저번 포스트까지는 하둡 클러스터를 구성해보았습니다.
이번 포스트에는 구성된 하둡 클러스터에 Hive를 설치해보겠습니다.
아직 hadoop cluster 구축이 안되신 분은 아래의 링크를 참고해주세요.
https://spidyweb.tistory.com/266
[BigData] Centos-7 fully distributed hadoop cluster 구성하기(하둡 클러스터) 1. 4개의 가상 노드 띄우기
이번 포스트에는 하둡 fully-distributed mode 구축을 해보도록 하겠습니다. 하둡 구성 스펙 호스트OS - windows10 home 게스트OS들 - centOS7 Hadoop - 3.1.0 Zookeeper - 3.4.10 jdk - 1.8.0_191 호스트OS는 공..
spidyweb.tistory.com
하둡 구성 스펙
호스트OS - windows10 home
게스트OS들 - centOS7
Hadoop - 3.1.2
Zookeeper - 3.4.10
jdk - 1.8.0_191
호스트OS는 공유기(WI-FI) 연결 환경
서버 4대를 활용한 하둡 HA 구성:
namenode1: 액티브 네임노드, 저널노드 역할
rmnode1: 스탠바이 네임노드, 리소스 매니저, 저널노드 역할, 데이터 노드 역할
datanode1: 저널노드 역할, 데이터 노드 역할
datanode2: 데이터 노드 역할
1. hive 다운받기 및 압축해제
datanode2에 hive를 설치하겠습니다.
hive는 Hadoop cluster의 맨위에 올라가는 형태입니다.
모든 노드에 설치 할 필요없이 하나의 노드(hive job을 던질 노드)에만 설치하면 됩니다.
1) wget 설치(datanode2)
- su root을통해 root계정으로 접속
- sudo yum install wget
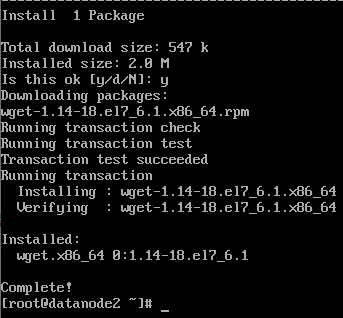
su hadoop
cd ~
로 hadoop계정의 다운받을 위치로 가줍니다.
2) hive 다운로드 및 압축해제
다운로드
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz

압축 해제
tar xzf apache-hive-3.1.2-bin.tar.gz

3) .bashrc 파일 설정
nano .bashrc
아래에 다음과 같이 추가
export HADOOP_HOME=/home/hadoop/hadoop-3.1.0
export HIVE_HOME=/home/hadoop/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin

bashrc파일 적용시켜주기
source ~/.bashrc
4. hive-config.sh 파일 설정
1) nano $HIVE_HOME/bin/hive-config.sh
2)
export HIVE_CONF_DIR=$HIVE_CONF_DIR
export HADOOP_HOME=/home/hdoop/hadoop-3.1.0
export HIVE_AUX_JARS_PATH=$HIVE_AUX_JARS_PATH

5. HDFS에 Hive directory 만들기
-HDFS layer에 데이터를 저장하기 위해 HIVE에 사용될 분리된 두 개의 디렉토리를 만듭니다.
(tmp와 warehouse 디렉토리)
-HDFS를 사용하므로 zookeeper(namenode1,rmnode1,datanode1만)와 hadoop을 먼저 실행시켜줍니다.
su zookeeper
cd ~
cd zookeeper-3.4.10
./bin/zkServer.sh start
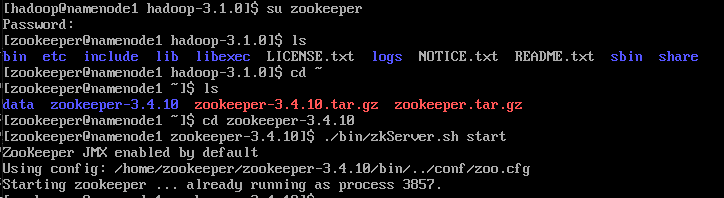
su hadoop
start-all.sh
(*혹시 정상적으로 zookeeper 및 하둡이 올라오지 않는 다면, 전부 다끄고 각 노드들도 저장이아닌 시스템 끄기이후 다시 올려보시길 바랍니다.)
1) tmp directory 만들기
*tmp directory는 Hive process의 중간 데이터 결과를 저장합니다.
1-1) hdfs dfs -mkdir /tmp
1-2) hdfs dfs -chmod g+w /tmp
쓰기 실행 권한 부여
1-3) hdfs dfs -ls /
추가되었는지 확인

