이번 포스트에는 standalone(pseudo distributed hadoop cluster)에 HQL파일을 생성하여 job을 제출하는 실습을 해보겠습니다.
하둡 및 하이브를 설치하지 못하신 분은 아래의 링크를 참조해주세요.
2021.04.26 - [BigData] - [Hadoop] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 1.virtualbox에 ubuntu 설치하기
[Hadoop] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 1.virtualbox에 ubuntu 설치하기
1.virtual box를 다운로드한다. www.virtualbox.org/wiki/Downloads Downloads – Oracle VM VirtualBox Download VirtualBox Here you will find links to VirtualBox binaries and its source code. VirtualBox..
spidyweb.tistory.com
[Hive] virtual box linux [ubuntu 18.04]에 하둡 설치,다운로드 4.ubuntu 에 Hive(하이브) 다운로드
이번 포스트에는 Hive를 설치해 보겠습니다. vritualbox 설치,ubuntu설치, ssh통신, hadoop 설치가 완료 되지 않으신 분은 아래의 URL을 참고하여 완료해 주세요. 1.virtualbox 설치 및 ubuntu 설치 spidyweb.tist..
spidyweb.tistory.com
실습용 데이터
https://data.cityofnewyork.us/Public-Safety/Motor-Vehicle-Collisions-Crashes/h9gi-nx95
Motor Vehicle Collisions - Crashes | NYC Open Data
data.cityofnewyork.us
뉴욕시티에서 일어난 자동차,오토바이 등 탈 것에 의한 충돌횟수에 대한 데이터
실습 시나리오
1. local에 newyork city crash tsv파일을 다운로드 한다.
2-1. hdfs에 source data가 들어갈 directory를 생성한다.
2-2. local에 있는 tsv파일을 2-1번에서 생성한 directory에 put한다.
3. HQL 파일을 작성한다.
- source table이 있으면 source table을 DROP
- source table이 없다면 source table을 CREATE
- target table이 있다면 target table을 DROP
- target table이 없다면 target table을 CREATE
- source table로 부터 target table로 INSERT OVERWRITE
4. HQL을 실행 및 결과 확인
조건
source table은 tsv파일을 읽는 textfile format의 테이블이다.
target table은 orc file format의 테이블이다.
HQL파일은 멱등성(여러번 실행해도 같은 결과가 나오게끔)이 가능하도록 구성한다.
1. local에 tsv 파일 다운로드하기
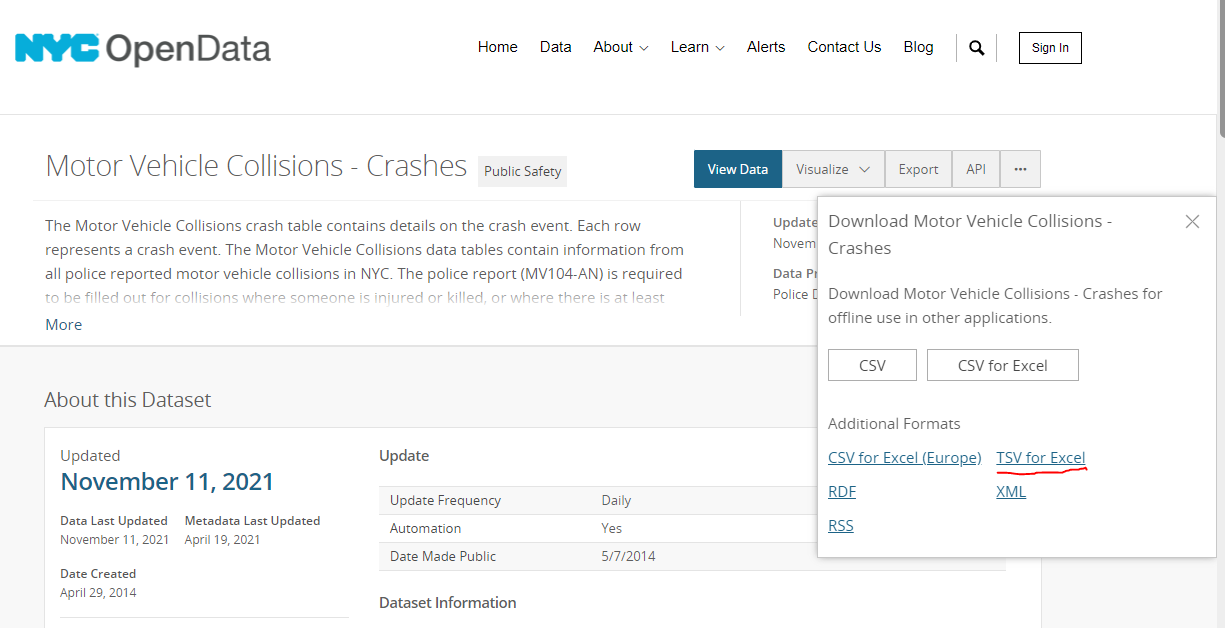
위의 사진에서 TSV for excel을 우클릭 후 링크 주소 복사를 통해 URL을 복사합니다.
1) 하둡 계정의 root디렉토리에서 wget url
wget이 없다면 wget을 다운 받아야합니다.
wget https://data.cityofnewyork.us/api/views/h9gi-nx95/rows.tsv?accessType=DOWNLOAD&bom=true

