리 할당
- Storage 및 Execution이 공유하는 통합 메모리 컨테이너로 메모리 영역을 할당
- Execution 메모리를 사용하지 않는 경우 Storage 메모리는 사용 가능한 모든 메모리를 획득할 수 있으며 그 반대의 경우도 마찬가지
- Storage 또는 Execution 메모리에 더 많은 공간이 필요한 경우, acquireMemory()라는 함수가 메모리 풀 중 하나를 확장하고 다른 메모리 풀을 축소
장점:
- Storage 메모리와 Execution 메모리 사이의 경계는 고정되어 있지 않으며 메모리 부족의 경우 경계가 이동 됩니다. 즉, 한 영역이 다른 영역에서 공간을 차용하여 확장
- 응용 프로그램에 캐시 및 전파가 없는 경우 불필요한 디스크 오버플로를 방지하기 위해 실행 시 모든 메모리를 사용
- 응용 프로그램에 캐시가 있는 경우 데이터 블록이 영향을 받지 않도록 최소 Storage 메모리를 예약
- 이 접근 방식은 메모리가 내부적으로 분할되는 방식에 대한 사용자 전문 지식 없이도 다양한 워크로드에 대해 즉시 사용 가능한 합리적인 성능을 제공
2. JVM의 두 가지 유형의 메모리
- On-Heap Memory Managment (In-Memory) : Object는 JVM heap에 할당되고 GC에 의해 바인딩
- Off-Heap Memory Managment (External-Memory) : Object는 직렬화에 의해 JVM 외부의 메모리에 할당되고 Application에 의해 관리되며 GC에 바인딩되지 않음
일반적으로 Object의 읽기 및 쓰기 속도는 ( On-Heap > Off-Heap > DISK) 순
2-1) 온힙 메모리 (On-Heap Memory)
- 기본적으로 Spark는 온힙 메모리만 사용합니다. 온힙 메모리의 크기 는 Spark 애플리케이션이 시작될 때 --executor -memory 또는 spark.executor.memory 매개변수에 의해 구성
- Executor 내에서 실행되는 동시 작업은 JVM의 힙 메모리를 공유
| 매개변수 | 설명 |
| spark.memory.fraction (기본값 0.75)-spark1.6이상 | 실행 및 저장에 사용되는 힙 공간의 비율입니다. 이 값이 낮을수록 유출 및 캐시된 데이터 제거가 더 자주 발생합니다. 이 구성의 목적은 내부 메타데이터, 사용자 데이터 구조 및 희소하고 비정상적으로 큰 레코드의 경우 부정확한 크기 추정을 위한 메모리를 따로 확보하는 것입니다. |
| spark.memory.storageFraction (기본값 0.5) | spark.memory.fraction 에 의해 따로 설정된 공간 내 저장 영역의 크기입니다 . 캐시된 데이터는 총 스토리지가 이 영역을 초과하는 경우에만 제거될 수 있습니다. |
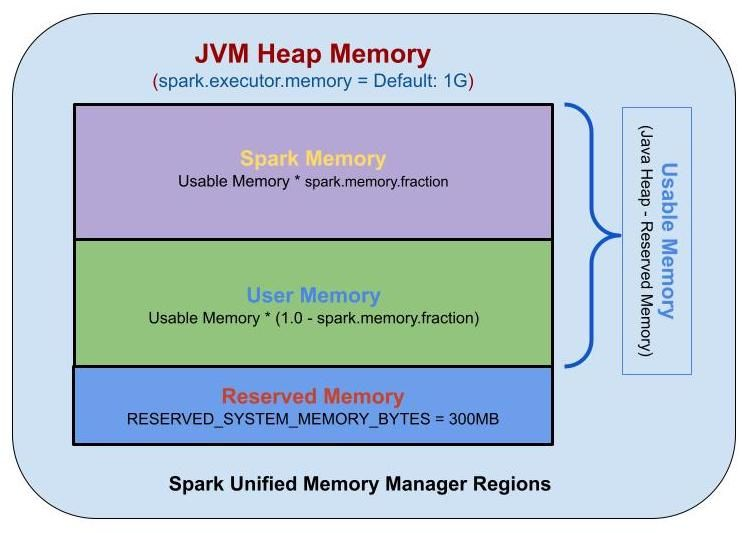
Reserved Memory
- 예약된 메모리는 시스템용으로 예약된 메모리이며 Spark의 내부 개체를 저장하는 데 사용됩니다.
