이번 포스트에는 이전 포스트에서 전부 다루지는 못했던, Hive의 성능에 관한 것들을 위주로 다루어 보겠습니다.
*Hive의 개념을 모르신다면 아래를 참조해주세요
2021.07.12 - [BigData] - [Hive] Hive란?(1) 개념, 구성요소, 등장배경, 버전
[Hive] Hive란?(1) 개념, 구성요소, 등장배경, 버전
1. Hive란? -하이브는 하둡 에코시스템 중에서 데이터를 모델링하고 프로세싱하는 경우 가장 많이 사용하는 데이터 웨어하우징용 솔루션입니다. -RDB의 데이터베이스, 테이블과 같은 형태로 HDFS에
spidyweb.tistory.com
*Hive의 메타스토어, Partition에 대해서 모르신다면 아래를 참조해주세요.
2021.06.27 - [BigData] - [Hive] (2) Hive MetaStore, Partition, msck, DDL문,location 정리
[Hive] (2) Hive MetaStore, Partition, msck, DDL문,location 정리
msck란? metastore check의 줄임말 1.MSCK REPAIR TABLE tablename -메타스토어에 하이브 파티션이 저장되어 있지 않을 때 말그대로 테이블을 수리하는(하이브 테이블의 파티션을 메타스토어에 저장하는)작업
spidyweb.tistory.com
1. 버켓팅(Bucketing)
- 버켓팅은 지정된 칼럼의 값을 해쉬 처리하고 지정한 수의 파일로 나누어 저장
- 조인에 사용되는 키로 버켓 칼럼생성 -> 소트 머지 버켓(SMB) 조인으로 처리되어 수행속도가 빨라짐
- Bucketing을 하면 Join을 하거나 샘플링 작업을 할 경우 성능향상
*파티션 vs 버켓팅
파티션: 데이터를 디렉토리로 나누어 저장하는 방식
버켓팅: 데이터를 파일별로 나누어 저장
*파티션이란? 파티션 조작법, 주의사항
https://spidyweb.tistory.com/235
[Hive] Hive MetaStore, Partition, msck, DDL문,location 정리
msck란? metastore check의 줄임말 1.MSCK REPAIR TABLE tablename -메타스토어에 하이브 파티션이 저장되어 있지 않을 때 말그대로 테이블을 수리하는(하이브 테이블의 파티션을 메타스토어에 저장하는)작업
spidyweb.tistory.com
*버켓팅 테이블 생성 기본문법
-- col2 를 기준으로 버켓팅 하여 20개의 파일에 저장
CREATE TABLE tbl1
(
col1 STRING,
col2 STRING
)
CLUSTERED BY (col2) INTO 20 BUCKETS-- col2 를 기준으로 버켓팅 하고, col1 기준으로 정렬하여 20개의 파일에 저장
CREATE TABLE tbl2
(
col1 STRING,
col2 STRING
) CLUSTERED BY (col2) SORTED BY (col1) INTO 20 BUCKETS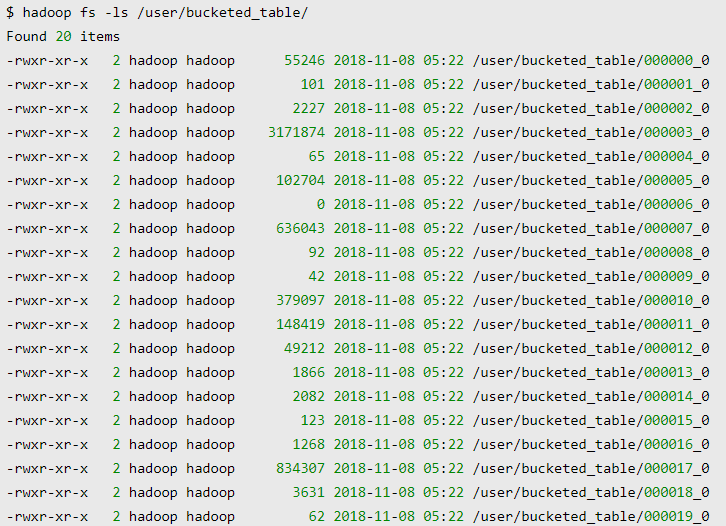
2. 스큐(Skew)
- 스큐란 '기울여졌다' 라는 뜻으로, 데이터가 편향되어 들어오는 경우를 말함
- Hive 데이터구조의 관점에서는 칼럼에 특정 데이터가 주로 들어오는 경우 분리하여 저장하는 기능
*스큐 vs 파티션
- 스큐는 파티션과 유사하지만 용도를 다르게 사용
파티션: 주로 데이터를 크게 구분하는 용도로 사용, 보통 일자별로 구분할 때 많이 사용
스큐: 칼럼의 데이터를 구분할 때 사용
- 스큐는 하나의 칼럼에 특정 데이터가 몰려서 생성될 때 사용
ex) alphabet 칼럼에 a~z까지의 데이터가 들어오는데, 주로 a, b로 데이터가 많이 들어 온다고 가정
파티션-> 26개의 파티션을 생성
스큐 -> a, b 와 나머지 총 3개의 디렉토리나 파일로 구별하여 저장 -> 네임노드의 관리 포인트가 줄어드는 효과
*스큐 테이블 생성 기본문법
CREATE TABLE tbl
(
col1 STRING,
col2 STRING
) SKEWED BY (col1) on ('value1', 'value2' ) [STORED as DIRECTORIES];
--STORED AS DIRECTORIES 옵션을 주지 않으면 디렉토리 구분없이 파일로 따로 저장
3. 서데(SerDe)
1) 서데(SerDe, Serializer/Deserialaizer)직렬화/역직렬화
- 직렬화(Serialization)란 object → data stream
- 즉 객체에 저장된 데이터를 스트림에 쓰기위해 연속적인 데이터를 변환하는것.