2) 생성된 파일 확인 및 이름변경

mv rows.tsv?accessType=DOWNLOAD NYCRASH.tsv

2-1. HDFS 디렉토리 생성
1) 하둡을 실행
start-all.sh
2) hdfs에 NY_CRASH 디렉토리 생성
hdfs dfs -mkdir /user/hive/NY_CRASH
3) 생성된 NY_CRASH 디렉토리 확인
hdfs dfs -ls /user/hive

2-2. HDFS 디렉토리에 tsv파일 PUT
1) PUT
hdfs dfs -put NYCRASH.tsv /user/hive/NY_CRASH
2) 확인하기
hdfs dfs -ls /user/hive/NY_CRASH

3. HQL 파일 작성하기
1) ny_crash.hql 파일 생성 및 편집하기
touch ny_crash.hql
nano ny_crash.hql (nano가 안되시면 다운받아야합니다.)
아래의 hql내용을 작성하여 ctrl+x y enter로 저장

2) target 테이블로 넣고자 하는 데이터
구하고자 하는 데이터
00:00~06:00 시간내에 맨해튼에서 날짜별, 시간별 부상자가 가장 많거나, 사망자가 가장 많은 데이터 구하기
CRASH_DATE
CRASH_TIME
NUMBER_OF_PERSONS_INJURED
NUMBER_OF_PERSONS_KILLED
컬럼을 사용한다.
처리방법
CRASH_DATE 는 MM/dd/yyyy형태, CRASH_TIME은 H:mm 혹은 HH:mm형태
따라서,
1) 오름차순 정렬을 위한, CRASH_DATE를 yyyy/MM/dd형태로 바꾸기위해 unix_timestamp, from_unixtime을 사용
2) 조건으로 00:00과 06:00사이에 있는 데이터를 대상으로 하기때문에, CRASH_TIME을 HH:mm형태로 만들기 위해 LPAD를 사용
3) BOROUGH의 값이 "MANHATTAN"인 것만 추출
4)날짜별, 시간별 부상자수와 사망 수를 구하기
5)날짜별 부상자수를 row_number를 통해 내림차순 등수 구하기, 사망자수를 row_number를 통해 내림차순 등수 구하기
6)날짜별 부상자수가 1위이거나, 사망자수가 1위인 조건을 걸어 날짜,시간,부상자 수, 사망자 수를 구하기
7)날짜, 시간순으로 오름차순 정렬
3) ny_crash.hql 내용
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
--NYCRASH.hql
DROP TABLE IF EXISTS NY_CRASH;
--NY_CRASH 테이블이 있다면 삭제(멱등성을 위해 존재)
CREATE EXTERNAL TABLE IF NOT EXISTS NY_CRASH (
CRASH_DATE STRING,
CRASH_TIME STRING,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE DOUBLE,
LONGITUDE DOUBLE,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
NUMBER_OF_PERSONS_INJURED INT,
NUMBER_OF_PERSONS_KILLED INT,
NUMBER_OF_PEDESTRIANS_INJURED INT,
NUMBER_OF_PEDESTRIANS_KILLED INT,
NUMBER_OF_CYCLIST_INJURED INT,
NUMBER_OF_CYCLIST_KILLED INT,
NUMBER_OF_MOTORIST_INJURED INT,
NUMBER_OF_MOTORIST_KILLED INT,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
CONTRIBUTING_FACTOR_VEHICLE_3 STRING,
CONTRIBUTING_FACTOR_VEHICLE_4 STRING,
CONTRIBUTING_FACTOR_VEHICLE_5 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING,
VEHICLE_TYPE_CODE_3 STRING,
VEHICLE_TYPE_CODE_4 STRING,
VEHICLE_TYPE_CODE_5 STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION 'hdfs://127.0.0.1:9000/user/hive/NY_CRASH'
tblproperties ("skip.header.line.count"="1");
--source table인 ny_crash 테이블 생성
-- tsv파일은 \t단위로 구분하여 textfile로 읽는다. 데이터파일의 첫번째 row는 컬럼정보이므로 header를 설정
-- csv파일로 읽지않는 이유는 한 개의 컬럼 내에 값이 ,이 포함되어 있어서 ,을 구분자로 쓰면 값이 안맞는다.
DROP TABLE IF EXISTS NY_CRASH_MAX_INJURED_KILLED;
--NY_CRASH_MAX_INJURED_KILLED이 존재하면 삭제(멱등성을 위해 존재)
CREATE EXTERNAL TABLE IF NOT EXISTS NY_CRASH_MAX_INJURED_KILLED (
CRASH_DATE_FORMATTED STRING,
CRASH_TIME_HH STRING,
TOTAL_INJURED INT,
TOTAL_KILLED INT
)
STORED AS ORC
LOCATION 'hdfs://127.0.0.1:9000/user/hive/NY_CRASH/NY_CRASH_MAX_INJURED_KILLED'
;
--target table인 ny_crash_max_injured_killed 테이블 생성
INSERT OVERWRITE TABLE NY_CRASH_MAX_INJURED_KILLED
SELECT C.CRASH_DATE_FORMATTED
,C.CRASH_TIME_HH
,C.TOTAL_INJURED
,C.TOTAL_KILLED
FROM (
SELECT B.*
,ROW_NUMBER() OVER(PARTITION BY B.CRASH_DATE_FORMATTED ORDER BY TOTAL_INJURED DESC) AS MAX_INJURED__DESC_RN
,ROW_NUMBER() OVER(PARTITION BY B.CRASH_DATE_FORMATTED ORDER BY TOTAL_KILLED DESC) AS MAX_KILLED__DESC_RN
FROM (
SELECT A.CRASH_DATE_FORMATTED
,A.CRASH_TIME_HH
,MAX(A.NUMBER_OF_PERSONS_INJURED) AS TOTAL_INJURED
,MAX(A.NUMBER_OF_PERSONS_KILLED) AS TOTAL_KILLED
FROM (
SELECT A.*
,from_unixtime(unix_timestamp(CRASH_DATE,"MM/dd/yyyy"),"yyyy/MM/dd") as CRASH_DATE_FORMATTED
,LPAD(CRASH_TIME,5,"0") as CRASH_TIME_HH
FROM ny_crash A
) A
WHERE ((A.CRASH_TIME_HH BETWEEN "00:00" AND "06:00")
AND (A.BOROUGH = "MANHATTAN"))
GROUP BY A.CRASH_DATE_FORMATTED
,A.CRASH_TIME_HH
) B
) C
WHERE ((C.MAX_INJURED__DESC_RN <= 1)
OR (C.MAX_KILLED__DESC_RN <= 1))
ORDER BY C.CRASH_DATE_FORMATTED
,C.CRASH_TIME_HH
;
--source table -> target table
|
cs |
4. HQL 실행 및 결과확인
1) HQL 실행하기
hive -f hql파일이 있는 디렉토리/hql파일명.hql
hive -f /home/hdoop/ny_crash.hql