- Spark v1.6.0+부터 값은 300MB입니다. 즉, 300MB의 RAM이 Spark 메모리 영역 크기 계산에 참여하지 않습니다
- executor memory < reserved memory *1.5 인경우 에러
21/06/21 03:55:51 ERROR repl.Main: Failed to initialize Spark session.
java.lang.IllegalArgumentException: Executor memory 314572800 must be at least 471859200. Please increase executor memory using the --executor-memory option or spark.executor.memory in Spark configuration.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:225)
at org.apache.spark.memory.UnifiedMemoryManager$.apply(UnifiedMemoryManager.scala:199)User Memory
- 사용자 메모리는 사용자 정의 데이터 구조, Spark 내부 메타데이터, 사용자가 생성한 모든 UDF, RDD 종속성 정보에 대한 정보 등 RDD 변환 작업에 필요한 데이터를 저장하는 데 사용되는 메모리
Spark Memory
- Apache Spark에서 관리하는 메모리 풀입니다. Spark 메모리는 조인과 같은 작업 실행을 수행하거나 브로드캐스트 변수를 저장하는 동안 중간 상태를 저장하는 역할
- 모든 캐시/지속 데이터는 이 세그먼트, 특히 이 세그먼트의 스토리지 메모리에 저장
- (Java Heap — Reserved Memory) * spark.memory.fraction
- Spark 작업은 두 가지 기본 메모리 영역에서 작동
- Execution – 셔플, 조인, 정렬 및 집계에 사용
- Storage – 데이터 파티션을 캐시하는 데 사용
Storage Memory
- Storage 메모리는 모든 캐시된 데이터, 브로드캐스트 변수 및 언롤 데이터 등을 저장하는 데 사용됩니다. "unroll"은 본질적으로 직렬화된 데이터를 역직렬화하는 프로세스입니다.
- MEMORY를 포함하는 모든 지속 옵션에 대해 Spark는 해당 데이터를 이 세그먼트에 저장합니다.
- Spark는 LRU(Least Recent Used) 메커니즘을 기반으로 오래된 캐시된 개체를 제거하여 새 캐시 요청을 위한 공간을 지웁니다.
- 캐시된 데이터가 Storage에서 나오면 디스크에 기록되거나 구성에 따라 다시 계산됩니다. 브로드캐스트 변수는 MEMORY_AND_DISK 영구 수준으로 캐시에 저장됩니다. 여기에 캐시된 데이터와 수명이 긴 데이터가 저장됩니다.
- (Java Heap — Reserved Memory) * spark.memory.fraction * spark.memory.storageFraction
Execution Memory
- Execution 메모리는 Spark 작업을 실행하는 동안 필요한 개체를 저장하는 데 사용됩니다.
- 예를 들어, 메모리의 Map 측에 셔플 중간 버퍼를 저장하는 데 사용됩니다. 또한 해시 집계 단계를 위한 해시 테이블을 저장하는 데 사용됩니다.
- 이 풀은 또한 사용 가능한 메모리가 충분하지 않은 경우 디스크 유출을 지원하지만 이 풀의 블록은 다른 스레드(작업)에 의해 강제로 제거될 수 없습니다.
- Execution 메모리는 Storage보다 수명이 짧은 경향이 있습니다. 각 작업 후 즉시 제거되어 다음 작업을 위한 공간을 만듭니다.
- (Java Heap — Reserved Memory) * spark.memory.fraction * (1.0 - spark.memory.storageFraction)
Spark 1.6+에서는 Execution 메모리와 Storage 메모리 사이에 엄격한 경계가 없습니다.
Execution 메모리의 특성으로 인해 이 풀에서 블록을 강제로 제거할 수 없습니다. 그렇지 않으면 참조하는 블록을 찾을 수 없기 때문에 실행이 중단됩니다.
그러나 Storage 메모리의 경우 필요에 따라 블록을 메모리에서 제거하고 디스크에 쓰거나 다시 계산할 수 있습니다(지속성 수준이 MEMORY_ONLY인 경우)
Execution 및 Storage 풀 차용 규칙:
- Storage 메모리는 블록이 실행 메모리에서 사용되지 않는 경우에만 Execution 메모리에서 공간을 빌릴 수 있습니다.
- Execution 메모리는 블록이 스토리지 메모리에서 사용되지 않는 경우 Storage 메모리에서 공간을 빌릴 수도 있습니다.
- Execution 메모리의 블록이 Storage 메모리에서 사용되고 실행에 더 많은 메모리가 필요한 경우 Storage 메모리가 차지하는 초과 블록을 강제로 축출할 수 있습니다.
- Storage 메모리의 블록이 Execution 메모리에서 사용되고 스토리지가 더 많은 메모리를 필요로 하는 경우 Execution 메모리가 차지하는 초과 블록을 강제로 축출할 수 없습니다. 그것은 더 적은 메모리 영역을 갖게 될 것입니다. Spark가 Execution 메모리에 저장된 초과 블록을 해제할 때까지 기다렸다가 이를 차지합니다.
728x90



댓글