- 반대로 data stream으로부터 데이터를 읽어 object를 만드는것은 역직렬화(Deserialization)
- 직렬화를 사용하는 이유: 객체 자체를 영속적으로 보관할때 사용하는데 파일형태로 저장되어 네트워크를 통해 전송이 가능
- 직렬화/역직렬화 장점: 직렬화하면 다른 라이브러리나 추가적인 환경구성이 필요없다 또한 역직렬화 할 경우 기존 객체처럼 사용이 가능
2) SerDe의 역할
- 하이브가 데이터를 해석하는 방법을 제공
- 하이브는 서데와 파일 포맷을 이용하여 데이터를 읽고, 쓸 수 있음
- 하이브는 파일을 읽을 때 파일포맷(FileFormat)을 이용하고, 디시리얼라이저(Deserializer)를 이용하여 원천 데이터를 테이블 포맷에 맞는 로우 데이터로 변환
- 파일을 쓸때는 로우 데이터를 시리얼라이저(Serializer)를 이용하여 키, 밸류 형태로 변경하고 파일포맷을 이용하여 저장 위치에 씀
3) SerDe 과정
서데는 doDeserialize(), doSerialize() 를 구현하여 각각의 경우를 처리하게 됨
- HDFS files --> InputFileFormat --> [key, value] --> Deserializer --> Row object
- Row object --> Serializer --> [key, value] --> OutputFileFormat --> HDFS files
4) SerDe 종류
하이브에서 제공하는 기본 서데는 7가지(Avro, ORC, RegEx, Thrift, Parquet, CSV, JsonSerDe),
각 서데는 STORED AS 에 지정하는 파일의 포맷에 따라 자동으로 선택
Avro, ORC, Parquet 은 서데와 인풋, 아웃풋 포맷이 설정
나머지는 기본 LazySimpleSerDe와 파일에 따른 인풋, 아웃풋 포맷이 설정
테이블에 설정되는 서데는 desc formatted 명령으로 확인이 가능
4. Join Type(Map join, Shuffle Join, Sort-Merge-Bucket Join)
셔플조인 = 머지조인
맵조인 = 브로드캐스트 조인
sort-merge-bucket join = 그대로
1) Shuffle Join(Merge Join)
- 셔플(Shuffle) 단계에서 조인을 처리
- 두 개의 테이블을 조인할 때 각 테이블을 맵(Map) 단계에서 읽고, 파티션 키를 조인 키로 설정하여 셔플 단계에서 조인 키를 기준으로 리듀서로 데이터가 이동되고 테이블을 조인
- 특징1: 어떤형태의 데이터 크기와 구성에도 사용 가능
- 특징2: 가장 자원을 많이 사용하고 느린 조인 방식
2) Map Join(Broadcast Join)
- 두 개의 테이블을 조인할 때 하나의 테이블이 메모리에 로드 되어 처리
- 하나의 테이블이 메모리에 올라갈 수 있을 정도로 작을 때 맵조인을 적용
- hive.auto.convert.join이 true일 때 적용
- hive.auto.convert.join.noconditionaltask.size이 메모리에 올릴 테이블의 기본 사이즈로 10MB으로 설정
- 특징1: 셔플 조인에 비하여 빠른 속도로 처리할 수 있음
- 특징2: 테이블이 메모리에 올라갈 수 있는 크기여야 함
3) SMB Join
- 조인 테이블이 버켓팅 되어 있을 때 사용
- 버켓팅된 키의 정보를 이용하여 빠르게 조인을 처리
- 어떤 크기의 테이블에서도 가장 빠른 속도로 조인을 처리
- 특징1: 테이블이 버켓팅이 되어 있어야 함
참조:
https://dataonair.or.kr/db-tech-reference/d-guide/data-practical/?mod=document&uid=404
하이브
맵리듀스의 대안 하이브와 피그 맵리듀스의 복잡성 하이브는 하둡에서 맵리듀스를 직접 돌리는 대신, 사용자가 SQL(Simple Query Language)로 쿼리를 작성하면 이것을 자동으로 맵리듀스 작업으로 변
dataonair.or.kr
'BigData > Hive' 카테고리의 다른 글
| [HIVE] (Hive 실습)Hadoop ETL with (HiveQL)HQL파일,HQL파일로 hadoop에 job제출하기 (0) | 2021.11.08 |
|---|---|
| [BigData] 완전 분산 하둡 클러스터(hadoop cluster)(4개 노드) 에 "Hive" 설치 및 실습 하기 (0) | 2021.10.11 |
| [Hive] Hive-site.xml (2) 주요 property 소개 (0) | 2021.07.13 |
| [Hive] virtual box linux [ubuntu 18.04]에 Hive Metastore PostgreSQL로 설정하기(변경하기) (2) | 2021.07.13 |
| [Hive] Hive란?(1) 개념, 구성요소, 등장배경, 버전 (0) | 2021.07.12 |



댓글