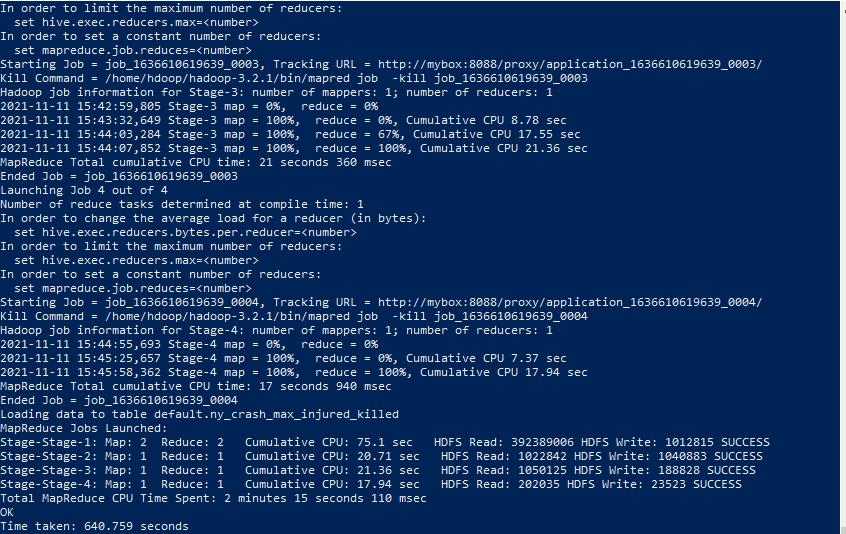
2) NY_CRASH_MAX_INJURED_KILLED 디렉토리 생성 확인
hdfs dfs -ls /user/hive/NY_CRASH/