2) warehouse directory 만들기
*warehose directory는 hive와 관련된 테이블을 저장합니다.
2-1) hdfs dfs -mkdir -p /user/hive/warehouse
2-2) hdfs dfs -chmod g+w /user/hive/warehouse
쓰기와 실행권한 부여
2-3) hdfs dfs -ls /user/hive

6. hive-site.xml 파일 설정하기
1) cd $HIVE_HOME/conf

2)cp hive-default.xml.template hive-site.xml
-hive-site.xml이라는 이름의 파일로 hive_default.xml.template 파일을 복사합니다.

3)nano hive-site.xml
-property로 시작되는 부분의 맨 위에 부분에 밑의 2개의 property를 추가시켜줍니다.
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
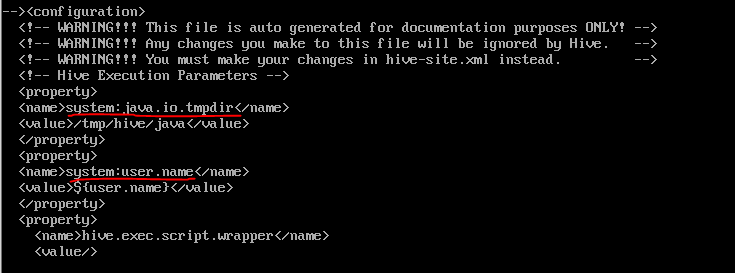
-ctrl+w 이후에 javax.jdo.option.ConnectionURL 를 입력해서 해당 property를 찾아가 다음과 같이 수정해줍니다.
value에
jdbc:derby:/home/hdoop/apache-hive3.1.2-bin/metastore_db;databaseName=metastore_db;create=true

또한 hive-site.xml에 이상한 특수기호가 들어가 에러가 걸립니다. 미리 제거해줍니다.
ctrl + w 로  을 찾아갑니다.
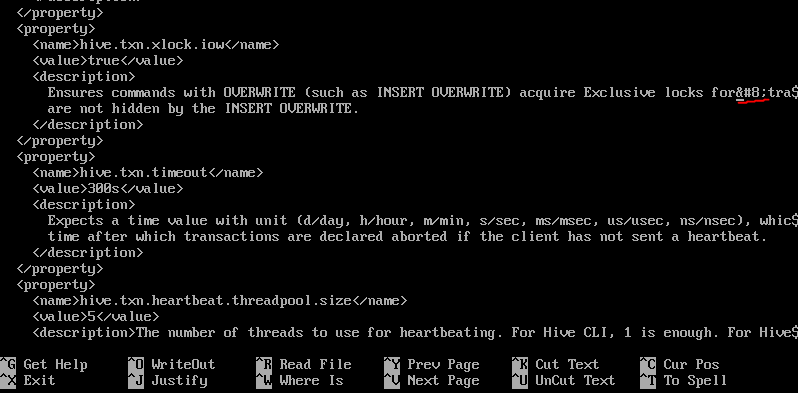
제거해줍니다.
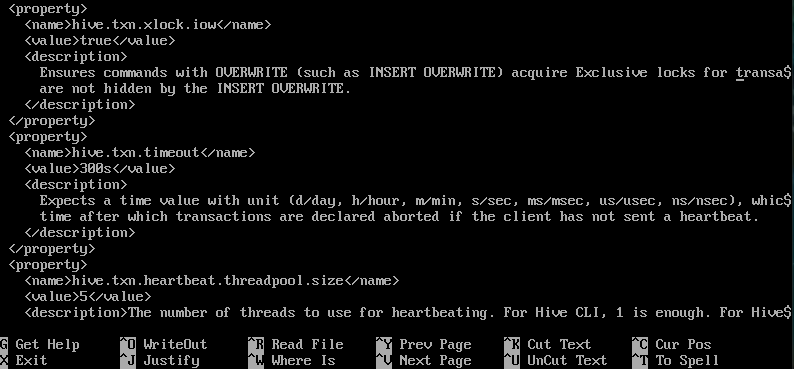
ctrl+x enter enter로 저장해줍니다.
7. derby database 시작하기
guava version 맞춰주기
1)ls $HIVE_HOME/lib
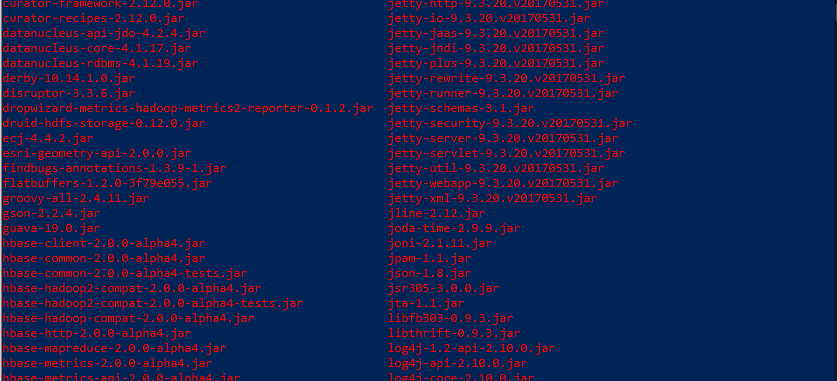
hive의 guava version은 19.0입니다.
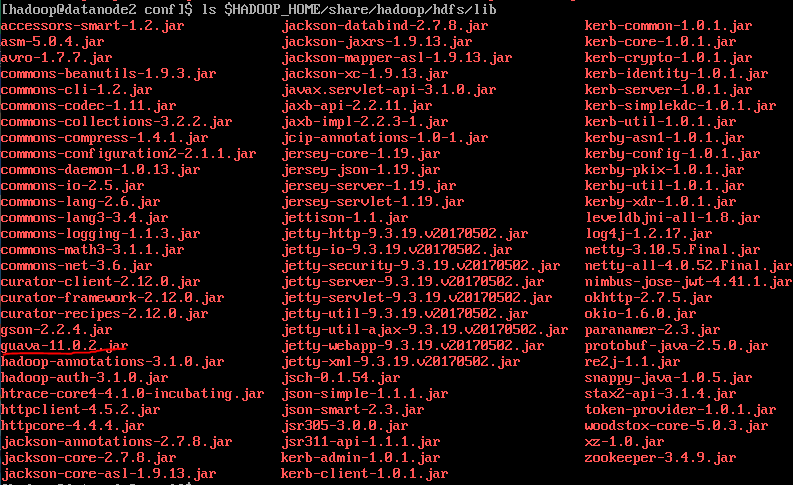
2)ls $HADOOP_HOME/share/hadoop/hdfs/lib
hadoop의 guava version은 11.0.2입니다.
3)rm $HIVE_HOME/lib/guava-19.0.jar
-hive의 guava를 지워줍니다.
4)rm $HADOOP_HOME/share/hadoop/hdfs/lib/guava-11.0.2.jar
-hadoop의 guava도 지워줍니다.
5)wget https://repo1.maven.org/maven2/com/google/guava/guava/27.0-jre/guava-27.0-jre.jar
-guava-27.0-jre버전을 다운받습니다.
6)mv guava-27.0-jre.jar $HADOOP_HOME/share/hadoop/hdfs/lib/
-guava를 하둡 폴더로 옮깁니다.
7)cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
-HADOOP폴더의 guava를 복사해줍니다.
DerbyDB 시작하기
$HIVE_HOME/bin/schematool -initSchema -dbType derby

위와 같은 문구가 뜬다면 성공입니다.
8.Hive Client 시작해보기
1) cd $HIVE_HOME/bin
2) hive
이것으로 hadoop cluster에 hive설치하기를 마치겠습니다. 다음 포스트에는 hive를 가지고 간단한 실습과 cluster에서 분산환경이 제대로 구축되어 있는지에 대해 확인해보겠습니다.



댓글