3) NY_CRASH_MAX_INJURED_KILLED 데이터가 쓰여졌는지 확인
hdfs dfs -ls /user/hive/NY_CRASH/NY_CRASH_MAX_INJURED_KILLED/

4) hive 접속 및 테이블 조회, 데이터 조회
hive
show create table ny_crash;
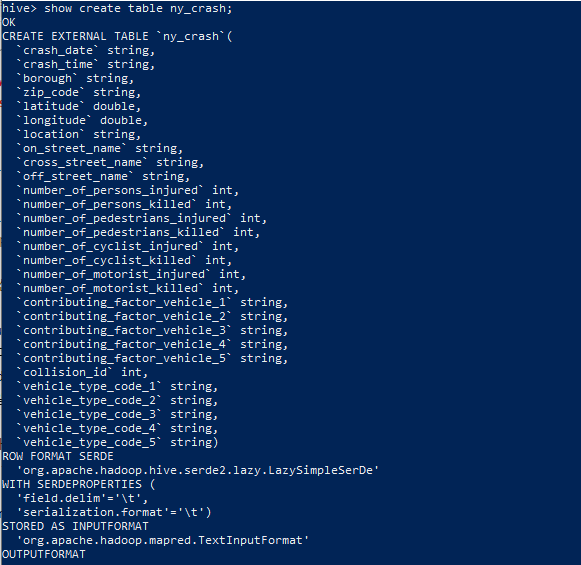
show create table ny_crash_max_injured_killed;

select * from ny_crash_max_injured_killed;

알게 된 것 정리하기
1. 테이블 생성시, 컬럼 이름 띄어쓰기를 허용하는지? no
2. STORED AS CSV는 없고, STORED AS TEXTFILE + FIELDS TERMINATED BY ','로 handle
3.header 옵션은 tblproperties ("skip.header.line.count"="1");
4.테이블 생성시 파티션은 파티션 지정시 파티션컬럼으로써 생성되며, 기존의 컬럼으로 파티션을 지정할 수 없다.
-select 를 할 시 파티션이 컬럼처럼 나옴
-create columnname datatype 이 아닌 밑에 부분에 PARTITIONED BY (columnname datatype)으로 생성
5. stored as는 input format, output format, serde 세가지를 명시
6. stored as 는 input out put 따로 지정이 가능하다
7. 당연한 소리지만, csv파일 값에 , 문자가 있으면 값이 의도한대로 나오지 않는다. ->tsv로 하자 terminated by '\t'
8. (이건 spark로도 작성하다 적어본 번외)
row_number에서 동일값의 경우 hive와 spark가 1등을 주는 기준이 다른데,
2개의 row_number를 써서 <= 1 인 기준을 얻어내는 경우에
spark는 1등인 값에 대해 1등을 같이 주는 경향이 있는가하면
hive는 1등 2등, 2등 1등 처럼 주기 때문에 값의 개수 차이가 날 수 있다.
(실제로 target table 갯수가 각각 3300, 5200 정도로 차이가 났다)
9. partition 컬럼을 생성하게되면 맨마지막 컬럼으로 인식된다.
10. String값 데이터의 스키마를 int로 주면 전부 NULL로 나오게된다.
11. partition을 날짜별로 줄 수 있지만, 날짜로 하게되면 3000몇개의 디렉토리가 생겨서 작업시 성능이 떨어진다. 원래는 날짜별로 파티션하면 조회, 관리에 있어서 좋은 성능을 나타내지만, partition별 들어가는 데이터 수가 적어 큰 효율은 나오지않는다. -> non-partitioned data로 변경
12.partition by를 통해 생성된 column은 가상 컬럼이다.
이것으로 간단한 예제를 통한 HQL파일로 하둡에 job제출하기를 실습했습니다.
하둡 클러스터에서 hive job제출하는 것을 확인하시려면 아래의 링크를 참조해주세요.
2021.11.23 - [BigData] - [Hive] Hive on Hadoop cluster 실습 + yarn ui 확인하기
'BigData > Hive' 카테고리의 다른 글
| [Hive,Spark] Hive와 SparkSQL의 호환성 (0) | 2021.11.30 |
|---|---|
| [Hive] Hive on Hadoop cluster 실습 + yarn ui 확인하기 (0) | 2021.11.23 |
| [BigData] 완전 분산 하둡 클러스터(hadoop cluster)(4개 노드) 에 "Hive" 설치 및 실습 하기 (0) | 2021.10.11 |
| [Hive] Hive의 성능(테이블) (3) bucketing(버켓팅),skew(스큐), serde(서데), join type(맵 조인, 셔플 조인, 정렬-병합 조인)정리 (0) | 2021.10.05 |
| [Hive] Hive-site.xml (2) 주요 property 소개 (0) | 2021.07.13 |



댓글